













Мощнейшие изменения, происходящие сейчас на аппаратном, программном, коммуникационном и инфраструктурном уровнях суперкомпьютерных технологий, отражают наиболее значительную за последние годы трансформацию индустрии высокопроизводительных вычислений (HPC). Интрига сложившейся на сегодня ситуации заключается в том, что всё это множество событий, идей, технологий, разработок и даже рекордов года уходящего проявит кумулятивный эффект только в течение нескольких последующих лет. Прибегая к образной аналогии, можно сказать, что весь прошедший год отрасль HPC занималась разработкой и производством «кирпичиков» и теперь в распоряжении «архитекторов» индустрии есть всё, чтобы строить невероятные «супердома будущего».
Время разбрасывать камни
Три года подряд рейтинг самых производительных суперкомпьютеров планеты TOP500 возглавляет неизменный Tianhe-2 китайского национального оборонного университета с неизменными 33,86 Пфлопс. Застой? Ни в коем случае. Сравнение количества суперкомпьютеров в TOP500 с производительностью более 1 Пфлопс сейчас и три года назад показывает огромный прирост: 82 системы против 26. За три года создание вычислительного комплекса такой мощности стало более доступным благодаря появлению нового поколения более производительных и экономичных процессоров, ускорителей, коммуникационных и других компонентов.
Получается, рубеж в 1 Пфлопс постепенно превращается в мейнстрим, в то время как планка в 50 Пфлопс так и осталась не взятой. Причин этому можно назвать несколько, но основной, пожалуй, является экономическая целесообразность. С технической точки зрения нынешний рекорд TOP500 вполне мог быть побит и в этом, и, возможно, даже в прошлом году. Однако этого не произошло, несмотря на растущую опережающими темпами «жажду» на вычислительные ресурсы со стороны государственных учреждений, науки, обороны, образования, промышленности. Времена инвестирования в рекорды ради самих рекордов, похоже, позади и вряд ли уже вернутся.
У любой новой рекордной планки есть своя цена, и адекватной она может стать в единственном случае: при появлении полного комплекса технологий нового поколения. Именно этим — если вкратце, занималась индустрия HPC в
Трансформация HPC: новые рынки и приложения
Аналитики IDC в прогнозах развития отрасли всё чаще указывают на растущую тенденцию переноса HPC в облака. Наряду с ростом популярности графических ускорителей и сопроцессоров, позволяющих значительно повысить оперативность систем, возрастающая роль в развитии HPC также отводится современным хранилищам данных, переходу на новые типы межсоединений, организации памяти и другим аппаратным вопросам. Однако при этом наиболее важным вопросом аналитики считают своевременное развитие технологий управления и перемещения данных, которые после многолетнего переходного периода положат конец нынешнему «экстремальному вычислительному центризму» (extreme compute-centrism) в пользу программно-определяемых систем и других инновационных идей.
По данным IDC, в ближайшие годы рынок HPC будет расти в среднем на 8,2% ежегодно в ближайшие пять лет и достигнет к
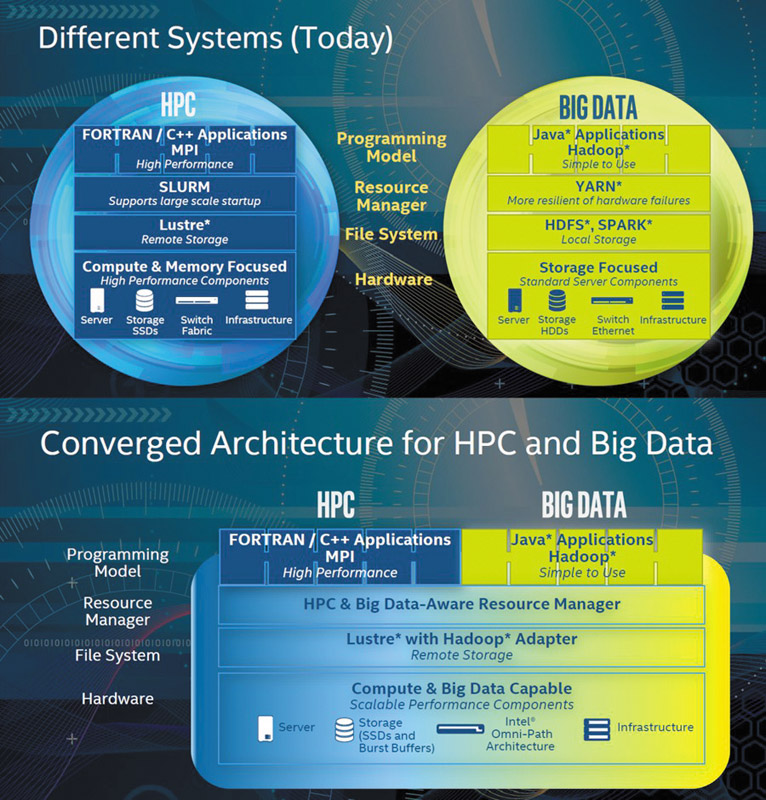
