








[spoiler]Причина этого прежде всего в том, что данные генерируются одними системами, а потребляются другими. Так сложилось исторически, когда КИС были еще маленькими, и на долю ETL приходились незначительные ресурсные траты -- не было смысла делать «всё», что связано с данными, выделенно-централизованно. Но теперь появился Hadoop -- и дело даже не в этом конкретном продукте, а в предлагаемой им модели, создающей наконец реальную организационную ценность. Вот вариант такой модели от Phil Shelley, CEO фирмы Metascale, специализирующейся на модернизации легаси-систем под Hadoop.
- Внешние системы генерируют данные, как обычно.
- Как можно ближе к реальному времени эти данные грузятся в Hadoop. Это вроде бы классический Extact, но на этом сходство заканчивается. Данные мы можем сразу же интегрировать, сортировать, преобразовывать и даже анализировать внутри Hadoop уже на этом этапе. Вместо E мы получаем сразу полный цикл ETL.
- Задержки в обработке и поставке данных снижаются с часов до минут, потому что информация не покидает Hadoop, нету повторной нагрузки на сеть и диски, не надо платить за специализированный софт и дополнительное железо.
- Сами данные теперь не надо больше никуда перемещать. Имеется обширная линейка систем графической аналитики и построения отчетов на базе Hadoop, которые не будут впустую гонять массивы данных по корпоративной сети.
- В редких случаях подмножества данных приходится перемещать за пределы Hadoop, но во-первых, их структуру можно предварительно сильно оптимизировать под целевую задачу, а во-вторых, как показывает практика, в реальных проектах практически всегда можно обойтись «чистым» Hadoop, без преодоления данными его границ.
Особое внимание Metascale, кстати, уделяет уходу с мэйнфреймов, которых в мире насчитывается еще немало. И что интересно, даже системы на морально устаревших мэйнфреймах продолжают масштабироваться
В результате же перехода стоимость владения новой Hadoop-системой в сравнении с мэйнфреймовской снижается на порядок. Например, код из семи тысяч строк на Коболе заменятеся на скрипт из 50 операторов PIG (язык для MapReduce).
И все же ложечку дёгтя необходимо добавить:
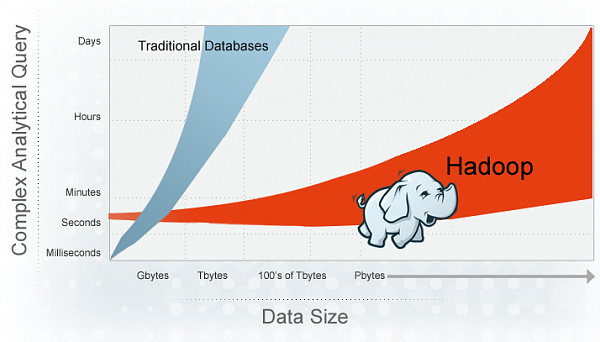
- Hadoop -- не скоростная SQL-база (хотя и имеются упоминавшиеся ускорители);
- Hadoop трудоёмко состыковывать с легаси-системами;
- Hadoop -- не замена хранилищам данных, а добавка к ним;
- Hadoop -- сложная технология;
- архитектурно Hadoop отличается от общепринятых технологий практически по всем аспектам, от хранения и де-нормализации данных до их загрузки и извлечения;
- айтишникам придётся прилично попотеть, изучая Hadoop;
- для развертывания Hadoop-системы своими силами критически важны скиллы Linux и Java.





