В ходе клинических испытаний лекарственных препаратов или вакцин исследователи обрабатывают колоссальные объемы разнообразных данных из многочисленных источников. Гибкая архитектура данных может сократить время разработки и выпуска препарата на рынок.
«Скорость света» — так назывался проект разработки и вывода на рынок вакцины от COVID-19 в рекордные сроки. Однако наличие исключительных инициатив подобного рода не должно скрывать того факта, что обычно разработка новых препаратов происходит очень медленно. В среднем от идеи до первого утверждения проходит 13 лет. Ключевая проблема — огромный объем и разнообразие децентрализованных данных, которые необходимо анализировать в строгом соответствии с законом и отраслевыми стандартами.
Проблема анализа данных
Объем исследовательских данных в фармацевтических компаниях уже давно достиг петабайтных значений. В дополнение к сложности работы с такими массивами, существует проблема обработки невероятно разнообразного потока данных. Наряду с неструктурированными данными (фотографии, рентгеновские снимки, снимки компьютерной томографии и т. д.) есть также структурированные данные в виде фармакодинамических измеряемых величин (дозировка, анализы крови, печеночные пробы и др.). Кроме тестовых результатов, полученных на итеративных этапах исследования, нужно работать также с персональной информацией об испытуемых и пациентах, данными из разных организаций и сравнением с уже полученными результатами исследований. И всё это необходимо делать для сотен или даже тысяч субъектов. На фазе исследований, которая направлена на выявление очень редких побочных эффектов препарата уже после его внедрения на рынок, могут участвовать десятки или сотни тысяч человек.

Такие данные собираются в нескольких организациях. В ходе испытаний фармацевтические компании взаимодействуют с разными партнерами: от университетов до частных исследовательских центров. Следовательно, существуют особые требования к хранению, доступу, распространению и анализу данных. В частности, исследовательские компании и учреждения иногда из разных государств должны иметь совместный доступ к данным, соответствующий правилам безопасности.
Кроме того, критически важно оценить объем массива данных как можно быстрее, чтобы ускорить вывод препарата на рынок. Однако ни одна вычислительная платформа не подходит в равной степени для всех рабочих нагрузок. С одной стороны, высокопроизводительная вычислительная система (HPC) со стандартными процессорами (ЦПУ) будет оптимальной для фармакокинетического моделирования с помощью отраслевого программного обеспечения NONMEM7. С другой, анализ с использованием машинного обучения с Hadoop и Spark выполняется быстрее при помощи графических процессоров (ГПУ).
Потребность в новой архитектуре данных
Исследовательским организациям нужна архитектура данных, которая предназначена для гибкого объединения массивов данных с наиболее подходящими вычислительными мощностями — вне зависимости, используются ли стандартные процессоры или графические, ЦОД фармацевтической компании или компании-партнера или вовсе облако.
Архитектура данных должна быть легко масштабируемой и способной логически объединять разнородные, глобально распределенные базы данных в озеро данных с единым пространством имен во всех локациях. С ее помощью исследовательские группы из различных организаций получают совместный доступ к массивам данных — но только к той информации, к которой у них есть допуск. Необходимыми предварительными условиями являются мультитенантность и единая модель безопасности. Многоплатформенная гибкость возможна только при условии безопасности, трассируемости и целостности данных.
Возможность перемещения приложений между средами высокопроизводительных вычислений может пригодиться при привлечении внешних подрядчиков во время критических нагрузок и несет в себе невероятные преимущества. Предпочтительным методом здесь будет контейнеризация, в рамках которой приложения запускаются в защищенных средах (контейнерах), близких к операционной системе. Это позволяет быстро настраивать и демонтировать среды и обеспечивает корректную миграцию рабочих нагрузок, например, в облако и обратно. В контейнерной среде у компании есть единый доступ ко всем библиотекам и взаимозависимостям без необходимости индивидуального управления каждой платформой. Это очень удобно, если сервисы динамически создаются в облаке, а затем удаляются.
