Несколько вводных слов
К сожалению, технических материалов по теме довольно мало. В основном в сети представлены видео с презентациями на канале Youtube от разработчиков. Попытки найти хоть какое-нибудь детальное техническое описание архитектуры GridGain или реальную техническую реализацию не приносят результатов. Интернет переполнен рекламой, общими презентациями, ссылками на сайт производителя и статьями о Сбербанке. Ни одного живого кейса миграции на GridGain с разбором плюсов и минусов, решением проблем. Какие-то околотехнические проблемы специалисты пытаются обсуждать на специализированных форумах, но и там информации крайне мало. Очень странно такое видеть для продукта с историей более 11 лет! Мне кажется, вокруг GridGain слишком много шума создано и проведен хороший маркетинг.
Приведенное ниже технологическое описание взято для Apache Ingnite, но оно справедливо и для GridGain.
Что представляет из себя GridGain?
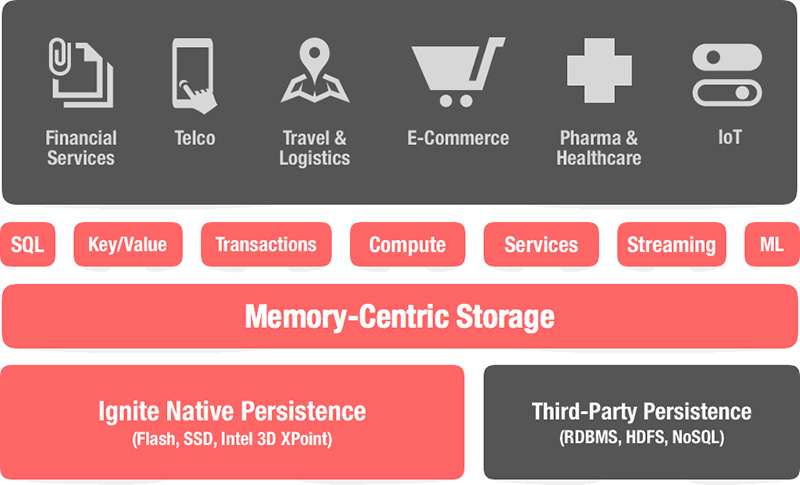
Apache Ingnite (GridGain) — в общих чертах это платформа, написанная на открытом коде и предназначенная для распределенного хранения и вычисления больших объемов данных в кластере узлов.
База данных Apache Ignite использует оперативную память в качестве уровня хранения и обработки по умолчанию, поэтому она относится к классу вычислительных платформ в оперативной памяти (in-memory). Использование уровня дисков является необязательным, но после его включения на дисках будет храниться полный набор данных, тогда как уровень памяти будет кэшировать полный или частичный набор данных в зависимости от его емкости. Apache Ignite может использовать базы данных RDBMS, NoSQL или Hadoop в качестве дискового уровня.
Независимо от используемого API данные в Ignite хранятся в виде пар ключ-значение. Компонент базы данных масштабируется горизонтально, распределяя пары ключ-значение по всему кластеру таким образом, что каждому узлу принадлежит часть общего набора данных. Данные автоматически перебалансируются каждый раз, когда узел добавляется или удаляется из кластера.
Кластер Apache Ignite может быть развернут на обычном сервере, в облаке (Microsoft Azure, AWS, Google Compute Engine) или в контейнерах и средах подготовки: Kubernetes, Docker, Apache Mesos, VMware.
Итак, какой же состав мы можем увидеть из доступной информации по Apache Ingnite?
