В сфере искусственного интеллекта и связанных с ним методов, в частности машинного и глубокого обучения, львиная доля внимания прикована к совершенствованию алгоритмов и разработке ПО на их основе. Однако скорость дальнейшего развития технологий ИИ напрямую зависит от возможностей оборудования, которое их обслуживает, его производительности, энергопотребления, скорости соединения и прочего.
Конечно, не стоит забывать тот факт, что именно огромная вычислительная мощность, которой удалось достичь современному оборудованию, сама по себе является причиной нынешнего бума разработок, связанных с искусственным интеллектом (напомним, первая волна хайпа вокруг ИИ наблюдалась в
Однако сейчас мы видим другую картину: количество данных продолжает расти экспоненциально, а соответствующие достижения в области вычислительной производительности, которые в течение более 40 лет двигали компьютерную индустрию вперед, постепенно исчерпывают себя. И проблема увеличения производительности современного оборудования теперь актуальна как никогда.
Данных много, а законы не действуют
С момента изобретения интегральных кремниевых микросхем неким ориентиром технического прогресса служили эмпирический закон Мура и масштабирование Деннарда. Первый гласил, что количество транзисторов в интегральной схеме (при одинаковой производственной стоимости) удваивается примерно каждые два года. Но когда компоненты обычных микросхем достигли так называемого монослоя — единого атомного слоя, который уже нельзя делить дальше, — закон перестал действовать.
Согласно масштабированию Деннарда, дальнейшая миниатюризация элементов микросхемы позволяла использовать более низкое напряжение, но при этом обеспечивала более высокую тактовую частоту процессора при сохранении того же уровня энергопотребления. Однако при уменьшении транзисторов возникают токи утечек, которые приводят к нагреванию микросхем, что в итоге выводит их из строя. Без дорогостоящих систем охлаждения эту проблему решить нельзя.
Согласно публикации в журнале Applied Materials, ссылающейся на «отцов» современной компьютерной архитектуры Джона Хеннеси и Дэвида Паттерсона, масштабирование Деннарда не выполняется с 2003 года, а закон Мура перестал действовать в 2015 году. Ко всему прочему добавляется закон Амдала, накладывающий ограничение на наращивание числа процессоров в вычислительной системе, поскольку с определенного момента добавление каждого нового процессора увеличивает время, необходимое для решения задачи (за счет того, что на передачу данных между узлами системы требуется время).
Повысить производительность современных CPU стало практически невозможно, а это означает, что традиционные вычислительные архитектуры, состоящие из CPU, SRAM для кеша, DRAM и хранилища (HDD или SDD) не всегда оказываются эффективными и экономически выгодными для новых решений в области ИИ. По словам Сэма Эльтмана, сопредседателя OpenAI, дальнейшие прорывы в сфере ИИ будут определять именно новые концепции высокопроизводительного оборудования.
Что предлагает рынок?
Тем не менее даже сейчас рынок оборудования для ИИ-систем активно развивается. Согласно IDC, доходы вендоров аппаратного обеспечения, так или иначе задействованного для потребностей ИИ (в частности, глубокого обучения) в период с 2016 по 2020 гг. сохранят среднегодовой темп роста на уровне 60%. По информации Tractica, более 60 компаний разных размеров анонсировали разработку собственных микросхем для ускорения глубокого обучения или занимаются вопросами, связанными с интеллектуальной собственностью (IP), оптимизированной под конкретный набор микросхем. Даже традиционно ассоциируемые с ПО вендоры, такие как Google и Microsoft, стали активно инвестировать в разработку оборудования, предназначенного для ускорения обработки данных в глубоком обучении. В 2016 году Microsoft заявила об использовании микрочипов с поддержкой технологии FPGA (field-programmable gate array; подробнее об этом ниже) для повышения производительности своей облачной платформы Azure. Google успела выпустить несколько моделей тензорных процессоров (TPU), которые демонстрируют хорошие результаты производительности при выполнении определенных задач. Также, как сообщила The New York Times, в настоящее время над разработкой чипов для ускорения ИИ работает не менее 45 стартапов. Cейчас на мировом рынке аппаратного обеспечения для ИИ можно выделить несколько основных категорий игроков (источник: Tractica):
- оригинальные производители оборудования (OEM). Сюда входят компании, занимающиеся непосредственно производством серверов, сетевого оборудования, хранилищ. Примеры: Cisco, EMC и IBM;
- оригинальные производители устройств (ODM). Компании, выполняющие разработку для других компаний на заказ оборудования, которое впоследствии продается под торговым именем заказчика. Пример: тайваньская компания Wistron является ODM для серверов Minsky от IBM;
- производители чипов. Компании, разрабатывающие наборы микросхем (чипсеты) для ИИ, которые используют ODM или OEM. К ним относятся также Intel и NVIDIA. Также сюда можно причислить некоторые стартапы, например Grafcore, Wave Computing и т. д.;
- провайдеры облачных услуг. Компании, которые покупают оборудование у OEM-производителей, создают собственную инфраструктуру и предлагают свои облачные сервисы для клиентов, в которых те могут создавать собственные ИИ-приложения. Примеры: Amazon, Google и Microsoft;
- провайдеры интеллектуальной собственности (IP). Компании, предоставляющие права интеллектуальной собственности для конкретного набора микросхем.