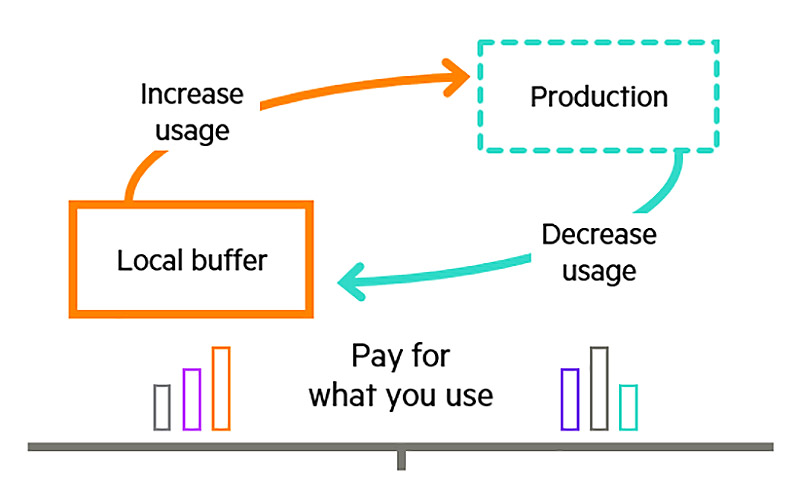
С точки зрения расходов, еще один фактор может привести к значительному прогрессу в работе фармацевтических компаний — ИТ-провайдеры начинают предоставлять аппаратные ресурсы (компьютеры, хранилища, сети) в качестве услуги не только через облако, но и на территории заказчика. Модели лицензирования по требованию позволяют предприятиям получать мощности в кратчайшие сроки и оплачивать их по факту использования. Таким образом, гибкость публичного облака становится доступной в корпоративном ЦОДе.
Практический пример
Для фазы клинического исследования, выполняемого двойным слепым методом на 2 тыс. испытуемых, университетская лаборатория использует установленный на своей территории высокопроизводительный вычислительный кластер, оптимизированный для приложений внутреннего анализа данных. Несколько специализированных центров получают разрешение на пополнение определенных наборов данных собственными результатами лабораторных исследований через удаленный доступ. Более того, для оценки снимков компьютерной томографии с помощью ИИ университетская лаборатория использует временно активированные мощности систем на базе графических процессоров. Однако для статистического сравнения с результатами предыдущей фазы исследования и поиска аномалий она запускает приложение машинного обучения на развернутом частном облаке у местного провайдера услуг.
В этом сценарии экономят время два фактора. Это использование наиболее подходящей вычислительной среды в каждом конкретном случае, а также возможность выполнять рабочие этапы с помощью внешних ресурсов и, следовательно, параллельно, но без потерь в производительности и в соответствии с нормами и правилами. Положительным побочным эффектом будет сохранение контроля над расходами благодаря лицензированию набора сервисов по требованию. Поскольку в этом случае нет необходимости в крупных первоначальных инвестициях в системы высокопроизводительных вычислений, как это было раньше.
Быстрый вывод продуктов на рынок
Правильно выстроенная архитектура данных может значительно сократить время вывода лекарств и вакцин на рынок — в идеале, в сочетании с тремя другими факторами. Во-первых, это контейнеризация, которая делает приложения доступными в нужной локации и помогает избежать перегрузки локальных систем высокопроизводительных вычислений. Во-вторых, многопользовательская архитектура безопасности для совместной работы исследовательского сообщества. И третий фактор — оплата вычислительных и сетевых ресурсов, а также хранилищ по факту использования. При таком подходе фармацевтическая компания может быстрее монетизировать результаты своих исследований и получать выгоду в течение более продолжительного времени, так как период эксплуатации до истечения срока патента увеличивается. Ускорение вывода на рынок новых препаратов — это не что-то очень сложное, а скорее результат инновационных концепций поиска ресурсов и интеллектуальной архитектуры данных.
Автор статьи — специалист по продажам высокопроизводительных вычислительных систем и систем искусственного интеллекта, Hewlett Packard Enterprise в России.