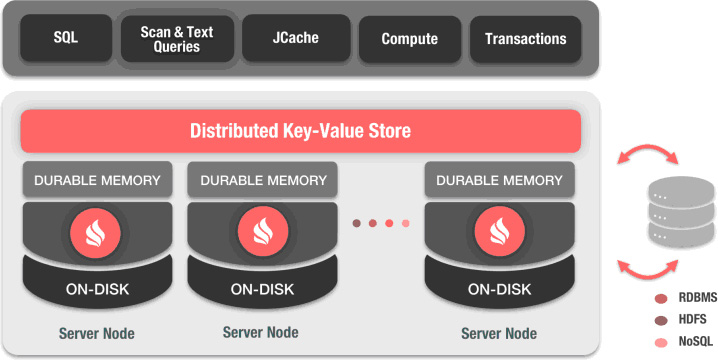
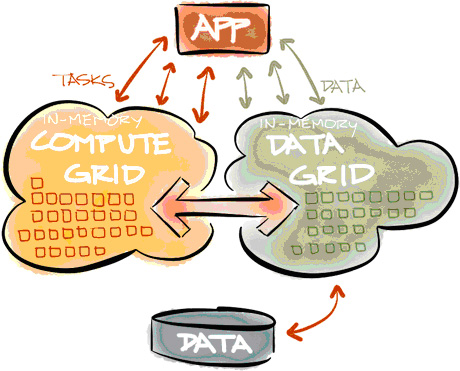
А) Data Grid — это вид in-memory distributed key-value store, который можно рассматривать как распределенную разбитую хэш-карту, причем каждый узел кластера владеет частью общих данных. Таким образом, чем больше добавляемых узлов кластера, тем больше данных мы можем кэшировать. В отличие от других хранилищ для ключей, Ignite определяет местоположение данных с помощью гибкого алгоритма хэширования. Каждый клиент может определить, к какому узлу принадлежит ключ, подключив его к хэширующей функции, без необходимости каких-либо специальных серверов сопоставления или узлов имен.
Особенности:
- распределенное кэширование в памяти;
- быстрая производительность;
- гибкая масштабируемость;
- распределенные транзакции с памятью;
- многоуровневое хранилище;
- распределенные SQL-запросы ANSI-99 с поддержкой Joins.
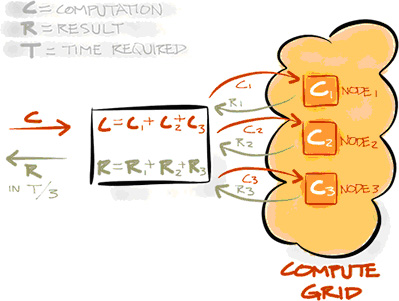
Б) Compute Grid — обеспечивает параллельное выполнение распределенных вычислений, чтобы получить высокую роизводительность, низкую задержку и линейную масштабируемость. Compute grid предоставляет набор простых API, которые позволяют пользователям производить вычисления и обработку данных на нескольких компьютерах в кластере.
Особенности:
- распределенное закрытие;
- MapReduce & ForkJoin-обработка;
- количественное вычисление и данные;
- балансировка нагрузки;
- отказоустойчивость.
Можно объединять Data Grid и Compute Grid, если они являются частями одного и того же продукта и используют одни и те же API. Это снимает с разработчика бремя интеграции и обычно позволяет достигнуть наибольшей производительности и надёжности in-memory-решения.
В) Service Grid — позволяет развертывать произвольные пользовательские службы в кластере. Вы можете внедрять и развертывать любые службы, такие как пользовательские счетчики, генераторы ID, иерархические карты и т. д. Ignite позволит вам контролировать, сколько экземпляров вашей службы должно быть развернуто на каждом узле кластера, и автоматически обеспечит надлежащее развертывание и отказоустойчивость всех служб.
Г) Apache Ignite native persistence — это распределенное хранилище ACID и SQL-совместимого диска, которое прозрачно интегрируется с оперативной памятью Ignite. При использование уровня дисков Ignite всегда сохраняет надмножество данных на диске и, насколько это возможно, в ОЗУ (зависит от емкости памяти). Например, если есть 100 записей и ОЗУ имеет возможность хранить только 20, то все 100 будут сохранены на диске, и только 20 будут кэшироваться в ОЗУ для улучшения производительности. Кроме того, при использовании только памяти каждый отдельный узел кластера остается только подмножеством данных, включая только разделы, для которых узел является основным, либо резервным. В совокупности весь кластер содержит полный набор данных.
