













В предыдущих статьях мы выяснили , как организовать хранилище в облаке Amazon и запустить виртуальный сервер. Однако данная схема ненамного отличается от типового предложения Virtual Private Server (VPS) обычных хостинг-провайдеров.
Большинство классических облачных проектов подразумевает использование десятков, сотен, тысяч однотипных виртуальных машин, решающих единую задачу в распределённом режиме. По такой модели строится работа крупнейших поисковиков, социальных сетей и т. п. В этом одно из принципиальных отличий облачной архитектуры от клиент-серверной, когда можно арендовать единичные VPS-серверы или выделенные физические серверы, каждый из которых будет отвечать за оригинальную функциональность (поддержка базы данных, сервер приложений, прокси-сервер). Вручную администрировать систему из сотен ОС практически нереально, но то же время при использовании облачной платформы желательно избежать лишних расходов на какие-то дополнительные организационно-технические мероприятия.
В процессе оптимизации прикладной облачной системы следует выделить два принципиальных момента: обеспечение качественной работы сетевой составляющей (решение проблем с безопасностью и нагрузочным трафиком) и балансировка нагрузки на облачные серверы. Рассмотрим их по порядку.
Связываем свой ЦОД с Amazon
Выделенное соединение своего ЦОДа или офиса с облаком Amazon (сервис AWS Direct Connect) имеет смысл, когда, например, провайдер предлагает своим клиентам в числе прочих взаимодействие с облаком Amazon или даже использует его незаметно для пользователей, фактически перепродавая чужие ресурсы. AWS Direct Connect очень полезен и в случае, когда в организации разворачивается гибридная архитектура, но выходить в Интернет нежелательно или же внутренние политики безопасности блокируют доступ к облаку из VPN.
AWS Direct Connect предоставляет частное корпоративное соединение с сервисами Amazon с хорошей пропускной способностью до 10 Гбит/с через оптоволоконный Ethernet, подключаемый непосредственно к роутеру пользователя. За данный сервис потребуется платить ежечасно от 0,03 долл. за линию 10 Мбит/с, 0,3 долл. за 1 Гбит/с и 2,25 долл. за 10 Гбит/с. Кроме того, оплате подлежит исходящий трафик — около 0,03 долл./Гб.
Создаём виртуальное частное облако
Внутрикорпоративное назначение имеет и сервис Amazon Virtual Private Cloud (VPC) — виртуальное частное облако, которое расширяет пользовательский ЦОД облачными серверами Amazon, которым можно назначить IP-адреса из внутренней сети. Данный вариант представляется компромиссным решением между открытой гибридной архитектурой, когда внешние ресурсы подключаются через Интернет по своим публичным IP-адресам, и полностью закрытой. Так, корпорация Shell изнемогала под гнётом “сырых” данных: каждая нефтяная скважина, оснащённая инновационным набором датчиков, генерирует петабайт информации, а таковыми комплектами оборудуются тысячи скважин. Обрабатывать их решили в облаках через Virtual Private Cloud в движке Hadoop.
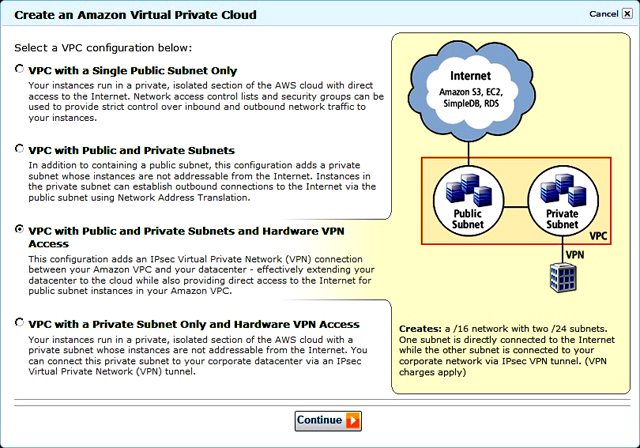
Работа через VPC-сеть технически не отличается от прямого взаимодействия с эластичными серверами EC2, только предварительно в рамках аккаунта надо выделить часть доступных ресурсов в VPC. Схемы формирования гибридной модели VPC предлагаются самые разные, из них несложно выбрать наиболее подходящую, например несложную для тестирования, когда в облаке Amazon создаётся только одна подсеть (диапазон IP-адресов, связанный с VPC) или же несколько, причём с привязкой к аппаратной реализации локальных VPN-сетей (рис. 1).
