









Для начала хочу отметить, что речь не идет о поиске изображения, похожего на некий исходник, как это реализовано, например, в браузерном плагине с говорящим названием "Кто украл мои картинки?". И более того, пока даже не о поиске, а об автоматической генерации словесного описания изображения. Как признают авторы этой работы, многое уже было сделано до них, но с другими целями. Они решили объединить в своем решении технологии машинного зрения (computer vision) и общения с машиной на естественном языке (natural language processing). В частности, была применена нейронная сеть Recurrent Neural Network (RNN), достигшая хороших результатов в машинном переводе: с ее помощью строится некое векторное представление фразы на одном языке (скажем, французском), после чего другая RNN-сеть восстанавливает эту фразу на другом языке (допустим, немецком). А что, если подать на вход второй RNN-сети результат работы еще одной нейронной сети - Convolutional Neural Network (CNN), умеющей после предварительного обучения распознавать и классифицировать объекты в произвольном изображении? Теперь связку из двух нейронных сетей можно попытаться обучать на эталонном массиве картинок с их словесными описаниями как единый механизм.
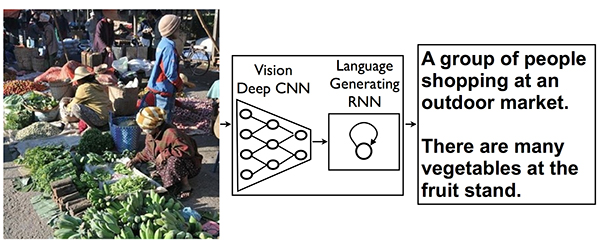
Примерно так это делается
Как оказалось, результат получился довольно приличный. Вот примеры описания картинок, получившихся после обработки фотографий, взятых с открытых публичных ресурсов типа Flikr. Авторы говорят, что об этом свидетельствуют и количественные оценки по метрике Bilingual Evaluation Understudy (BLEU), широко используемой в тестах по машинному переводу.

В крайней левой колонке примеры безошибочного описания, в крайней правой - крайне неудачного, а посредине - с тем или иными погрешностями. Скажем, неудачным признано описание "желтый школьный автобус, припаркованный на стоянке" для фотографии, на которой изображена желтая легковушка, стоящая, судя по всему, на автозаправке (снимок в правом нижнем углу). А небольшой погрешностью признано описание "крупный план кошки, лежащей на кушетке", поскольку она там не лежит , а сидит.
Мне кажется, правильнее было называть все это системой перевода с "изобразительного" языка, на естественный человеческий. А с учетом упомянутой способности RNN-сети брать исходное векторное представление фразы и затем восстанавливать его на любом поддерживаемом языке, система обещает стать универсальной для самых разных стран и языков.