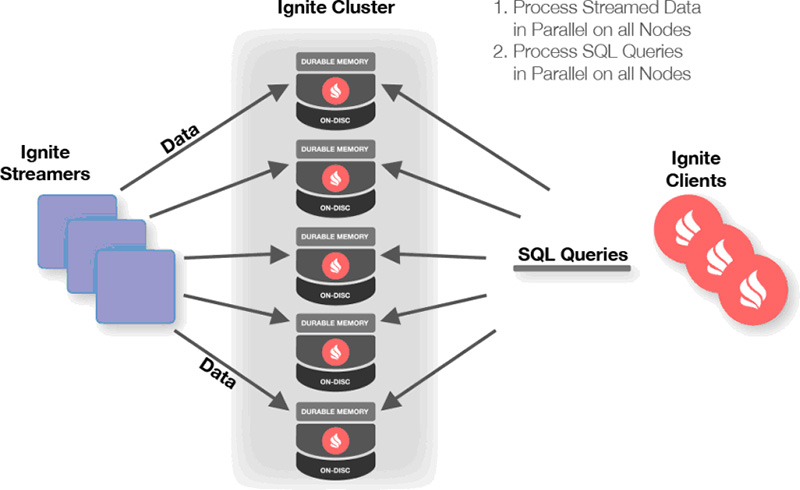
Д) Ignite streaming — позволяет обрабатывать непрерывные бесконечные потоки данных с масштабируемым и отказоустойчивым способом. Скорость потока данных может быть довольно высокой и превышать миллионы событий в секунду на кластере умеренного размера. Как это работает:
- клиентские узлы вводят потоки данных в кеширующие ядра, используя Ignite Data Streamers;
- данные автоматически разделяются между узлами данных Ignite, и каждый узел получает равное количество данных;
- потоковые данные могут одновременно обрабатываться непосредственно на узлах данных Ignite, размещенных в ячейках;
- клиенты также могут выполнять параллельные SQL-запросы для потоковых данных.
Каковы альтернативы на рынке?
Прорыва как такового нет, есть аналогичные продукты, которые давно используют вычисления in-memory. Например: IMDG/IMCG-продукты VMware Gemfire, Oracle Coherence, Alachisoft Ncache, Gigaspaces XAP Elastic Caching Edition, Hazelcast, Scaleout StateServer, IBM WebSphere eXtreme Scale, Terracotta Enterprise Suite, JBoss Infinispan.
В числе наиболее успешных игроков на поле IMDM называют SAP (Hana и Sybase IQ), Oracle, IBM, Altibase, Tableau, Qliktech и Software AG. Решения на базе SAP Hana я встречал у многих заказчиков (в сфере ритейла, у финансовых организаций) — в отличие от GridGain, который популярен всего в одном крупном банке.
