














Санджив Мохан, директор компании SanjMo, и Мадхукар Кумар, директор по маркетингу компании SingleStore, обсуждают на портале The New Stack восемь компонентов, которые необходимо учитывать при оценке новой или существующей базы данных для обработки рабочих нагрузок генеративного искусственного интеллекта.
Кажется, что почти каждый день появляется новое приложение ИИ, которое расширяет границы возможного. Несмотря на все внимание, которое привлекает к себе генеративный ИИ, некоторые его громкие ошибки еще раз напомнили миру о том, что «мусор на входе, мусор на выходе». Если мы игнорируем основополагающие принципы управления данными, то полученным результатам нельзя доверять.
Чтобы использовать новые большие языковые модели (LLM) и открыть для себя новые возможности, техническим специалистам придется не только изменить свою стратегию работы с данными и существующую инфраструктуру данных, но и определить, какие технологии являются лучшими и наиболее эффективными для обеспечения рабочих нагрузок ИИ.
Рассмотрим, какие компоненты баз данных необходимы организациям для использования возможностей LLM на собственных данных.
Восемь компонентов для поддержки рабочих нагрузок ИИ
Базы данных, поддерживающие рабочие нагрузки ИИ, должны обеспечивать низкую задержку и высокую масштабируемость запросов. Мир LLM расширяется очень быстро — некоторые модели полностью открыты, другие полуоткрыты, но имеют коммерческие API.
При принятии решения о том, как оценить новую или существующую базу данных для обработки рабочих нагрузок генеративного ИИ, необходимо учитывать множество факторов. Основные возможности, необходимые для выполнения рабочих нагрузок ИИ, показаны на следующей схеме:
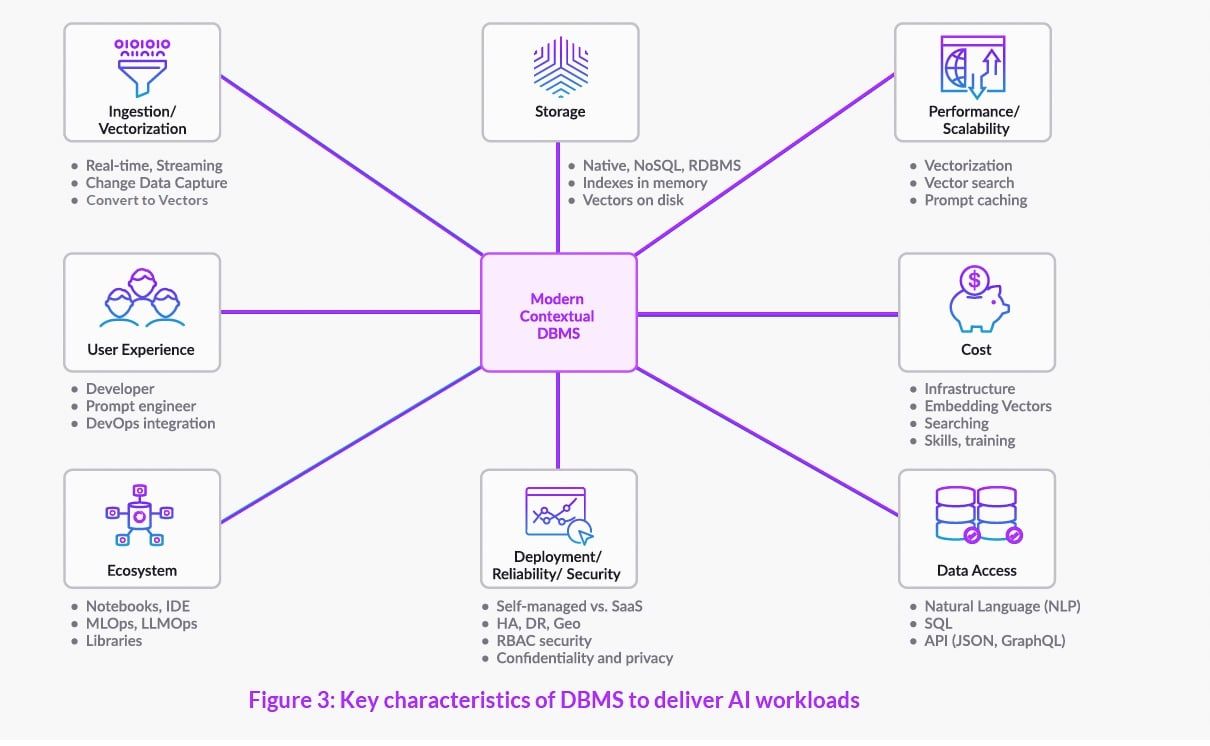
1. Ввод/векторизация
Обучающие данные для GPT-4 были основаны на данных, доступных только до сентября 2021 г. Без усовершенствований, таких как плагин для браузера, ответы этого ИИ-чатбота будут устаревшими, тогда как организации рассчитывают принимать решения на основе самых свежих данных.