На рынке производителей аппаратного обеспечения для ускорения ИИ безоговорочно доминирует производитель графических процессоров NVIDIA, ранее наиболее известный по выпуску видеокарт для компьютерной игровой индустрии. В частности, специально для задач глубокого обучения вендор разработал новую микроархитектуру Volta, которая обеспечила производительность глубокого обучения на уровне 100 Тфлопс, то есть в пять раз больше по сравнению с предыдущим поколением архитектуры Pascal. Предполагается, что в проект Volta компания NVIDIA инвестировала более 3 млрд. долл. Кроме того, графические процессоры от NVIDIA — Tesla P100, K80, P4 и P100 — также используются в Google Cloud Platform. В сентябре 2018 года NVIDIA представила новую архитектуру графических процессоров Turing, названных в честь великого английского математика. Помимо процессоров, ускоряющих трассировку лучей в режиме реального времени, ее специфическим отличием также являются тензорные ядра, которые обеспечивают до 500 трлн. тензорных операций в секунду. По информации разработчиков, GPU Turing могут поддерживать до 16 трлн. операций с плавающей запятой параллельно с 16 трлн. целочисленных операций в секунду.
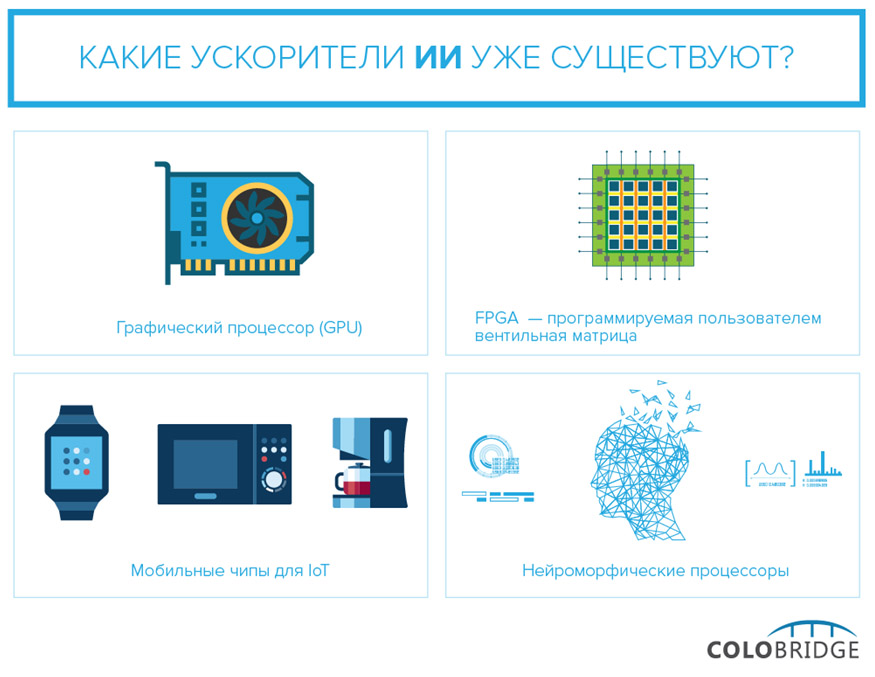
Какие ускорители ИИ уже существуют?
Помимо графических процессоров, для ускорения работы алгоритмов ИИ используются и другие решения. Среди них можно найти как «стандартные», например многоядерные ЦПУ или микропроцессоры, так и совершенно новаторские — такие, как нейроморфные процессоры, имеющие мало общего с принципами архитектуры фон Неймана.
Ниже приведен краткий обзор наиболее распространенных современных решений, с помощью которых производители пытаются решить проблему вычислительной мощности.
Графический процессор (GPU)
С 2009 по 2016 гг. для целей машинного обучения и видеоигр использовались одинаковые GPU. Изначально они были предназначены для того, чтобы графические движки выполняли на них часть вычислений, связанных с геометрией и прорисовкой текстур 3D-картинки, таким образом «разгрузив» CPU. Графические процессоры оснащены многочисленными процессорными ядрами, что позволяет распараллеливать одинаковые задачи, ускоряя их выполнение.
