













С недавних пор во многих компаниях, прежде всего крупных, стали чаще обращать внимание на накопленные за годы работы данные. С внедрением систем искусственного интеллекта они стали открывать для себя дополнительную ценность ранее собранной информации. Она используется для оптимизации не только бизнеса, но и работы инфраструктуры. Раскрыть скрытый потенциал данных помогают алгоритмы машинного обучения (machine learning, ML).
Лямбда-архитектура
Эффективная подготовка потока входных данных для аналитической обработки является важной составляющей любого механизма ML. Самым простым решением будет вести обработку входящего потока. Однако для многих прикладных задач требуется получать аналитику в реальном времени (или небольшой задержкой). В этом случае все оказывается не так просто.
Главная проблема состоит в том, что системы собирают все доступные данные, в том числе не нужные для аналитики, а сами входящие данные поступают неочищенными. Запросы от аналитических систем будут вызывать в этом случае повышенные затраты вычислительной мощности, а длительность задержки в получении результата будет неопределенной.
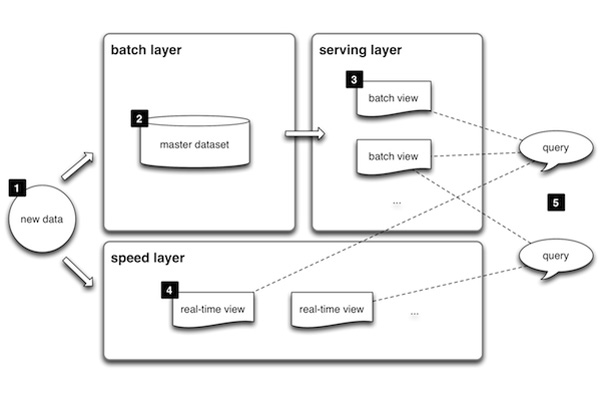
Решения этой проблемы можно добиться благодаря использованию т. н. «лямбда-архитектуры». Идея этого метода заключается в том, чтобы одновременно направлять поток входящих данных на два уровня и осуществлять на каждом из них раздельную обработку — «пакетную» (batch) и «ускоренную» (speed).
Пакетный уровень служит для хранения данных и их неспешной (не в режиме реального времени обработки) обработки по заданным алгоритмам в угоду глубине и качеству. В некоторых моделях готовые результаты передаются на сервисный (serving) уровень, выдающий представления (views) данных по запросам от аналитических систем.
На ускоренном уровне осуществляется клиринг данных, но он ограничивается минимальной обработкой. Зато данные становятся доступными для аналитических запросов практически в реальном времени.
Механизм лямбда-архитектуры может применяться и для ИТ-инфраструктуры. Если осуществлять сбор характеристик со всех узлов, включая элементы гиперконвергентной инфраструктуры, то с помощью выстроенной
Однако у лямбда-архитектуры есть и свои недостатки, связанные с ее внутренней сложностью. Очень непросто и недешево обеспечить необходимую логику обработки данных сразу по двум направлениям.
Каппа-архитектура
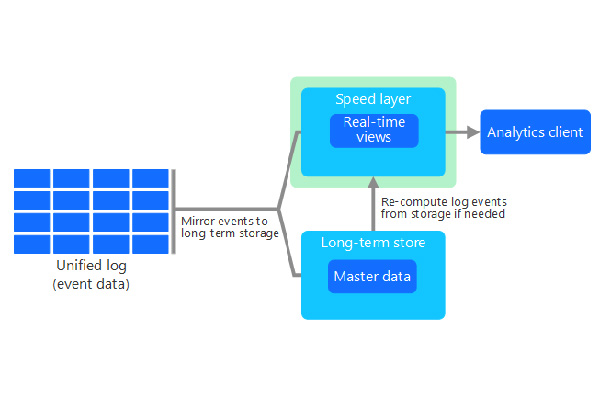
Альтернативное решение под названием «каппа-архитектура», нацеленное на устранение недостатков, присущих лямбда-архитектуре, предложил Джей Крепс, сооснователь и CEO компании Confluent, один из создателей платформы Apache Kafka. Его главное отличие состоит в том, что обработка потока входящих данных ведется в рамках одного направления их перемещения.
Как и у «лямбды», входящие данные зеркалируются. Данные, попавшие в основной поток, не корректируются; сразу формируются представления из хронологически упорядоченных данных, и это происходит в реальном времени. Совокупность создаваемых данных формирует единый журнал, который записывается в распределенной и отказоустойчивой форме.
Параллельно также ведется обработка зеркального потока входных данных. На их основе формируется мастер-копия, данные в которой подвергаются анализу. Если обнаруживается необходимость в коррекции, то происходит инициализация пересчета наборов, подготовленных на выходе.
Альтернативные решения на базе Apache
Сложная и ресурсоемкая модель лямбда-архитектуры часто заставляет компании искать взамен более простые решения. Выбор в этом случае может быть связан с использованием разработок Apache Foundation.
Один из вариантов — применять асинхронные вычислительные среды для обработки потоковых данных. Это позволяет получать результаты с малой задержкой, приближенной к реальному времени. Такую возможность предоставляет фреймворк Apache Samza, созданный на базе Scala и Java; он подключается к распределенному брокеру сообщений Apache Kafka.
Другой вариант связан с делением потоковых данных на микропартии для самостоятельной обработки. В этом случае применяют платформу Batch вместе с Apache Spark Streaming. Такое решение также обеспечивает умеренные задержки (около 1 с).
