













Предложенный стандарт использует интеллектуальность Web-браузеров для балансировки загрузки запросов к URL между серверами-представителями
Включение в состав сети сервера-представителя является одним из простейших способов увеличения ее надежности и производительности, однако повышение производительности перегруженного сервера-представителя - задача далеко не простая. Для ее решения предложен стандарт, позволяющий администраторам для ускорения работы сети создавать массивы серверов-представителей.
Предложенный корпорациями Microsoft и Netscape Communications стандарт CARP (Cache Array Routing Protocol - протокол маршрутизации на базе кэш-массива) использует растущую интеллектуальность Web-браузеров для балансировки загрузки с помощью группы серверов-представителей.
Протокол впервые будет реализован в продукте Proxy Server 2.0 корпорации Microsoft, который должен выйти в этом году, но если администраторы согласны собственноручно заняться программированием на JavaScript, то они должны уметь использовать CARP в работе с любым сервером-представителем. Ни одному из серверов-представителей не нужно даже “знать” о том, что он входит в состав массива, так как вся маршрутизация происходит на клиенте.
Основные положения технологии серверов-представителей
Серверы-представители функционируют в качестве посредников между Internet и отдельными пользователями. Они сохраняют данные, полученные из Internet, и последующие запросы этих же данных могут обслуживаться локально, без участия более медленного сетевого соединения.
Используя CARP, администраторы могут смягчить проблему перегрузки серверов-представителей, просто увеличивая их число. Трафик клиентских запросов и хранящиеся в кэш-памяти данные затем распределяются по набору серверов. Для клиентов массив кэш-серверов будет выглядеть, как один сервер-представитель, только более крупный и быстрый.
CARP улучшает предыдущий стандарт для наборов серверов-представителей, называемый ICP (Internet Caching Protocol - протокол кэширования для Internet), поскольку он лучше масштабируется. ICP определяет, что серверы-представители посылают друг другу запросы каждый раз, когда клиент обращается к любому из серверов. Запросы используются для того, чтобы определить, нет ли уже требуемых данных на другом сервере, прежде чем извлекать их из Internet.
Однако по мере роста количества серверов-представителей в массиве соответственно растут и накладные расходы, связанные с такими запросами. Кроме того, ICP не позволяет набору эффективно использовать память, поскольку через некоторое время все серверы внутри него начинают сохранять одни и те же данные, становясь зеркальными копиями друг друга.
Вместо запросов CARP применяет для перенаправления запроса нужному серверу-представителю в первую очередь сценарии клиентской части, что исключает потребность в ICP-запросах.
Последние версии Web-браузеров Microsoft и Netscape позволяют администраторам автоматически конфигурировать эти браузеры так, чтобы они обращались к определенным серверам-представителям.
Оба браузера можно сконфигурировать и так, чтобы они использовали функцию на базе JavaScript для пересылки запросов различным серверам-представителям, в зависимости от местоположения сетевого ресурса. Например, запрос к документу на узел www.microsoft. com мог бы пойти одному серверу-представителю, а аналогичный запрос к адресу www.zdnn.com - другому.
Эта простая форма маршрутизации и лежит в основе CARP.
Первым шагом в применении CARP является создание Proxy Array Membership Table (таблицы участников массива представителей). Эта таблица представляет собой просто текстовый файл, содержащий список имен и IP-адресов каждого сервера-представителя, входящего в массив. Каждый элемент может включать необязательный параметр, называемый коэффициентом загрузки, с помощью которого администраторы могут распределять запросы в массиве не равномерно, а в зависимости от емкости памяти каждого сервера.
Хотя серверы-представители, поддерживающие CARP, например тот, который готовит к выпуску корпорация Microsoft, автоматически создают и сопровождают эту таблицу, формат таблицы достаточно прост для ее создания вручную. Кроме того, администраторам не нужно беспокоиться по поводу того, какой из серверов какие Web-узлы обслуживает, так как, начиная обрабатывать запросы к URL, CARP автоматически делает назначения.
Следующий шаг - написание на JavaScript функции с именем FindProxyForURL, реализующей протокол маршрутизации CARP. И опять сервер-представитель, поддерживающий CARP, может создать этот сценарий автоматически, но его можно написать и вручную, опираясь на спецификацию CARP как на справочник.
Последним шагом является конфигурирование браузеров для скачивания таблицы и JavaScript-функции при первом подключении к сети. Описанная процедура слегка различается для разных браузеров, но ясно изложенная информация по этому вопросу имеется на Web-страницах Microsoft и Netscape.