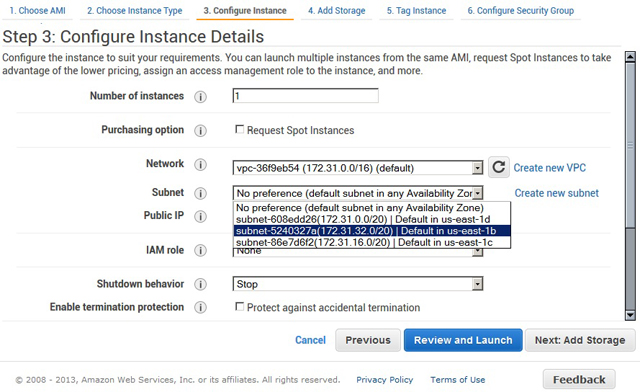
Для созданной сети можно настроить группы безопасности (задаются порты для различных видов трафика). В итоге новые виртуальные серверы EC2 будут запускать уже внутри сформированной VPC. В будущем на этапе конфигурирования серверного экземпляра EC2 будет предложено выбрать подходящие VPC-сеть и подсеть (по умолчанию одна VPC-сеть создаётся автоматически, и удалять её не рекомендуется). При необходимости серверу можно назначить эластичный IP для открытого доступа к нему из Интернета, а пользователь Amazon может обращаться к серверу также по внутреннему IP-адресу VPC-сети и подключать его к собственной внутренней сети (рис. 2). При удалении VPC-сети предварительно надо удалить все запущенные внутри неё серверные экземпляры.
Доменные имена и Route 53
Поддерживает Amazon и собственную службу доменных имён DNS (привязка IP-адреса к имени домена или поддомена) под названием Route 53. Она предоставляет удобный программный интерфейс, позволяя, например, автоматически и оперативно перебрасывать IP-адрес на запасной сервер, если первый не справляется с нагрузкой (без такой подстраховки пользователи получат некрасивое сообщение “Сервер не найден”). Route 53 также проверяет доступность доменного имени: сервис Health Check периодически обращается к публичному DNS-имени из разных точек планеты, фиксируя временные задержки. Если таковые выявлены, из консоли Route 53 можно настроить перенаправление посетителей на вторичный alias-ресурс — например, статический веб-сайт, расположенный в хранилище S3. Обойдётся сервис Route 53 в 0,5 долл./мес на 25 зон хостинга и в такую же сумму на 1 млн. запросов к записям DNS. Стоимость проверок Health Check составляет 0,5 долл./мес на каждую контролируемую точку.
Балансируем нагрузку на серверы
Когда в систему из сотен серверов поступают интенсивные запросы от пользователей, сервисом Route 53 не обойдёшься: требуется особый “менеджер”, который будет корректно распределять запросы, не перегружая уже занятые расчётами серверы. Подобную архитектуру можно реализовать и своими силами, однако лучше воспользоваться готовым решением Elastic Load Balancing (ELB), так как оно тесно интегрировано с остальными “кубиками” конструктора Amazon. ELB автоматически распределяет входящие обращения пользователей между серверами EC2. При этом балансировщик ELB способен выявлять отключённые экземпляры и оптимизировать нагрузку на систему в целом с учётом физического расположения ЦОДов, где работают виртуальные серверы. Для обеспечения дополнительной безопасности можно задействовать VPC, когда трафик перераспределяется между приватными IP-адресами внутри собственной виртуальной сети.