Следовательно, возможности базы данных по загрузке данных должны включать в себя:
- ввод, обработка и анализ многоструктурных данных;
- загрузка как пакетных, так и потоковых данных в режиме реального времени, включая возможность легко извлекать данные (до миллионов событий в секунду) из различных источников данных, включая Amazon S3, Azure Blobs, Hadoop Distributed File System (HDFS) или потоковую службу типа Kafka;
- вызов API или функций, определенных пользователем, для преобразования данных в векторы;
- индексация векторов для быстрого векторного поиска (поиска сходства);
- немедленный доступ к данным для анализа по мере их поступления.
Реляционная система управления базами данных (РСУБД) имеет преимущество в том, что предыдущие задачи выполняются на более привычном языке SQL.
2. Хранение
Обсуждение может быть цикличными. Дебаты о том, лучше ли использовать специализированную векторную структуру данных в NoSQL, снова разгорелись, как и вопрос о том, могут ли мультимодельные базы данных быть столь же эффективны. За 15 лет существования баз данных NoSQL мы уже привыкли видеть, как реляционная структура данных нативно хранит JSON-документ. Однако первые воплощения мультимодельных баз данных хранили документы JSON как BLOB (большой двоичный объект).
Пока еще рано говорить о том, сможет ли мультимодельная база данных хранить векторные представления так же хорошо, как нативная векторная база, но мы ожидаем, что эти структуры данных будут сближаться.
Векторные представления могут быстро увеличиваться в размерах. Поскольку векторный поиск выполняется в памяти, хранить все векторы в памяти может быть нецелесообразно. Поиск векторов на дисках не является эффективным. Следовательно, база данных должна иметь возможность индексировать векторы и хранить в памяти индексы, в то время как сами векторы находятся на диске.
3. Производительность (вычисления и хранение)
Важным аспектом настройки производительности является способность индексировать векторы и хранить их в памяти.
База данных должна иметь возможность разбивать векторы на шарды в более мелких ведрах, чтобы их можно было искать параллельно и использовать аппаратные оптимизации, такие как SIMD (одиночный поток команд, множественный поток данных). SIMD может обеспечить быстрое и эффективное выявление сходства векторов — без необходимости распараллеливания приложения или перемещения большого количества данных из базы данных в приложение.
Если в LLM подается большое количество представлений, то задержка ответов, соответственно, будет очень высокой. Цель использования базы данных в качестве посредника состоит в том, чтобы выполнить первоначальный векторный поиск и сократить число представлений для отправки в LLM.
Кэширование подсказок и ответов от LLM может еще больше повысить производительность. Из мира BI мы знаем, что большинство вопросов, задаваемых в организации, часто повторяются.