Сочетание HPC и Big Data, породившее новый сегмент — HPDA (High Performance Data Analysis, высокопроизводительная аналитика данных), определяет основные акценты развития всех трёх ключевых компонентов. Вычислительные ресурсы HPC нового поколения будут работать с более сложными алгоритмами, в условиях высокой критичности таких вычислений к временным рамкам (в идеале — в режиме реального времени), а также в меняющихся условиях размещения данных, в том числе в облаке. Условие работы с любыми видами информации вызывает необходимость универсальной поддержки любых объёмов, сочетаний, значений и изменений данных, структурированных и неструктурированных, разбиваемых и не разбиваемых на разделы, с постоянными и нерегулярными структурами. Наконец, сами задачи аналитики и моделирования (simulation & analytics) требуют новых разработок и подходов, применения итерационных методик, которые будут востребованы как традиционными потребителями HPC, так и совершенно новым классом коммерческих пользователей.
Модель грядущей конвергенции систем HPC и Big Data описал в одном из своих выступлений Раджиб Хазра, вице-президент Intel и глава Data Center Group компании. Несмотря на существенные различия между современными программно-аппаратными платформами для обоих направлений, включая модели программирования, управление ресурсами, файловые системы и инфраструктурные организации, для конвергированных систем HPC — Big Data будущего вполне возможно создание единой структуры с конфигурируемой иерархией памяти-хранения.
Intel предлагает платформенный комплекс Scalable System Framework (Intel SSF), позволяющий создавать масштабируемые, гибкие и сбалансированные HPC-системы. В ноябре на выставке SC’15 (Остин, США) компания представила основной элемент SSF — сквозную коммутационную технологию Intel Omni-Path Architecture (Intel OPA), делающую HPC-кластеры доступными большему количеству пользователей.
О планах по выпуску систем на базе Intel SSF в начале 2016 г. уже заявили многие ведущие производители планеты, в том числе, российская группа компаний РСК. На выставочном стенде РСК на SC’15 были показаны образцы будущего процессора Intel Xeon Phi
Новые 768- и
Ключевая особенность новых Intel Xeon Phi
Следующее за Knights Landing поколение Xeon Phi с названием Knights Hill будет выпускаться по нормам
По мнению IDC, в ближайшее время рынок HPC — HPDA помимо традиционных финансового, оборонного и других направлений будет активно прирастать такими новыми индустриальными сегментами, как обнаружение аномалий и мошенничества (технологии идентификации на базе семантического, графического и других видов анализа), маркетинг (с применение более сложных алгоритмов таргетинга на основе оперативной информации о демографии, предпочтениях и привычках потенциальных потребителей), бизнес-аналитика (динамическое определение возможностей для расширения рыночной позиции и повышения конкурентоспособности за счёт лучшего понимания собственного бизнеса и конкурентов), а также ряд других коммерческих приложений.
По прогнозам IDC, через некоторое время ряд сегментов HPDA станет достаточно велик для разделения на отдельные направления, такие как, например, использование HPC для управления крупными корпоративными ИТ-инфраструктурами или взаимодействия с Интернетом вещей (Internet-of-Things, IoT).
