На примере Intel мы видим, как ей все сложнее и сложнее дается следовать закону Мура, переходя с одного техпроцесса на другой, пишет портал ZDNet. Существуют опасения, что когда-то он перестанет действовать в принципе, но пока что хоть и со скрипом, но он все же позволяет каждые два года удваивать количество транзисторов, размещаемых на кристалле интегральной схемы. Одновременно с этим разработчикам микросхем приходится искать новые способы скачкообразного наращивания вычислительной мощности компьютеров, к которому привык потребитель. Одна из последних тенденций в процессоростроении связана с применением специализированных чипов, дизайн которых оптимизирован для выполнения конкретной задачи.
Одним из примеров является Google Tensor Processing Units (TPU) — сделанный под заказ процессор, который превосходно справляется с математическими операциями, необходимыми для машинного обучения. Другой пример — специализированные чипы, которые появились на пике интереса к майнингу криптовалют. Эти микросхемы отличаются от традиционного CPU (central processing unit, центрального процессора), который способен выполнять очень широкий спектр вычислительных задач и может считаться универсальным чипсетом.
Несмотря на то, что специализированные чипы или прикладные интегральные микросхемы специального назначения (application-specific integrated circuit, ASIC) наподобие TPU как никакие другие подходят для решения различных вычислительных задач, у них есть один существенный недостаток — это непомерная стоимость разработки, говорит директор по управлению программами по созданию кремниевой архитектуры бесфабричного производителя чипов Netronome Бапи Виннакота.
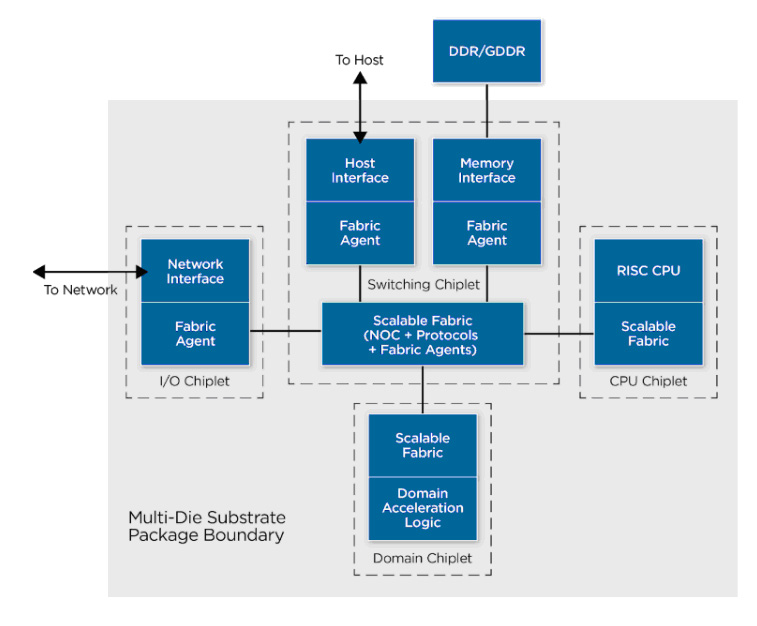
ASIC сегодня — это устройства типа «система на кристалле» (system-on-a-chip, SoC). Как следует из названия, она представляет из себя один монолитный чип, разделенный на несколько частей, каждая из которых выполняет различные задачи, начиная от центральной обработки и заканчивая обслуживанием интерфейсов с портами USB и контроллерами памяти. По мере увеличения функциональности SoC и увеличения его площади увеличивается вероятность дефектов, что ведет к превышению нормы выхода бракованной продукции и увеличению затрат.
Таким образом, наращивать производительность монолитной структуры ASIC становится на порядок сложнее, и отрасль пошла на ухищрения, разбивая их на отдельные и более компактные «чиплеты» (chiplets), которые специализируются на отдельных задачах — как общего плана, так и предметно-ориентированных (специфичных для конкретной области). Выгода разделения CPU состоит в том, что при меньшей площади поверхности чиплеты обладают большей производительностью, чем монолитные SoC. Этого удалось добиться за счет повышения производительности межсоединений для обмена данными между чиплетами.
По словам Виннакоты, применение чиплетов может удешевить разработку предметно-ориентированных ускорителей типа TPU: «Современные реалии бесфабричного производства логики таковы, что принимаясь за разработку ускорителя вычислений, заказчику нужно побеспокоиться лишь об одном: каким должен быть целевой чиплет. Теперь подобрать лучший в своем классе чиплет можно едва ли не для каждой функции. Можно, например, купить чиплет ввода-вывода, и это будет заводской чип. Таким образом, заказчик существенно снизит затраты на разработку и тестирование. Они были бы существенно выше, если бы он проектировал не чиплет, а полноценную SoC с гораздо большим количеством транзисторов и, соответственно, с более сложной компоновкой».
Помимо этого стоимость чипов можно снизить путем компиляции новых и старых поколений чипов, даже тех, которые производятся на базе различных норм техпроцессов. От последних зависит размер транзисторов, которые пакуются в чип, и, следовательно, их количество. По словам Виннакоты, применение чиплетной технологии для создания ASIC наряду с уменьшением стоимости и улучшением быстродействия значительно увеличит производительность на ватт, что открывает перед ASIC новые возможности для решения более широкого круга задач, чем это возможно сегодня.
Так что мешает более широкому внедрения чиплетов? Проблема в отсутствии единого аппаратного интерфейса для взаимодействия этих чипсетов, который позволил бы разработчикам микросхем беспроблемно микшировать их. Чтобы преодолеть эту проблему, проект Open Compute и Neutronome запустили подпроект Open Domain-Specific Architecture (ODSA), целью которого является разработка открытого интерфейса и архитектуры, позволяющих чиплетам, изготовленным разными производителями, работать вместе.
Виннакота, который также возглавляет разработку стандарта ODSA в Netronome, выразил надежду, что внедрение отраслевой спецификации послужит толчком для разработки широкого спектра специализированных чипов, что позволит разработчикам выбирать чиплеты под конкретный класс задач: «Наша конечная цель — создать рынок чиплетов. Мы сосредоточились на том, чтобы создать открытый стандарт, который позволит чиплетам „разговаривать“ друг с другом. Чтобы они работали как один чип, между чиплетом и пакетом должен быть логический интерфейс».
По его словам, цель проекта ODSA состоит в том, чтобы к началу IV квартала этого года подготовить новый логический интерфейс, а затем изготовить на его базе тестовые чипы. Если расчет себя оправдает, то мы станем свидетелями появления на рынке продуктов, которые подготовят фундамент для становления нового класса чипов. «С учетом того, что цикл проектирования составляет порядка