









| Выбранная новая платформа — продукт «российско-американской компании, которая выиграла тендер у Oracle, IBM, у всех, оказалась на порядок выше этих крупнейших компаний», сказал он, добавив, что речь идет об Open Source. Банк планирует перевести свои основные системы на технологию in memory data grid, которая позволяет обрабатывать практически неограниченный объем данных исключительно в оперативной памяти, то есть с максимальной скоростью. На жесткий диск данные сбрасываются только в режиме архивирования. |
Что же представляет собой in-memory технология, реализованная в продукте GridGain In-Memory Data Fabric? В последнее время у всех на слуху in-memory СУБД SAP HANA, Oracle и ряда других вендоров. Однако продукт GridGain, хотя и осуществляет обработку больших массивов данных в оперативной памяти, СУБД не является. Как уточнил на ресурсе Linux.com Никита Иванов: "Наше ПО логически и архитектурно находится в слое над БД и под приложением. Цель здесь - обеспечить более высокую производительность и масштабируемость приложений в сравнении с системами, основанными на дисковом хранении данных". Иными словами, речь идет о своеобразном кэше в ОЗУ, куда помещаются все активно используемые данные из самых разных источников, включая реляционные, NoSQL, Hadoop, потоковую информацию и т.д. Ну и ни слова о десятках тысяч изменений, упоминавшихся Грефом, которые Сбербанк хочет оперативно вносить в свои системы. Вот как это выглядит в случае обработки больших данных.
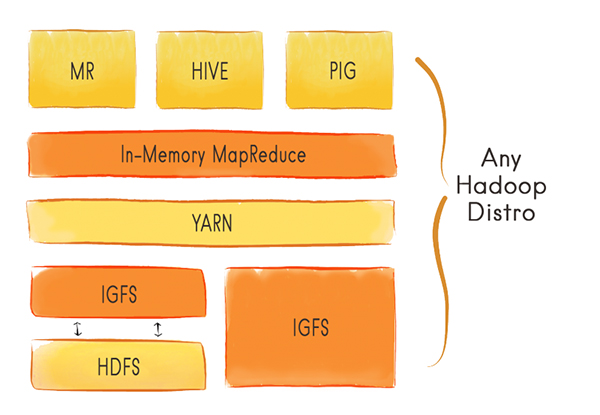
Здесь IGFS - Это Ignite File System, а по сути GridGain In-Memory Data Fabric (Ignite - название опенсорсного проекта Apache Software Foundation, которому GridGain передала исходный код). Замечу, что бесплатно предоставляется только код базовой версии Ignite, за дополнительные функции GridGain In-Memory Data Fabric, средства управления и техподдержку заказчику придется платить. Фишка технологии Ignite, отличающая ее от обычного кэширования, как я понимаю, в том, что этот кэш, процессоры для его обработки и сопутствующие инструменты реализованы не на отдельном сервере, а на кластере из серверов стандартной архитектуры, и он обладает "неограниченной" вертикальной и горизонтальной масштабируемостью (никаких данных о пределах такой масштабируемости мне обнаружить не удалось). Судя по всему, похожие функции выполняет продукт Oracle Coherence: во всяком случае, на сайте GridGain приводится сравнение функциональности GridGain In-Memory Data Fabric именно с ним.
Из всего сказанного следует, как мне представляется, что речь может идти только об определенной модернизации ИТ-инфраструктуры Сбербанка с использованием GridGain In-Memory Data Fabric (возможно, и очень полезной), но никак ни о полной ее переделке или замене.