Есть также сведения о применении расширения Trident, представляющего собой высокоуровневую абстракцию поверх фреймворка Apache Storm. Этот механизм обеспечивает обработку потоков в виде небольших пакетов и осуществляет пакетное агрегирование, реализуя тем самым распределенные потоковые вычисления.
Специализированные чипы
Решить проблему устранения слишком длинных задержек при интеграции ML позволяет использование программируемых интегральных микросхем (FPGA). В отличие от традиционных, использующих встроенную («прошитую») логику для обработки данных, алгоритмы обработки в микросхемах FPGA задаются путем их программирования. Для записи требуется специальный программатор и умение работать в IDE.
Программируемые микросхемы FPGA давно используются в электротехнике. Однако до недавнего времени они оставались в тени. Их широкому распространению мешала сложность отладки созданных на их базе продуктов, поскольку требовалось программирование на низком, аппаратном уровне.
Рост популярности начался в 2015 г. Тогда Intel купила за 16,7 млрд. долл. одного из главных производителей FPGA — компанию Altera. Следом появился пакет Intel FPGA SDK для OpenCL, благодаря которому разработчики смогли создавать ускорители на базе FPGA, применяя их для улучшения характеристик стандартных процессоров. Немного позднее Intel анонсировала выпуск эталонного дизайна нейронной сети для систем глубокого обучения, реализовав прототип на FPGA-моделях Stratix и Arria.
Выбор FPGA для ML диктуется двумя достоинствами этой технологии. Во-первых, для работы микросхем FPGA не требуется применять ОС общего назначения (Windows, Linux) — они являются главными «виновниками» больших задержек при работе ML. Во-вторых, в FPGA может быть использована «особая» поддержка для операций с плавающей запятой, являющейся важной составляющей в работе алгоритмов ML.
Преимущество FPGA над универсальными процессорами возникает благодаря тому, что в задачах ML не требуется высокая точность в расчетах. FPGA могут выполнять операции с плавающей запятой, например, с
Контейнеризация для ML
Контейнеризация — это программный механизм, обеспечивающий виртуализацию и изоляцию системных ресурсов и позволяющий запускать приложения и необходимый минимум системных библиотек в стандартизованном изолированном окружении (контейнере). Связь с «внешним миром» (хостом) осуществляется через интерфейсы, гарантируя полный контроль над изолированностью процессов внутри контейнера.
Контейнеры обычно применяют для запуска бизнес-приложений, требующих интенсивных вычислений. Но аналогичная задача возникает и для ML на этапе обучения их алгоритмов. Используя контейнерную обработку, можно провести обучение заранее, обеспечив относительно скромные запросы на вычислительные ресурсы на этапе эксплуатации ML.
Среди примеров использования контейнерной обработки для ML можно выделить проект Google TensorFlow. Эта разработка началась в 2011 г. в Google Brain, подразделении Alphabet. Первоначально этот проект рассматривался как создание закрытой
В 2016 г. Google выпустила аппаратный ускоритель, получивший название «тензорный процессор» (TPU). Он был адаптирован под решение задачи глубинного обучения для TensorFlow, обеспечивая высокую производительность при использовании
Самая веская причина при выборе контейнеров TensorFlow для ML — это их готовность к масштабированию. Технология в нынешнем виде поддерживает формирование кластеров TensorFlow, по которым можно распределять нагрузку, возникающую при обработке вычислительных графов, практически без ограничений.
Промышленные примеры применения ML для управления ИТ-инфраструктурой
Dell EMC. В 2018 г. компания выпустила линейку систем хранения PowerMax. Уже на старте они были названы «самыми быстрыми массивами хранения данных в мире». Согласно спецификации, PowerMax действительно обладает уникальными характеристиками. Ее производительность достигает 10 млн. IOPS, пропускная способность — 150 Гб/с, время отклика сократилось на 50% по сравнению с традиционными системами. PowerMax хорошо работает как с большими данными, так и с транзакционными нагрузками, обеспечивает высокую производительность для виртуальных машин и пр.
Высокая производительность PowerMax во многом, конечно, связана с переходом на новое поколение носителей данных, использующих протокол NVMe. Но существенный вклад также вносит применение алгоритмов ML. Они используются, в частности, для автоматизации обработки потоков ввода-вывода и интеллектуального размещения данных в хранилище. Применяя ML, данные на входе ассоциируются с ожидаемым спросом и размещаются на носителе (флэш или устройства хранения Class Memory), который наиболее подходит с учетом выбора ИИ. Все происходит автоматически, поэтому даже без настройки PowerMax позволяет выстраивать высокопроизводительные хранилища, сам управляет политиками переноса данных и осуществляет балансировку рабочей нагрузки.
Hewlett Packard Enterprise. Компания предлагает применять ML для интеллектуального размещения данных в гибридном облаке. Как правило, выбор места для размещения данных в этом случае возлагается на ИТ-отдел. Там вручную отслеживают эффективность работы систем хранения в корпоративном хранилище ЦОДа и на хостингах в публичных облаках, перемещая затем массивы данные в случае выявления проблем.
В HPE предложили управлять инфраструктурой с использованием ИИ: HPE InfoSight анализирует в реальном времени рабочие нагрузки используемых систем хранения и обеспечивает перемещение данных в оптимальное место с учетом различных показателей: стоимости хранения, производительности, близости к заказчику, доступной емкости. Рост надежности и качества предсказаний, которые делает HPE InfoSight, достигается за счет непрерывного обучения алгоритмов ML.