Постепенно производители GPU стали понимать, что рынок нуждается в более специализированных решениях, поддерживающих обучение и вывод (инференс) искусственных нейронных сетей. И если, например, с GPU от NVIDIA могут работать практически все фреймворки для глубокого обучения, то AMD, несмотря на хорошую производительность своих графических процессоров, проигрывает конкуренцию на рынке ускорителей ИИ именно из-за «общей направленности» своих продуктов.
Центральное процессорное устройство (CPU)
Компании также пытаются оптимизировать привычные CPU под потребности машинного обучения (например, процессоры серии Knights Mill от Intel). Широкий спектр приложений ИИ использует вычислительные системы, оснащенные процессорами Intel Xeon. К слову, именно этими CPU оборудована большая часть из ТОП-500 самых мощных компьютеров мира (суперкомпьютеров) на момент публикации статьи (мы даже делали инфографику на эту тему).
Многоядерный микропроцессор и сопроцессор
Многоядерный микропроцессор оптимизирован для параллелизации и векторизации, его цель — максимально увеличить скорость обмена данными между процессором, кешем и памятью. Он имеет больше ядер, чем типичный многоядерный процессор, а также может выполнять функции обычного CPU. Сопроцессор — это дополнительный микропроцессор, поддерживающий работу центрального процессора. Это обычная PCIe-карта, которую используют для ускорения параллельных рабочих нагрузок. К сопроцессорам, например, относятся математические и графические процессоры, I/O-процессор и процессор обработки цифровых сигналов (источник: IDC).
FPGA (field-programmable gate array) — программируемая пользователем вентильная матрица
Это интегральная схема, состоящая из программируемых логических блоков, интерконнекта и блоков ввода-вывода. Главное преимущество FPGA — то, что пользователь может их перепрограммировать (адаптировать) под свои новые задачи. Для задач глубокого обучения по скорости и энергоэффективности вентильная матрица превосходит GPU. Для машинного обучения в своих дата-центрах, FPGA, помимо Microsoft, используют Amazon Web Services (AWS) и Baidu. По данным Deloitte, за продажу этих чипов производители в 2016 году успели выручить больше 4 млрд. долл. В этом же году Intel приобрел Altera (крупнейшего производителя FPGA), что указывает на высокую оценку рыночных перспектив этого продукта. К тому же, по словам д-ра Рэнди Хуанга, архитектора FPGA в Intel Programmable Solutions Group, разработка вентильной матрицы занимает около шести месяцев, тогда как на производство ближайшего «аналога», ASIC (см. следующий пункт списка), уходит до 18 месяцев. Хотя ASIC, как и FPGA, обладает высокой энергоэффективностью по сравнению с GPU, последние могут предложить более высокую производительность в вычислениях с плавающей запятой.
ASIC (application-specific integrated circuit) — интегральная схема специального назначения
Это специализированные интегральные схемы, которые изготавливаются в соответствии с четко определенными требованиями вычислительных задач. Они характеризуются очень низкими удельными затратами (в перерасчете на единицу продукции), но, в отличие от FPGA, не могут быть заново сконфигурированы после изготовления. К тому же организация самого их производства является дорогостоящей. Поэтому ASIC обычно используются только тогда, когда рыночный спрос достигает такой критической отметки, при которой преимущества изготовления ASIC становятся очевидными. По данным Deloitte, доходы от ASIC в 2017 году составили 15 млрд. долл. К ASIC относятся и нашумевшие тензорные процессоры (TPU) от Google, и модуль глубокого обучения (DLU) от Fujitsu.
TPU предназначены для машинного обучения с использование ПО TensorFlow. Первое поколение процессоров датируется 2016 годом, второе —
В свою очередь, DLU от Fujitsu обязана своими впечатляющими свойствами производительности новому типу данных под названием Deep Learning Integer и INT8. Они дают процессору возможность выполнять целочисленные вычисления в 8-, 16- и
Мобильные чипы для IoT
К мобильным чипам прежде всего относят процессоры машинного зрения, используемые в оконечных устройствах. Это стало особенно актуально в связи с развитием Интернета вещей, продолжает возрастать интерес к нейрооптимизированным специализированным ASIC в таких устройствах, как смартфоны, смарт-очки, IP-камеры и т. д. Отличительная черта этих чипов — низкое потребление энергии, так как девайсы IoT попросту не могут позволить себе использовать GPU мощностью 250 Вт, ведь у них нет такого охлаждения, как в ЦОДе. Пока что минимум энергопотребления мобильных чипов достигает 288 мкВт, но это было достигнуто лишь в лабораторных условиях. Примерами мобильных интегральных схем являются нейроморфные чипы Loihi и Movidius VPU (Vision Processing Unit) от Intel для приложений глубокого обучения в автономных оконечных устройствах IoT.