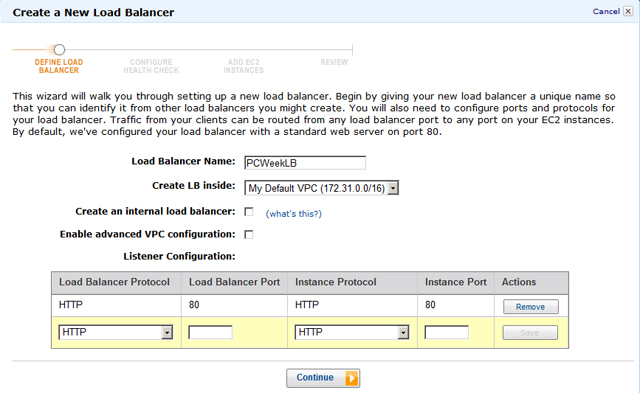
Использование ELB начинается с создания балансировщика нагрузки (подразумевается, что ранее уже подготовлены и запущены виртуальные серверы EC2). В консоли экземпляров EC2 выбирается пункт главного меню Load Balancers, после чего мастер ELB предложит создать балансировщик: в окне появится единственная кнопка Create Load Balancer. Далее надо указать произвольное название балансировщика, при желании выбрать VPC-сеть и проверить, доступен ли 80-й порт на серверах EC2 — через него будет происходить взаимодействие с сервисом ELB (рис. 3).
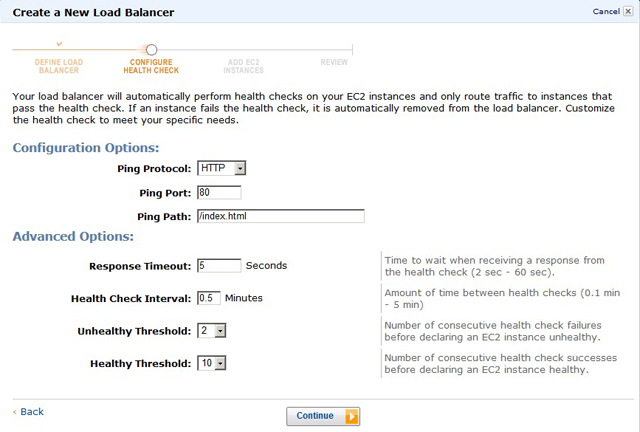
Проверка работоспособности каждого серверного экземпляра осуществляется периодическим опросом указанного пути. Как правило, задаётся заглавная или тестовая HTML-страничка, если сервер реализует функциональность сайта, или порт, к которому подключён сервер приложений, если используется протокол опроса TCP (рис. 4).
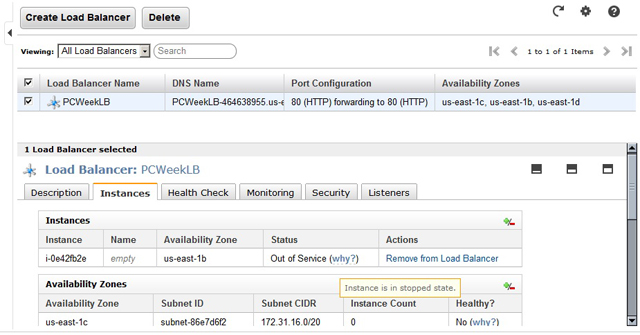
На следующих шагах выбираются группы безопасности и указывается список серверов, подлежащих балансировке. В завершение нажимается кнопка Create, балансировщик запускается и через некоторое время начинает контролировать работу подведомственных серверов. При этом доступна подробная информация о функционировании сервиса ELB и выявленных проблемах (рис. 5).
В бесплатном режиме доступно 750 ч работы ELB и 15 Гб трафика мониторинга. В дальнейшем 1 ч работы балансировщика обойдётся в 0,028 долл., а 1 Гб трафика в 0,008 долл.
Масштабируем нагрузку по горизонтали
Как уже отмечалось, классическая задача облачной системы — это динамическое масштабирование под меняющуюся нагрузку. Оно может быть вертикальным, когда “на лету” модифицируются мощности ограниченного числа серверов, или горизонтальным, когда под очередную дополнительную порцию запросов запускается новый сервер типовой конфигурации. Горизонтальное масштабирование в Amazon реализуется с помощью веб-сервиса Auto Scaling, предназначенного для автоматического запуска или останова серверов EC2 в зависимости от текущей нагрузки, а также от определённых пользователем условий и расписания. В частности, Auto Scaling позволяет масштабировать систему динамически (подстраиваясь под нагрузку) или прогностически (когда хорошо известны пики нагрузки и можно задавать старт дополнительных ресурсов в указанное время дня, недели или месяца). При этом можно достичь хорошей экономии за счёт оперативного отключения неиспользуемых серверных экземпляров.
