Вы бы хотели иметь возможность находить близкие вашим интересам научные работы независимо от предметной области или языка и с большей эффективностью, чем можно было вообразить? Тогда вам поможет поисковая система Omnity, использующая смесь разных техник.
Поиск связей — трудное дело. Это вам скажет любой консультант по данному вопросу, как и любой человек, когда-либо занимавшийся исследованиями, неважно по какой теме. Находить, что другие люди уже сделали в вашей области, это тяжелый труд, но он необходим, чтобы правильно позиционировать свою работу и связать ее с работами других авторов, выявить конкурентов или возможных партнеров или улучшить экспериментальную модель.
Так было всегда, но с ускорением темпов инноваций и исследований идти в ногу со временем становится все труднее. Как человек, имеющий около 120 личных патентов, Брайан Сэйджер знал все это не понаслышке, и он решил, что с этим пора кончать.
Как это часто бывает в исследованиях, решение заняться каким-то вопросом может иметь далеко идущие последствия. Сэйджер, бывалый профессионал в исследованиях и разработках и серийный предприниматель, увидел потенциал своего решения проблемы и решил для его коммерциализации основать компанию Omnity.
«Документы имеют гораздо меньше ссылочных связей, чем могло бы быть. В списках цитируемой литературы обычно фигурирует лишь малая доля, порядка одного процента, всех возможных ссылок. Почему? Потому что ни один автор не может знать все, — говорит он. — И ситуация изменяется лишь в худшую сторону, так как наши мозги остаются прежними, а объем информации, с которой нам приходится иметь дело, бурно растет. Поэтому можно ожидать, что этот один процент превратится в ничтожную малость. Наша разработка для решения этой проблемы представляет собой следующее поколение технологий поиска».
Omnity использует смесь дата-центрических техник, и способ, которым это делается, не только интересен сам по себе, но и может найти применение в ряде других задач.
Степенной закон имеет отношение к языку
Подход Omnity учитывает степенной закон — статистическое распределение частотности слов в языке. В каждом языке имеется небольшое количество слов, которые используются всеми людьми, и большая масса слов, которые практически никем не используются. В английском языке имеется примерно 700 тыс. слов, первая десятка ходовых слов используется в 25% документов, первая сотня — в 50% и первые 7 тыс. слов — в 90%.
Вот что говорит Сэйджер:
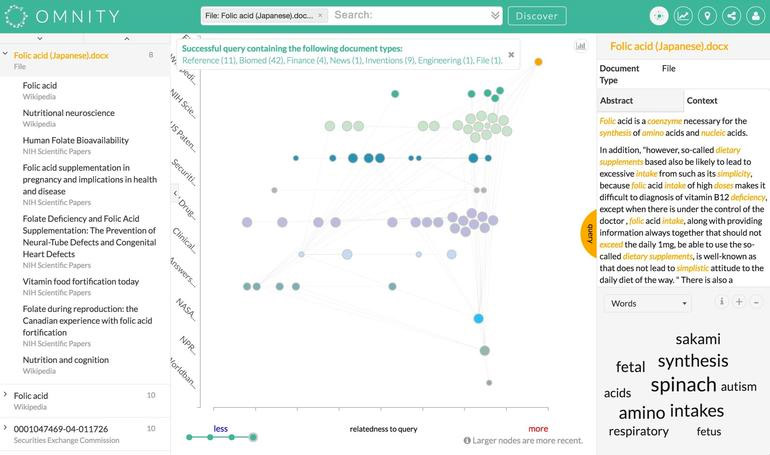
«Используя слова, находящиеся в длинном хвосте, люди подразумевают в точности то, что эти слова означают, и ничего другого. Поэтому если два документа имеют одинаковую картину распределения в них редких слов, это почти наверняка означает, что в них говорится про один и тот же предмет. Мы называем эту картину распределения семантической сигнатурой документа.
Это применимо не только к английскому языку, но и к другим языкам, поскольку все языки следуют тому же степенному закону. Например, если я хочу подать заявку на патент, мне надо удостовериться, что он не является дубликатом. Значит, мне нужно найти и проверить все патентные реестры в мире. Возможно, кто-то сделал что-то подобное в Японии, но я не знаю японского языка, и потому у меня нет возможности это узнать.
С Omnity это не проблема: мы проанализируем семантическую сигнатуру вашего документа и найдем потенциальные соответствия в любом языке. Наша обработка основана на математике, а не на языке. Мы разбиваем содержимое документа на метки и работаем с метками».
