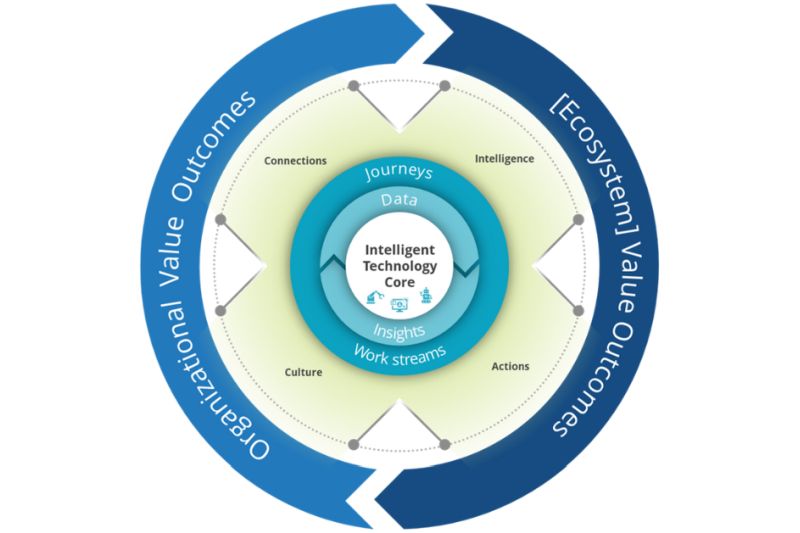


Эшли Кейл, вице-президент по продажам компании IBML в регионе EMEA и APAC, рассказывает на портале Information Age о том, как платформы искусственного интеллекта могут радикально изменить, улучшить и автоматизировать процессы обработки документов.
Быстрое развитие самообучающихся платформ ИИ, которые автоматически решают сложные задачи, позволяет информационным и бизнес-менеджерам быстро получать реальные инсайты из документов, независимо от языка, используемого файлового формата, а также от того, содержат ли документы печатный или рукописный текст, или и то, и другое. Это радикально изменит то, как организации справляются с распознаванием и классификацией миллионов документов, а затем извлекают и проверяют информацию без какого-либо ручного вмешательства, повышая тем самым производительность, точность и экономя деньги.
Существующие технологии распознавания символов имеют свои ограничения
В традиционные технологии распознавания, такие как оптическое распознавание символов (OCR), интеллектуальное распознавание символов (ICR) и интеллектуальное распознавание слов, используемые для анализа содержания документов и повышения уровня автоматизации, были вложены огромные средства. Эта область по-прежнему активно развивается. По оценкам Grand View Research, ожидается, что в 2025 г. мировой рынок OCR достигнет 13,38 млрд. долл., увеличившись на 13,7% по сравнению с
Несмотря на это, возможности этих технологий остаются ограниченными. Многие движки ICR/OCR с трудом справляются с обработкой всего разнообразия документов — структурированных, полуструктурированных и неструктурированных данных — наряду с рукописным почерком, историческими и старыми документами, особенно если разборчивость текста оставляет желать лучшего. Ситуация усугубляется при больших объемах. И ни один традиционный механизм ICR/OCR не может беспрепятственно обрабатывать различные языки — переходя от английского к китайскому, немецкому и т. д.
При такой вариативности скорость правильного распознавания заметно снижается — сегодня все еще трудно добиться точности более
Но обещание — а теперь и реальность — ИИ заключается в том, что эти проблемы также решаются с помощью мощных когнитивных систем.
Решения на базе ИИ для обработки документов уже доступны
Используя нейронные сети, платформы для обработки документов на основе ИИ обеспечивают скачок вперед по сравнению с традиционными технологиями распознавания. Вначале система «обучается», чтобы создать консолидированную базу знаний о конкретном (разговорном) языке, форме и/или типе документа. На жаргоне ИИ это называется «выводом» (inference). Затем эта база знаний расширяется и увеличивается по мере наполнения системы все большим количеством информации, и система самообучается — она становится способна распознавать документы и их содержание по мере их поступления.