Нейроморфные процессоры
Создатели нейроморфных процессоров явно вдохновлялись достижениями современной нейробиологии. Ядра процессора эмулируют работу клеток нервной системы. Известным примером новой архитектуры является проект нейроморфного процессора TrueNorth от IBM, в котором каждый «нейрон», имея доступ к своей собственной локальной памяти, способен обрабатывать «сигналы» даже во время обращения к ней. Экспериментирует с нейроморфными чипами и компания Intel, работая над проектом с кодовым названием Loihi. Это
Нейроморфные процессоры создавались конкретно под искусственные нейронные сети; они также более энергоэффективны по сравнению с другими ускорителями ИИ. Например, TrueNorth потребляет 70 мВт энергии (напомним, графическому процессору NVIDIA, как мы писали выше, требуется 250 Вт).
Tractica прогнозирует, что рынок чипсетов для глубокого обучения к 2025 году увеличится до 66,3 млрд. долл. по сравнению с 1,6 млрд. долл. в 2017 году.
Будущее архитектуры
Исследователи из Калифорнийского университета в Беркли считают, что разработка аппаратных ускорителей ИИ, оптимизированных под конкретный тип задач, на данном этапе является самым эффективным вариантом. В качестве примера исследователи приводят все тот же тензорный процессор от Google, который выполняет вывод нейронных сетей в
Ученые ожидают, что в будущем серверы будут иметь более гетерогенные процессоры, так как рабочие нагрузки станут более разнородными. Иными словами, под конкретный тип задачи будет создана и оптимизирована своя архитектура.
Помимо прочего, производительность ИИ-систем ограничивается латентностью и пропускной способностью компьютерной памяти. Сегодня ряд компаний работает над созданием новых перспективных моделей памяти (ReRAM, FE-RAM и MRAM, Xpoint), которые призваны решить эту проблему. Например, совместный проект Intel и Micron по разработке энергонезависимой памяти Xpoint собирается обеспечить десятикратную емкость памяти при производительности уровня DRAM. Устройства STT MRAM (Spin-Transfer Torque MRAM) демонстрируют высокую производительность на уровне DRAM и SRAM, используя при этом меньше энергии.
Эксперты из Беркли также отмечают, что скорее всего в будущем память и (облачные) хранилища будут иметь больше уровней иерархии и станут использовать более широкий спектр технологий.
Серверная инфраструктура под ИИ сегодня
Компании, которые сегодня используют или разрабатывают приложения на основе ИИ, непременно сталкиваются с различными ограничениями своей информационной инфраструктуры. Причем эти проблемы на зависят от того, где именно они запускают свои приложения — на серверах on-premise или в облаке.
Ограничения инфраструктуры для ИИ-приложений (в порядке преобладания). Источник: IDC
|
Ограничение инфраструктуры on-premise |
Ограничения облачной инфраструктуры |
|
Сложность управления |
Сложность масштабирования |
|
Сложность масштабирования |
Ограничения производительности |
|
Ограничения производительности |
Недостаточная вместимость хранилища |
|
Выход заданий за рамки SLA |
Сложность управления |
|
Недостаточная вместимость хранилища |
Сложность диагностики проблем |
|
Сложность диагностики проблем |
Сложность балансировки нагрузки |
|
Сложность виртуализации серверов |
Выход заданий за рамки SLA |
|
Недостаток функциональной совместимости |
Высокое потребление энергии |
|
Высокое потребление энергии |
Недостаток функциональной совместимости |
|
Ограничения памяти |
Сложность виртуализации серверов |
С одной стороны, использование различных ускорителей может показаться логичным решением проблем, связанных с производительностью ИТ-систем. С другой стороны, это не всегда самое выгодное решение, так как увеличение производительности всегда влечет за собой повышение расходов.
Многое будет зависеть от типа сервера, на который устанавливаются ускорители, от производительности его ядер, типа самого ускорителя, пропускной способности подсистем ввода-вывода, интерконнекта и других факторов.
Поскольку многие компании еще находятся на стадии экспериментирования с ИИ, оптимизировать серверную инфраструктуру под новые потребности можно тоже лишь путем проб и ошибок. Интересная статистика от IDC показала, что 22,8% компаний за последние несколько лет уже три раза меняли свою инфраструктуру, подстраиваясь под требования своих ИИ-приложений, а 37,6% пользуются инфраструктурой «второго поколения». Кто-то доволен облаком, кому-то хватает локальных серверов, но по сути сейчас экспериментируют все — от пользователей до разработчиков ПО и вендоров оборудования. Какой будет информационная инфраструктура, заточенная под ИИ даже с учетом готовящихся разработок в сфере ускорения вычислительных мощностей, спрогнозировать сложно. Но было бы очень неплохо, если бы в этой области случился какой-нибудь замечательный прорыв:)
Автор статьи — аналитик немецкого хостинг-провайдера Colobridge.