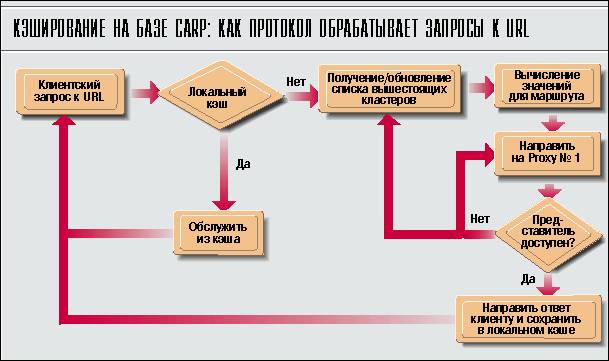
Будучи единожды сконфигурированными под протокол CARP, Web-браузеры используют функцию FindProxyForURL для маршрутизации запросов среди входящих в массив серверов-представителей. Когда пользователь вводит URL с клавиатуры или щелкает мышью на ссылке, URL сначала передается определенной функции, и указанный ею сервер-представитель обрабатывает сетевой запрос.
Целью маршрутизирующей функции является максимально равномерное распределение запросов среди серверов-представителей из массива. Одновременно она должна быть и детерминистской - это означает, что запросы к одному и тому же URL с различных браузеров должны направляться на один сервер-представитель.
Такую детерминистскую маршрутизацию CARP выполняет на основе алгоритма хэширования. Сначала URL преобразуется хэш-функцией в число. Эта функция циклически сдвигает биты каждого символа на 19 позиций и складывает их. Имя каждого элемента массива представителей тоже хэшируется аналогичным способом. Полученные два числа объединяются, образуя некоторый рейтинг (score) для каждого элемента массива. Наконец, рейтинги объединяются с упомянутым ранее коэффициентом загрузки; элементы с более высоким коэффициентом загрузки получат для каждого URL в среднем и больший общий рейтинг.
Когда маршрутизирующая функция заканчивает работу, браузер использует для обработки URL элемент массива представителей с максимальным рейтингом. Предположим, например, что пользователь пытается соединиться с www.pcweek.com. Когда его браузер обнаруживает, что сервер-представитель B имеет наивысший рейтинг, он пошлет запрос туда. Если второй пользователь попытается соединиться с тем же узлом, его браузер тоже обнаружит сервер B в качестве имеющего максимальный рейтинг и пошлет запрос этому серверу. В последнем случае сервер-представитель B найдет страницу, уже имеющуюся в его кэше (поскольку первый пользователь ранее запрашивал ее), и обслужит с ее помощью второго пользователя.
Если происходит отказ сервера с максимальным рейтингом, браузер обращается ко второму по рейтингу элементу массива, который обработает запрос URL и начнет кэшировать данные. Это, однако, по-прежнему не ведет к дублированию кэшированных данных, так как машина, ранее обрабатывавшая запросы к этому URL, больше не является частью массива.
Почему это работает
Через некоторое время все регулярно запрашиваемые сетевые ресурсы сохранятся в кэш-памяти входящих в массив серверов, причем без дублирования. Если некоторый сервер обрабатывал запросы к www.yahoo. com, он всегда будет обрабатывать запросы к этому URL (в предположении, что сервер продолжает функционировать и администратор не переконфигурировал массив). Даже если администратор добавляет или исключает машины в массиве, на другие машины будет перенаправлена лишь небольшая часть трафика. Например, при добавлении четвертой машины в трехсерверный массив на другую машину перейдет меньше трети запросов. Это происходит потому, что серверы, уже входившие в массив, будут иметь наивысшие рейтинги для регулярно запрашиваемых URL.
Некоторые Web-узлы и документы обязательно окажутся популярнее других, что вызовет определенную неравномерность загрузки. Тем не менее загрузка останется почти равномерной, так как хэшируется URL в целом, а не только содержащееся в нем имя машины. Например, home.netscape.com будет обрабатываться каким-то одним сервером в массиве. Однако другие URL на том же Web-узле (скажем, home.netscape.com/ download/index.html) могут обслуживаться другим сервером.
Как только в серверы-представители будет встроена поддержка CARP, администраторы получат еще большую гибкость. Например, Microsoft Proxy Server 2.0 может использовать CARP напрямую, так что появляется возможность создания иерархических кэширующих массивов. С помощью САПР сервер-представитель в дочернем офисе сможет посылать запросы к массиву, расположенному в головной конторе организации.
Серверы-представители, поддерживающие CARP, упростят конфигурирование клиента. Браузеры могут быть сконфигурированы так, чтобы посылать запросы к одному серверу-представителю, который затем через CARP перешлет запросы к массиву.
Имонн Салливан (PC Week Labs)