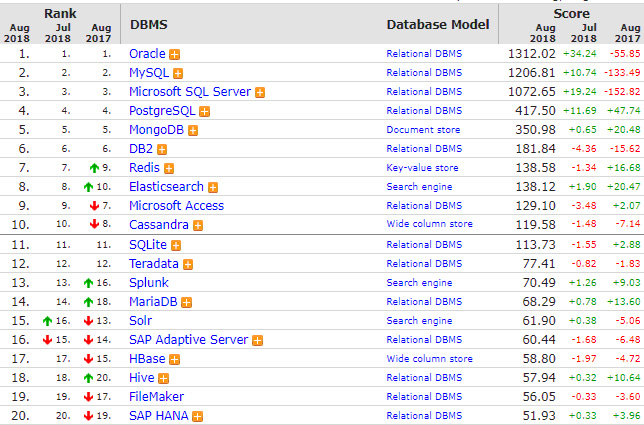
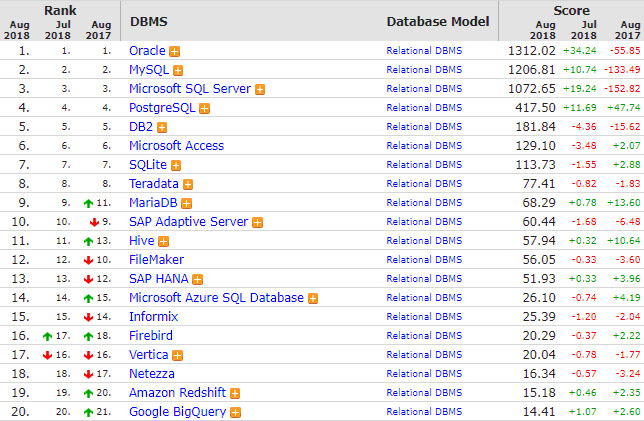
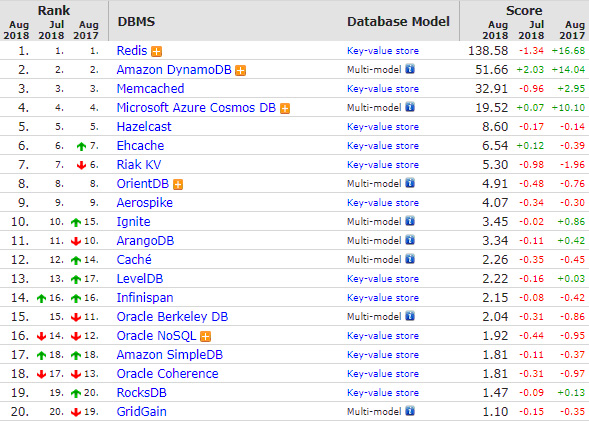
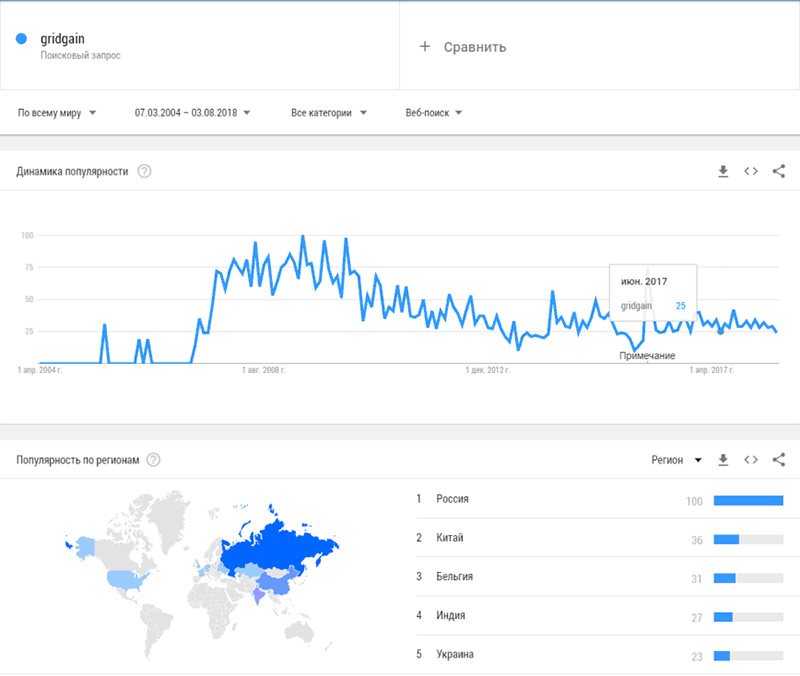
Выводы о популярности той или иной БД и технологии можно сделать на основании рейтингов БД от db-engines по состоянию на август 2018 г.: общего по всем типам БД (рис. 7), для реляционных БД (рис. 8) и для key-value БД (рис. 9). Также довольно интересно взглянуть на историю запросов по GridGain в поисковике — наибольшую популярность тема имеет именно в РФ (рис. 10).
Есть ли безопасность?
Как обстоят дела с безопасностью GridGain? Тут все еще проще: по теме есть одна единственная ссылка на сайте производителя. Оказывается, что версия GridGain Enterprise Edition отличается от Apache Ignite не только наличием технического обслуживания, исправлением ошибок и Enterprise Features, но и механизмами обеспечения ИБ.
Какие механизмы ИБ предлагает GridGain?
- Шифрование. GridGain поддерживает SSL/TLS-шифрование данных между своими узлами, поддерживаются основные алгоритмы шифрования SSL/TLS, которые были описаны для Java JDK 7.