Это достигается благодаря использованию обратной связи — «контура переобучения» (контролируемое обучение под наблюдением человека), когда ошибки в системе исправляются по мере их возникновения, чтобы выводы (и метаданные, лежащие в их основе) обновлялись, обучались и могли самостоятельно справляться с подобными ситуациями при их следующем появлении.
Это не отличается от того, как работает человеческий мозг и как дети учат язык. Другими словами, чем больше дети говорят, делают ошибки и их исправляют, тем лучше они говорят. То же самое происходит и с ИИ, когда он применяется к анализу и обработке документов. Выводы становятся все более грамотными и точными.
Системы на основе ИИ можно обучить автоматическому распознаванию конкретных форм, анализу конкретного содержания и его расположению на странице, а затем преобразованию рукописного текста в стандартные электронные форматы, такие как PDF или JavaScript Object Notation (JSON), для задач анализа или обеспечения рабочего процесса, с проверкой и валидацией.
Это также может делаться на уровне полей — для извлечения пар ключ- значение (key-value). Например, общее поле в форме для «имени» или «возраста» — ключ, а «мистер Джон Смит» и «50» — конкретные значения. Или в счете-фактуре ключами являются приобретенные товары, а значениями — цены, по которым за их купили. Конечно, это могут делать и системы ICR/OCR, но они с трудом распознают рукописный текст и требуют сложных алгоритмов для поиска полей.
Выгоды здесь очевидны. Правительствам, медицинским учреждениям, банкам и страховым компаниям приходится обрабатывать огромное количество рукописных форм с идентичными форматами для различных целей, таких как анкеты, заявления, личные кредиты, ипотечные кредиты или претензии. Извлечение рукописной информации и преобразование ее в цифровой формат без участия человека сокращает количество ручных ошибок, снижает затраты, позволяет анализировать большие данные и значительно ускоряет процесс обработки.
Скорость такой обработки на основе ИИ впечатляет. На одном сервере можно обрабатывать до 50 тыс. страниц в час, а при потребности в большей вычислительной мощности можно развернуть более крупные системы и использовать облачные технологии.
Для анализа могут быть загружены различные типовые файлы, такие как обычный текст, PDF, TIFF, JPEG, GIF, PPM, PNG и т. д., после чего несколько нейронных сетей считывают текст и классифицируют его тип — будь то рукописный почерк или машинная печать — с применением «нечеткого поиска», помогающего процессу преобразования текста в цифровой формат. А ведущие в своем классе системы ИИ, помимо работы с бумажными документами, способны также обрабатывать изображения, видео и аудио. Другими словами, они не зависят от содержания и могут работать с любым исходным контентом.
ИИ на практике
Это реальные вещи. Одна немецкая страховая компания в течение следующих шести лет планирует перевести весь процесс рассмотрения претензий под управление системы на базе ИИ. Чтобы претензии в пределах определенной суммы обрабатывались автоматически на основе информации, извлеченной из формы, оцененной и утвержденной без какого-либо участия человека. Это будет достигаться благодаря тому, что ИИ-решение будет автоматически проверять имя, адрес, страховой номер и другие ключевые детали конкретного инцидента, каждый раз правильно собирая все данные из формы.
Когда речь идет об обработке документов, действия ИИ впечатляют. То, как машина «читает» отсканированный бумажный документ и извлекает из него данные, — это просто волшебство.
Одним из экономических последствий пандемии Covid-19 является то, что многие компании захотят повысить эффективность, одновременно пытаясь сэкономить деньги. Те, у кого обработка бланков и другой документации требует значительных затрат и операционных издержек, испытывают чувство беспокойства или даже тревоги по поводу того, как это сделать.
Но не стоит паниковать. ИИ уже достаточно развит, чтобы стать реальным и надежным вариантом для компаний, которым приходится иметь дело с миллионами бумажных документов.