Одним из наиболее важных и энергично развивающихся рынков применения HPDA и, соответственно, HPC, в ближайшие годы станет сегмент так называемого «глубокого машинного обучения» (Machine Learning/Deep Learning), когда перед вычислительной системой ставится не только цель поиска решения поставленной задачи, но в нее также закладываются алгоритмы самообучения, вплоть до механизмов когнитивных вычислений и искусственного интеллекта, позволяющие по ходу решения задачи разрабатывать собственные правила.
В настоящее время определяющими проблемами систем глубокого обучения для массового ИТ-рынка (некритичных по времени приложений и публичных облаков) считается разработка последовательных и наукоёмких алгоритмов, а также технологий, позволяющих отсеять ненужное и значительным образом (порой до 99%) сократить объём полезной информации ещё до начала её анализа.
Для высокопроизводительного (HPDA) рынка (критичного по времени, где далеко не всегда уместны публичные облака) акцент делается на разработку параллельных алгоритмов, приложений для создания научных данных, работы с гигантскими объёмами информации, где требуется получение результата очень высокого качества/разрешения.
В рамках конференции SC’15 вопросы глубокого машинного обучения фигурировали в качестве одной из ключевых тем многих мероприятий форума. Многие компании подготовили собственные программные и программно-аппаратные решения, ориентированные как на разработку алгоритмов, так и на обучение будущих специалистов в сфере Deep Learning. Nvidia представила комплексную масштабируемую платформу для ускорения анализа данных с алгоритмами машинного обучения. Платформа включает набор программных инструментов Hyperscale Suite для машинного обучения и обработки видеоданных, а также линейку ускорителей Tesla Hyperscale Acceleration, включая мощную модель Tesla M40 с 3072 ядрами CUDA и производительностью до 7 Тфлопс для обучения глубоких нейронных сетей и экономичную модель Tesla M4 для систем машинного обучения и обработки потокового видео и фотоизображений.
Список новых решений Nvidia для машинного обучения также включает портативный модуль Jetson TX1 для использования в различных полуавтономных самообучающихся устройствах вроде дронов или роботов, бортовой компьютер DRIVE PX с 12 входами для камер, радаров или лидаров для автономных автомобилей, а также уникальное решение DIGITS DevBox класса рабочей станции на базе Nvidia GeForce GTX TITAN X, позволяющего запускать самообучающиеся алгоритмы на настольном оборудовании. Совсем недавно компания также объявила об оснащении вычислительных систем нового поколения Facebook Big Sur ускорителями Tesla M40 для запуска различных приложений машинного обучения в рамках проекта Facebook AI Research (FAIR) для обучения нейронных сетей.
По словам Роя Кима, менеджера подразделения продуктового маркетинга Nvidia, применение акселераторов класса Tesla M40 в отдельных приложениях позволяет ускорить процесс машинного обучения в разы, сокращая продолжительность ряда операций с недели до суток. «Пакет Nvidia Hyperscale значительным образом упрощает и ускоряет процесс разработки приложений для машинного обучения. Теперь в распоряжении разработчиков и администраторов есть алгоритм cuDNN для глубоких сверточных нейронных сетей, GPU-ускоряемое ПО FFmpeg для ускорения перекодировки и обработки видео, движок GPU REST для ускоренного разворачивания веб-сервисов высокой пропускной способности, а также GPU-ускоряемый сервис Image Compute Engine с API REST для быстрого изменения изображений», — рассказал он.
Среди интересных решений, представленных под конец 2015 г., также стоит отметить новое поколение InfiniBand-коммутаторов Mellanox Switch-IB 2 с пропускной способностью 100 Гбит/с на порт, оптимизированное для задач HPC, Web 2.0, ЦОДов и облачных сервисов.
В рамках выставки SC’15 некоторый свет на свой грандиозный проект Flagship 2020 пролила компания Fujitsu. Платформа будет базироваться на новых
Под конец 2015 г. также была озвучена новая интересная инициатива Linux Foundation — OpenHPC, нацеленная на создание открытых стандартов для HPC-сообщества. В настоящее время участниками OpenHPC являются многие лидирующие компании отрасли, включая Intel, Cray, Dell, HP Enterprise, Fujitsu, Lenovo, SUSE и другие. Инициатива очень многообещающая и со временем может стать новым фундаментом для всесторонней стандартизации HPC-систем.













