













Существует немало сценариев, когда требуются незамедлительные решения, принимаемые в реальном времени. Маркетинг на основе определения местоположения клиента, обеспечение безопасности границ, оптимизация в «умных» энергосетях, кибербезопасность и торги на базе интернет-технологий рекламы — это только несколько примеров многочисленных процессов, которые полагаются на решения, принимаемые «здесь и сейчас». И стремительное умножение данных Интернета вещей (IoT) принесет за собой еще более интригующие сценарии использования сиюминутных данных.
С тех пор, как в нашу жизнь вошло понятие промежуточного ПО (middleware), мы слышим о том, что находимся на пороге обработки потоковых данных или событий. Безусловно, технология обработки сложных событий ждала своего решения. Но когда расширение пропускной способности, массовый выпуск серийной аппаратуры и падение цен на оперативную память приблизили к реальности работу с большими данными в реальном времени, мы стали более уверенными. В 2012 г. мы отмечали: «Использование быстрых данных крупными предприятиями для узкоспециализированных потребностей стало менее затратным и почти готово к выходу в мэйнстрим. Как раз ко времени, когда корпорации абсолютно в этом нуждаются». И далее в 2015 г.: «Обработка потоковых данных в реальном времени, машинное обучение и поиск станут наиболее распространенными новыми видами рабочих нагрузок».
Однако оказалось, что завоевать мир приступом у стриминга данных все же не получилось. Консультанты нашей фирмы Ovum получают от корпоративных клиентов массу вопросов по развертыванию машинного обучения и облачных решений. Но лишь немногие клиенты спрашивают нас про стриминг.
Никак не скажешь, что машинное обучение или облака застрахованы от шумихи. Напротив, ее предостаточно. Например, пишется масса заметок о том, смогут ли искусственный интеллект и умные роботы отнять наши рабочие места. Но если отставить в сторону шумиху, результаты внедрения машинного обучения и облачных технологий уже ощутимы. На основе машинного обучения уже работает все больше сервисов для населения и средств аналитики, а использование облачных технологий крупных провайдеров продолжает активно расширяться.
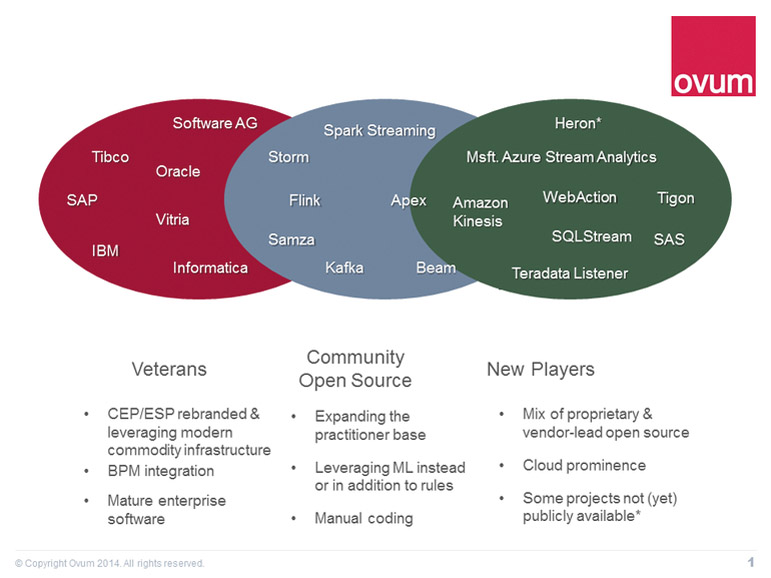
Проблема стриминга состоит в том, что он еще труден для внедрения в рядовых организациях и для понимания людьми бизнеса. Это не связано с дефицитом систем стриминга, соответствующих инструментов или потенциальных сценариев его использования. Суть в том, что стриминг, как правило, все еще является задачей для разработок на заказ. Нет такого продукта, как стриминговая аналитика для розничной торговли, нет и соответствующего продукта для оптимизации сетей. Практически каждый, кто борется за это дело, должен сам заново изобретать колесо.
Однако это не замедляет умножения числа движков стриминга для широкого круга задач от классической обработки сложных событий до стриминга как такового, управления потоками данных и работы с очередями сообщений. Так что дело не в сырых технологиях, а в сбивающем с толку многообразии вариантов выбора.
Один из многих активных игроков рынка, компания DataTorrent, чуть больше года назад перевела свою технологию в категорию Open Source в форме проекта Apache Apex. Как технология, Apex дифференцируется как некая золотая середина: в отличие от Spark Streaming, обрабатывающего события в микросериях, Apex является движком настоящего стриминга, способным обрабатывать события раздельно во времени. Однако создатели Apex заявляют, что он работает с меньшей нагрузкой и большей гибкостью, чем Storm, который отслеживает состояние каждого отдельного события. И, что уникально для движков стриминга, Apex был создан специально для Hadoop со встроенной, а не в виде дополнения, поддержкой YARN.
Коммерческий продукт DataTorrent, платформа RTS, предоставляет визуальную среду разработок для конфигурирования потоков и соединения стриминговых приложений. И хотя Apex, как Open Source-движок стриминга, возможно, не столь на виду, как Spark Streaming, среди заказчиков DataTorrent фигурируют и крупные имена, такие как General Electric (использующая Apex для своей платформы IoT-аналитики Predix) и Capital One. Работая без лишнего шума, DataTorrent за последний год удвоила свой бизнес, что конечно объяснимо очень ранним этапом развития компании, для которого характерен крутой рост.
Благодаря косвенным последствиям присоединения EMC к Dell в команде управленцев DataTorrent появились новые CEO и старший вице-президент по маркетингу. Пришедший на пост CEO Гай Чёрчуард, который ранее возглавлял подразделение хранения данных EMC, реалистически констатирует, что 2017 г. не станет годом прорыва в стриминговой аналитике. По его словам,
С ростом сообщества связано освоение зарождающихся в нем идей, а также накопление критической массы приложений или стартовых шаблонов, которые позволят предприятиям быстрее получать практическую отдачу, чем при нынешнем изобилии сырых технологий и инструментов. В настоящий момент имеется ряд шаблонов, относящихся к подготовке данных и удалению дубликатов.
Работа со стримингом — дело довольно утомительное. Тем не менее, при умножении числа IoT-устройств он становится технологией, которую трудно игнорировать. Если же стриминг в конечном счете будет упакован в форму приложений, игнорировать его станет попросту невозможно.













