








Пришлось разбираться с распознаванием текста в Linux. Точнее - с утилитой cuneiform. А заодно осознать еще одно преимущество СПО.
[spoiler]Собственно говоря, вся работа свелась к установке утилиты командой urpmi cuneiform -a. Плюс беглое чтение пары заметок, ссылки на которые мне подсказал Google. Через буквально пять минут результат был получен.
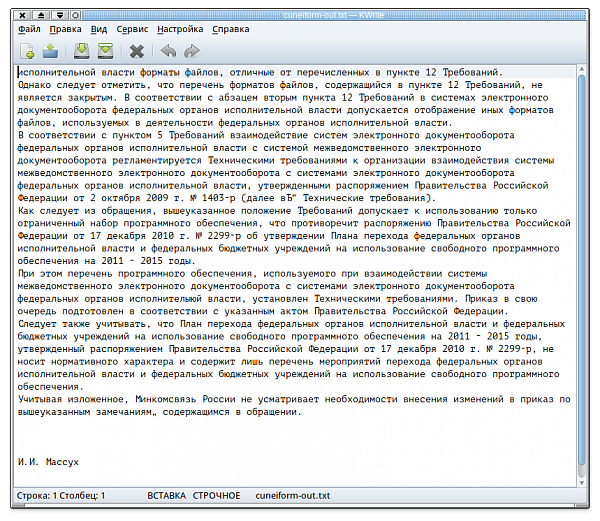
Лично я счел его вполне удовлетворительным. Возможно, серьезные знатоки процесса со мной не согласятся, но прошу учесть время, затраченное мной на решение задачи.
Хотелось бы узнать мнение знатоков проприетарного ПО на этот счет. Можно ли получить такой же результат за пять минут и не потратив при этом ни копейки денег? Я почему-то в этом сильно сомневаюсь.
Кстати, напоминаю, что прямо сейчас на странице www.linuxcenter.ru/RH2012 идет прямая трансляция с семинара "Обзор Red Hat Enterprise Linux 6". Рекомендую.






Впрочем, это вообще характерно для России. Где можно сказать два слова, там приходится писать кучу бумаг.
Заказчики это делают постоянно - никто худого вроде пока не говорил.