- Разграничение доступа.
- GridGain поддерживает аутентификацию и авторизацию пользователей и узлов GridGain с помощью логина/пароля или сервиса Java Authentication and Authorization (JAAS), совместимого с каталогами JNDI, LDAP, Active Directory. Также доступны другие более защищенные варианты аутентификации путем доработки самого кода, например с использованием сертификатов, одноразовых паролей, токенов, ключей доступа.
- Разрешения — права доступа к системе, задачам и уровню кэша. В GridGain для любых операций — чтение, запись данных, администрирование (put, get, remove, close или task), запросы и просмотр данных — могут быть установлены ограничения вплоть до кэша. Что позволит правильно разграничить доступ в GridGain, например, к разным ИС, данным или компаниям (арендаторам) использующим один GridGain.
- Аудит событий. GridGain обеспечивает запись каждого события, происходящего в системе. Можно выбрать нужный формат событий и формат лог файла.
В итоге, что мы имеем из коробки? Возможность настроить шифрование данных, задать логины/пароли и включить журнал аудита событий. Этого вполне хватит для пилотного запуска или тестовой эксплуатации, но для опытной эксплуатации необходимо будет доработать механизмы аутентификации и разрешения на доступ (к системе, задачам, кэшу). А это уже существенные доработки, требующие человеческих и финансовых затрат, которые необходимо закладывать в проект.
А если учесть, что GridGain будут использовать несколько разных арендаторов, то необходимо будет спроектировать и продумать особенности, архитектуру и потоки информации каждой ИС, чтобы исключить утечку данных, поскольку не все еще научились правильно защищать виртуальные инфраструктуры и классические облачные сервисы IaaS, PaaS.
Основные преимущества и недостатки GridGain
Плюсы:
- возможность осуществлять быстрые вычисления для быстрых данных в памяти;
- возможность работать с любыми типами БД и данными;
- неограниченный функционал, который способен решить любую бизнес-задачу.
Минусы:
- очень высокая стоимость оперативной памяти и малое количество разъёмов под модули, а также ограниченный размер самих модулей —
128-64 Гб не дает собирать большие in-memory-кластеры; - необходимо использовать качественные диски и обеспечивать резервирование;
- низкая скорость обработки при работе с данными на дисках и в хранилищах;
- требуется очень гибкая и правильная настройка всей экосистемы для безотказной работы;
- необходимо тщательно проектировать взаимосвязь всех компонентов, сервисов, потоков информации и настраивать базовые механизмы защиты, а также обязательно внедрять дополнительные.
Сравнение стоимости и скорости носителей информации
|
Тип |
Цена за 1 Тб, тыс. руб. |
Скорость, Мб/с |
|
HDD SATA |
2,5 |
140 |
|
HDD SAS |
6 |
200 |
|
SSD |
16,5 |
540 |
|
DDR4 |
800 |
40 000 |
С какими проблемами сталкиваются заказчики в GridGain?
Из официальных источников удалось найти следующие проблемы, с которыми сталкиваются интеграторы и заказчики:
- много багов;
- не все документировано и детализировано;
- защита всего GridGain зависит от защиты отдельно взятой ноды;
- производительность падает на 50% в период выхода из строя одной ноды и перебалансировки нагрузки;
- возможно появление новых типов вирусов, направленных на GridGain;
- возможно появление новых типов средств защиты данных.
Выводы
Выводы делайте самостоятельно, каждый продукт имеет свое место и найдет своего покупателя. Нужно понимать, что основное отличие GridGain состоит в том, что это:
- прежде всего, своя Java-экосистема. Если у вас софт преимущественно написан на Java, то продукт скорее для вас.
- конструктор, а не готовый продукт, способный решать конкретные задачи. А это дополнительно требует значительных затрат на инфраструктуру и штат проектировщиков, аналитиков, разработчиков, эксплуатантов.
- продукт наибольшую популярность имеет в РФ, что может сказаться на качестве поддержки (при покупке платной версии GridGain).
Автор статьи — эксперт-аналитик по ИБ.