4. Стоимость
Стоимость может стать одним из самых больших препятствий для массового внедрения LLM. Эту проблему можно решать путем развертывания базы данных для осуществления API-вызовов к LLM. Как и в любой инициативе, связанной с данными и аналитикой, здесь необходимо рассчитать общую стоимость владения (TCO), включающую:
- Стоимость инфраструктуры базы данных. Сюда входят лицензирование, оплата за использование, API и т. д.;
- Стоимость поиска данных с использованием векторных представлений. Обычно она выше, чем обычная стоимость полнотекстового поиска, поскольку для создания представлений требуется дополнительная обработка данных на CPU/GPU;
- Навыки и обучение. Мы уже видели рождение роли «инженера-подсказчика». Кроме того, для подготовки данных к векторному поиску необходимы навыки Python и машинного обучения.
В конечном итоге мы ожидаем, что поставщики средств FinOps-наблюдаемости добавят возможности для отслеживания и аудита затрат на векторный поиск.
5. Доступ к данным
Семантический поиск опирается на обработку естественного языка (NLP), чтобы задавать вопросы — это означает, что зависимость конечных пользователей от SQL уменьшается. Вполне возможно, что LLM заменят отчеты и приборные панели бизнес-аналитики. Кроме того, критически важной становится надежная инфраструктура для работы с API. API могут быть традиционными HTTP REST или GraphQL.
Однако в базе данных, поддерживающей традиционные онлайновые транзакции и онлайновую аналитическую обработку, использование SQL может позволить смешивать традиционный поиск по ключевым словам (т. е. лексический) с возможностями семантического поиска, предоставляемыми LLM.
6. Развертывание, надежность и безопасность
Как известно, для повышения производительности векторного поиска векторы должны быть общими. Этот подход используется поставщиками баз данных для повышения надежности, поскольку шарды работают в подах, оркестрируемых Kubernetes. При таком самовосстанавливающемся подходе, если под выходит из строя, он автоматически перезапускается.
Поставщики баз данных также должны распределять шарды по разным облачным провайдерам или регионам внутри облачного провайдера. Это решает две проблемы — надежность и конфиденциальность данных. Из-за последней организациям необходимо, чтобы чатбот или API к LLM не хранили подсказки и не переучивали свою модель.
Наконец, векторный поиск и вызов API к LLM должны осуществлять контроль доступа на основе ролей (RBAC) для сохранения конфиденциальности, как и при обычном поиске по ключевым словам.
7. Интеграция экосистемы
База данных, поддерживающая рабочие нагрузки ИИ, должна иметь интеграцию с более крупной экосистемой. Она включает:
- Ноутбуки, или интегрированные среды разработки (IDE), для написания кода, которые позволят реализовать шаги цепочки создания ценности ИИ.
- Существующие возможности MLOps от облачных провайдеров, например AWS, Azure и Google Cloud, а также независимых поставщиков. Кроме того, на рынке начинает появляться поддержка LLMOps.
- Библиотеки для генерации представлений, такие как OpenAI и HuggingFace. Это быстро расширяющееся пространство с множеством открытых и коммерческих библиотек.
Ландшафт современных приложений пересматривается благодаря возможности связывать различные LLM в цепочки. Это хорошо видно на примере LangChain, AutoGPT и BabyAGI.
8. Пользовательский опыт
Споры о том, какую технологию лучше использовать для решения конкретной задачи, часто решаются скоростью внедрения. Часто побеждают технологии, которые обеспечивают лучший пользовательский опыт. Этот опыт проявляется по разным направлениям:
- Опыт разработчика: возможность написания кода для подготовки данных к нагрузкам ИИ.
- Потребительский опыт: простота генерирования нужных подсказок.
- DevOps-опыт: возможность интеграции с экосистемой и развертывание (CI/CD).
Поставщики баз данных должны предоставлять лучшие практики для всех персон, взаимодействующих с их предложениями.
Ясно одно: пространство генеративного ИИ только зарождается и находится в процессе развития. В конечном итоге, руководящие принципы, которые применяются к другим дисциплинам управления данными, должны соблюдаться и в отношении ИИ. Будет хорошо, если вышеизложенное хоть немного помогло понять, что необходимо для использования рабочих нагрузок ИИ и как выбирать оптимальные технологии баз данных.












