








[spoiler]Конечно, Hadoop -- не универсальная панацея для BI. Поставщик корпоративного Hadoop-дистрибутива Cloudera позиционирует Hadoop как корпоративный хаб для параллельной обработки данных, хорошо подходящий для гибкой, «поисковой» аналитики, а вот для «стандартных» запросов по табличным данным по-прежнему останутся на плаву типовые хранилища данных. Но важно, что Hadoop отлично масштабируется, поддерживает разные типы рабочих нагрузок и произвольные форматы и структуры данных, недорога в плане потребляемых ресурсов, и быстра.
Однако эксперты предупреждают, что явный общемировой тренд -- отход от классической ИТ-инфраструктуры, где аналитика реализована низкоуровневыми механизмами, к бизнес-сервисам, управляемым данными. Спрос на такие решения очень высок, и Hadoop, как уже отмечалось, пока его практически не удовлетворяет -- высокий порог входа, приличная общая сложность. Поэтому оперативно появляются качественные альтернативы.
Вот, например, Spark http://spark.incubator.apache.org/ свободный проект фонда Apache, по которому на прошлой неделе прошёл первый общемировой саммит в Сан-Франциско. На нем были замечены выступающие из Adobe, Intel, Cloudera, Yahoo, UC Berkeley (исходно Spark был создан в этом университете)...
Мероприятие было организовано стартапом Databricks, который получил $14 млн. инвестиций и уже договорился с Cloudera о совместных проектах.
Spark -- это аналитический кластерный движок, во многом совместимый с Hadoop, но при этом работает в сто раз(!) быстрее нежели MapReduce, и насчитывает самое большое после Hadoop коммьюнити разработчиков в сфере Больших данных. При этом акцент делается не только на обеспечении высокой скорости работы, но и на скоростной разработке прикладных систем на базе Spark, чем Hadoop пока никак похвастать не может.
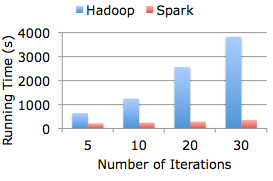
Таким образом, если есть бюджеты на долгосрочные «тяжёлые» аналитические ИТ-проекты, лучше сразу въезжать в Hadoop. А если денег поменьше, но все равно реализовывать серьёзные BI/BD-системы очень желательно, можно поэкспериментировать со Spark.