Сопоставлять + соединять = языково-независимая обработка документов
Но постойте. Как вы узнаете, часто или нет используется слово? Разве для этого не требуется что-то вроде словаря? Насколько языково-независимой в реальности может быть обработка языка?
«Одна из проблем машинного перевода состоит в том, что вам нужно учитывать контекст и еще ряд других вещей, но мы в этом не нуждаемся. Мы не переводим, а просто отображаем редкие слова», — поясняет Сэйджер.
Подобие документов оценивается путем сложения баллов соответствий первого, второго и третьего ранга: слова, присутствующие в обоих документах; слова, синонимы или ряды синонимов которых присутствуют в обоих документах; и слова, ряды синонимов которых родственны и присутствуют в документах.
Но неужели все сводится к одной статистике? Нет, это не так. Omnity также использует комбинацию машинного обучения (МО) и обработки графов.
Omnity имеет собственную внутреннюю базу данных с 15 Тб документов, и когда пользователи представляют документы для обработки, она по ним осуществляет поиск. База данных также организует документы по тематикам (например, медицина, право и т. п.) и использует МО для классификации представленных новых документов.
МО используется и для улучшения алгоритмов Omnity посредством измерений того, насколько хорошо они работают. Пользователи представляются списком соответствий для их документов, и поэтому система записывает события и метрики типа количества кликов (CTR) и наведений курсора мыши, используя эти данные для оценки и усовершенствования алгоритмов.
Omnity оценивает пользовательские намерения и использует это для повышения или снижения ранга документов, комбинируя это со своей структурой графов: результаты являются узлами графов, а связи между ними являются ребрами. Некоторые результаты будут иметь больше соединений (цитирований), чем другие, что означает более высокую важность.
Граф для Omnity имеет центральное значение. «Мы проверяли решения типа графовой СУБД Neo4j, но натолкнулись на проблемы с масштабированием, — говорит Сэйджер. — Во время нашего тестирования Neo4j имела лимит в 30 млрд. узлов, но для нас этого недостаточно. Мы имеем дело с квадрильонами узлов, и поэтому нам пришлось разрабатывать собственное решение. Мы даже можем рано или поздно его независимо лицензировать».
Связи — чем они полезны?
Все это здорово и хорошо, но почему это вас должно волновать, если вы не исследователь? По словам Сэйждера, эта разработка сфокусирована на работниках умственного труда — людях, зарабатывающих на жизнь своим мышлением. Но вы не обязаны писать научные статьи или подавать заявки на патенты, чтобы извлекать из них пользу.
Omnity считает главными областями применения своей системы исследования и разработки, а также юриспруденцию, но еще имеет конъюнктурные виды на такие сферы, как финансы и управление контентом. По словам Сэйджера, хорошими кандидатами на практическое использование Omnity являются области, где люди имеют дело с большим количеством документов с техническими терминами и высокой степенью связанности и где нужна ясность и оперативность.
В юридических делах, используя распознавание семантической структуры, люди могут связать свой тезис с другими документами, чтобы увидеть, насколько он правомерен, говорит Сэйджер. Например, они могут установить прецедент или отыскать соответствующие нормы законодательства, а в ряде случаев даже доказательства.
В финансах Omnity принесет пользу при сделках по слиянию и приобретению бизнеса, а также при проведении аудита и экспертиз. В обоих случаях присутствует огромное количество документов, которые надо как можно быстрее обработать, и в Omnity заявляют, что система за секунду может отыскать и извлечь большую массу документов, на подбор которых у аналитика ушли бы дни или недели.
Понятно, что возможности Omnity не безграничны. Система может быть очень эффективной в получении родственных документов, но на этом ее миссия кончается.
Так что же будет происходить с тем самым патентом на японском языке? После его ввода в систему и привязки к его англоязычному эквиваленту Omnity позволит решить, что с ним делать, — выделить ему больше ресурсов или, может быть, сделать его перевод.
Omnity также поддерживает понятие рабочих пространств для пользователей. Документы попадают в рабочие пространства, где они проходят обработку и строятся связи с использованием пользовательских взглядов на мир через МО. «Мы используем МО для категоризации документа пользователя посредством его собственных пометок, — говорит Сэйджер. — Имея представление о его рабочем пространстве, мы соответствующим образом организуем обработку. У каждого пользователя имеется собственный взгляд на семантику, и мы можем ко всем ним приспосабливаться. Например, если сотрудников компании из списка Fortune 100 интересует продукт A, им не важно, где найден документ, их интересует, в чем он подходит семантически».