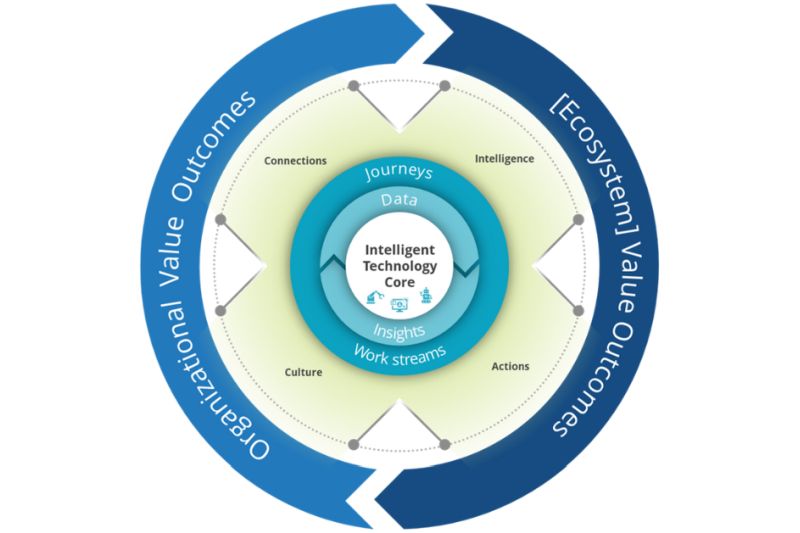




Разрывы в качестве данных, особенно из-за проблем с цепочками поставок во время пандемии, становятся серьезным препятствием для планирования эффективных моделей машинного обучения, пишет на портале InformationWeek Пьер Дюбуа, основатель консалтинговой компании Zimana.
Когда речь идет о погоде, мы относимся к барометрам как к хорошим индикаторам изменения давления, которые предсказывают возможный дождь. Мы верим в надежность этих показателей, поскольку на входную информацию не влияет деятельность человека.
То же самое нельзя сказать о поисковых системах. Они надежны в плане обнаружения информативных медиа. Но по мере того как растет обсуждение случаев дезинформации и ошибок в машинном обучении, технологи должны задуматься о том, как пробелы в запросах поисковых систем влияют на наши алгоритмы и, в конечном счете, на наш мир. Пустоты данных представляют собой такие пробелы.
Пробелы данных — это разница между качеством информации, которую люди получают в запросе, и доступной авторитетной информацией, использованной в запросе. Они являются побочным продуктом того, как развивалась доставка информации в Интернете. Заполнение информационных пробелов обычно преследовало коммерческие цели, но со временем Интернет включил в себя больше непроверенных источников из числа некоммерческих медиа и в результате распространяет дезинформацию на социальные и политические темы.
Майкл Голебиевски и Дана Бойд из Microsoft впервые ввели в обиход словосочетание «пробел данных» в докладе 2018 г. «Data Voids: Where Missing Data Can Easily Be Exploited».
Чтобы лучше представить, о чем идет речь, вспомните теорию «Длинного хвоста» — статистическую концепцию, которую Крис Андерсон пропагандировал в качестве нового подхода к бизнесу. Теория, согласно которой меньшие объемы товаров могут быть проданы более выгодно онлайн, провозгласила Интернет в качестве платформы для торговли новыми продуктами и услугами. Но со временем мир принял Интернет как ресурс не только для розничной торговли. «Длинный хвост» расширился на некоммерческие темы, которые, возможно, не пользуются большим спросом и не обновляются часто, но при этом проникли в спекулятивные идеи, рассматриваемые как абсолютная истина ничего не подозревающими гражданами. Это влияние особенно ощущается в социальных и политических темах.
Поскольку люди полагаются на поиск, пробелы в данных открывают двери для манипулирования людьми по многим общественным вопросам. Запросы, которые дают слишком мало информации или не дают никаких результатов, позволяют манипуляторам заполнять эти пробелы собственной информацией. Манипуляторы создают экосистему вокруг новых стратегических терминов, связанных с запросами с низким объемом поиска. Затем они пытаются протащить эти термины в основные СМИ. В 2019 г. Бойд привела в качестве примера политконсультанта Фрэнка Ланца, который научил членов Республиканской партии вставлять в новости стратегические термины, чтобы журналисты непреднамеренно их распространяли и усиливали желаемое сообщение, формируя общественное принятие этой информации в ущерб истине.
Использование стратегических терминов усугубляет распространение дезинформации в Интернете. Связанные с социальными и политическими проблемами темы, содержащие пробелы в данных, являются подходящей мишенью для манипуляций. Теории заговора процветают на части информации, взятой из текущих новостей или общих знаний. Люди делятся этой информацией через посты и мемы. Поскольку многие субъекты используют Интернет для спекуляций, эти усилия могут проникнуть в информацию других культурных и медийных институтов. Хотя дебаты могут помочь в борьбе с дезинформацией в масштабе один на один, они не могут противостоять увеличению масштабов преследования, манипуляций или, что еще хуже, массовых общественных действий. Нападение на Капитолий 6 января является примером того, как сообщения могут ввести общественность в заблуждение.
Влияние неполноты данных может выходить за рамки вводящих в заблуждение результатов поиска. Данные социальных сетей наряду с данными поиска часто включаются в семантический анализ, который опирается на машинное обучение для поддержки решений общественных проблем, например, психического здоровья. Так, профессор Луо из Университета Рочестера провел исследование, посвященное тому, как психическое здоровье во время пандемии COVID-19 отражается через твиты в Twitter. Изучение анализа настроений на широком массиве текстов помогает бороться с политикой, основанной на обобщении данных, которая имеет такое же леденящее душу воздействие, как и законодательство, вводящее дискриминацию в обществе или инициирующее гражданские проекты, усиливающие, например, джентрификацию.
В организациях операционные группы должны внимательно следить за тем, как данные из онлайн-источников, таких как поиск и социальные сети, оцениваются на соответствие их спецификациям в модели данных. Команды должны проводить алгоритмический аудит для проверки достоверности данных. Они могут делать это с помощью наблюдаемости — процессов, призванных обеспечить глубокое понимание на разных этапах цикла разработки модели. При этом создаются предупреждения, которые защищают последующие системы от дезинформации, вызванной пустотами в данных. Это также позволит настроить рабочий процесс команды для устранения пробелов в данных, которые могут сбить чатбота с пути, например, как в случае печально известного манипулирования текстом на расовой почве чатботом Tay от Microsoft.
В наши дни машинного обучения разрывы в качестве данных являются серьезной проблемой для любого предприятия. Мы уже живем в мире, где экономика управляются данными. Технологии часто подсказывают нам решения еще до того, как мы в них будем нуждаться, облегчая нашу жизнь. Но руководство, основанное на манипулировании информацией из-за пробелов в данных, открывает дверь для ошибочного технологического выбора, неверных решений и заблуждений людей. Манипуляции и дезинформация, вызванные пробелами в данных, обрушиваются с всепроникающей силой, как любой другой разрушительный шторм.