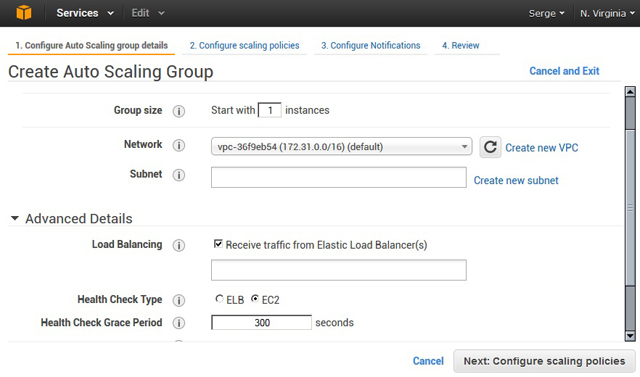
Для запуска Auto Scaling надо подготовить группы для решения прикладных задач, в которых будет определено минимальное, максимальное и рекомендованное число работающих серверов. Каждая группа получает также свою конфигурацию запуска, определяющую специфику используемых серверов. Кроме того, необходимо создать план масштабирования: именно он определит, когда и как будут работать механизмы горизонтального масштабирования. Auto Scaling дополнительно проследит за состоянием каждого экземпляра и при необходимости перезапустит “зависшие” серверы.
Сервис Auto Scaling доступен из главного меню консоли управления серверами EC2. На первом шаге надо выбрать пункт Launch Configuration и нажать единственную кнопку Create Auto Scale group. Двигаясь по шагам, знакомым по методу создания сервера EC2, выбираем подходящий дистрибутив AMI, на основе которого формируется текущая группа, задаём его тип и название. Можно также уточнить способ тестирования здоровья элементов группы — по отклику серверов EC2 или по доступности хранилища EBS (рис. 6). При желании можно использовать и более сложные пользовательские правила управления работой экземпляров EC2 — для этого надо включить сервис мониторинга CloudWatch, о котором рассказывается ниже. В ранних версиях Amazon функционирование Auto Scaling допускалось только совместно с CloudWatch, но компания выдерживает стратегию на выделение различных сервисов в отдельные независимые модули, предоставляя пользователю гибкий облачный конструктор.
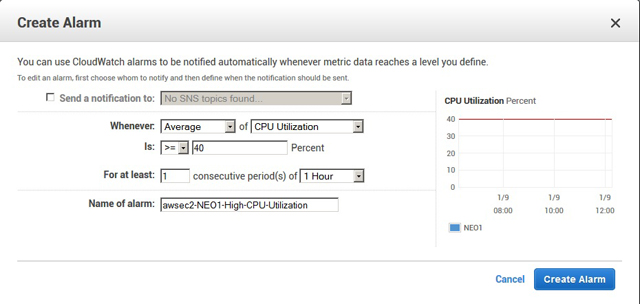
Далее задаём группу безопасности, указываем ключи приватности и в завершение проверяем финальные настройки. Самый важный шаг конфигурирования группы Auto Scaling — это пункт Configure scaling policies. Именно здесь определяется схема масштабирования под меняющуюся нагрузку. Надо выбрать пункт Use scaling policies to adjust the capacity of this group и уточнить, по каким правилам будут запускаться или останавливаться экземпляры EC2. В первой строчке задаётся масштаб группы (в каких пределах она будет масштабироваться по числу серверов). В разделе Increase Group Size надо ввести правило, по которому будет дополнительно запускаться один или несколько новых серверов. Для этого надо нажать на кнопку Add new alarm и ввести требуемые параметры. В примере (рис. 7) задано правило, согласно которому дополнительный запуск серверов произойдёт, когда средняя нагрузка на процессор на протяжении одного часа превысит 40%. Аналогичным способом задаются настройки и в разделе Decrease Group Size.
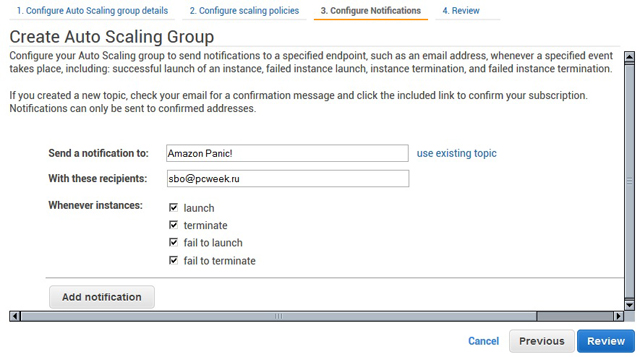
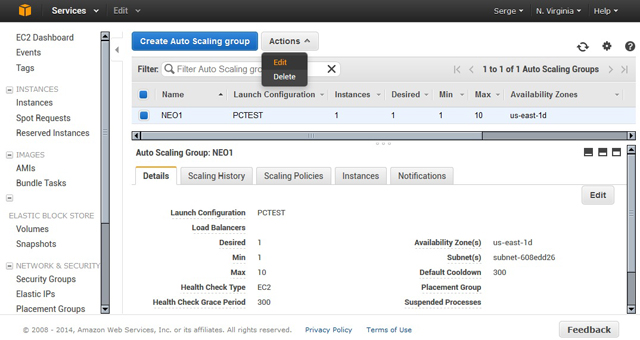
При желании каждое событие группы (запуск или останов сервера или невозможность выполнить эти операции) можно связать с информационным сообщением, которое поступит на указанный э-адрес (рис. 8). В дальнейшем управление группами, их редактирование и удаление, а также контроль за текущим функционированием выполняется из консоли EC2 (рис. 9).
Мониторим ресурсы в реальном времени
Полезным дополнением к упомянутым услугам будет веб-сервис CloudWatch, способный отслеживать доступность ресурсов и состояние прикладных приложений пользователя в реальном времени. Он предлагает набор метрик, в соответствии с которыми будут формироваться предупреждающие сообщения о различных отклонениях системы от рекомендуемой работы. Важно, что использование данных метрик можно связать со службой Auto Scaling — например, запускать новые серверы EC2 по рекомендациям CloudWatch.
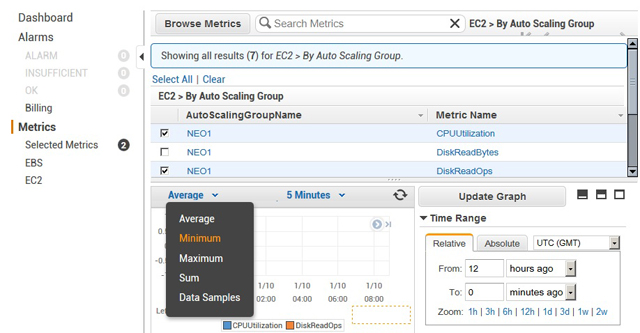
На данный момент доступны 15 метрик, из которых восемь относятся к контролю за эластичным хранилищем данных (количество операций и объёмов ввода-вывода), а семь — к мониторингу работы виртуальных серверов EC2 (нагрузка на процессор, на сеть, на эфемерное хранилище). Последние семь метрик можно также привязывать к группам Auto Scaling (рис. 10).
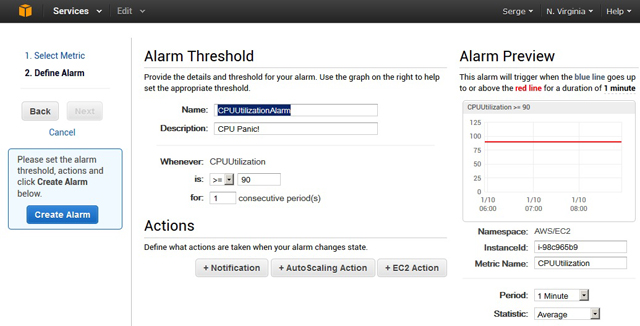
Создание предупреждающего сообщения выполняется выбором пункта Alarms главного меню консоли CloudWatch. После нажатия единственной кнопки Create Alarm надо выбрать подходящую метрику и затем задать ей условие формирования сообщения. На рис. 11 реализована ситуация, когда средняя нагрузка на процессор, в течение одной минуты превышающая 90%, приведёт к формированию события CPUUtilizationAlarm. Это событие можно привязать к рассылкам уведомлений (нижняя кнопка Notification), к балансировке нагрузки с помощью Auto Scaling (кнопка AutoScaling Action), либо к непосредственным операциям над виртуальным сервером кнопкой EC2 Action (останов или удаление экземпляра).













