Общих разговоров о полезности, перспективности и победном шествии искусственного интеллекта ведется немало. При этом называются умопомрачительные темпы роста соответствующих рынков. Так например, в декабре 2018 г. сообщалось, что за четыре года российский рынок ИИ и машинного обучения вырастет в 40 раз. Динамика мирового рынка ИИ также выглядит весьма впечатляюще: если в 2018 г. он, по оценкам J.P. Morgan и McKinsey, составил около 90 млрд. долл., то в
С учетом мировых тенденций разрабатывается «Стратегия России в области искусственного интеллекта». В марте стало известно о том, что эксперты Минкомсвязи, «Сбербанка» и некоторых других организаций подготовили проект создания в нашей стране Совета при президенте РФ по развитию искусственного интеллекта. Есть и другие инициативы.
В то же время конкретных примеров успешных ИИ-проектов приводится не так много. Основных причин здесь, видимо, две. Первая: о неуспешных ИИ-проектах (а их не так уж и мало), понятное дело, ни заказчики, ни исполнители, рассказывать не стремятся. Вторая: компании, работающие в рыночных условиях, не стремятся сообщать об успешных ИИ-проектах. В самом деле — зачем раскрывать перед конкурентами особенности эффективных инструментов? Могут ведь и «обойти на повороте».
Отметим, что термин ИИ исключительно широк. И далеко не все (даже весьма продвинутые аналитики) ясно понимают, какие именно технологии за этим термином стоят. Сегодня ИИ — это не только экспертные системы, нейросети и машинное обучение (как глубокое, так и классическое), но и технологии обработки естественного языка (NLP, Natural Language Processing). Роль последних постоянно возрастает. По той простой причине, что в настоящее время темпы роста объемов неструктурированной и полуструктурированной текстовой информации превышают темпы роста хорошо структурированных данных.
У каждой ИИ-технологии есть ряд областей применения, в которых она наиболее эффективны. В то же время, во многих ИИ-проектах эти технологии применяются совместно, дополняя и усиливая друг друга. Таков, в частности, ИИ-проект, о котором рассказывалось на симпозиуме «Технологии анализа естественного языка в медицине», проходившем в апреле в рамках форума MedSoft-2019.
В общих чертах задача ставилась так: на примере Новосибирска оценить степень удовлетворенности клиентов частных медицинских компаний, специализирующихся на выполнении различных видов лабораторных исследований. В этом городе на данном рынке работают четыре конкурирующие друг с другом структуры федерального масштаба: «Гемотест», «Инвитро», KDL, «Ситилаб». Они, в общей сложности, представлены примерно тремя десятками филиалов, расположенных в различных районах города.
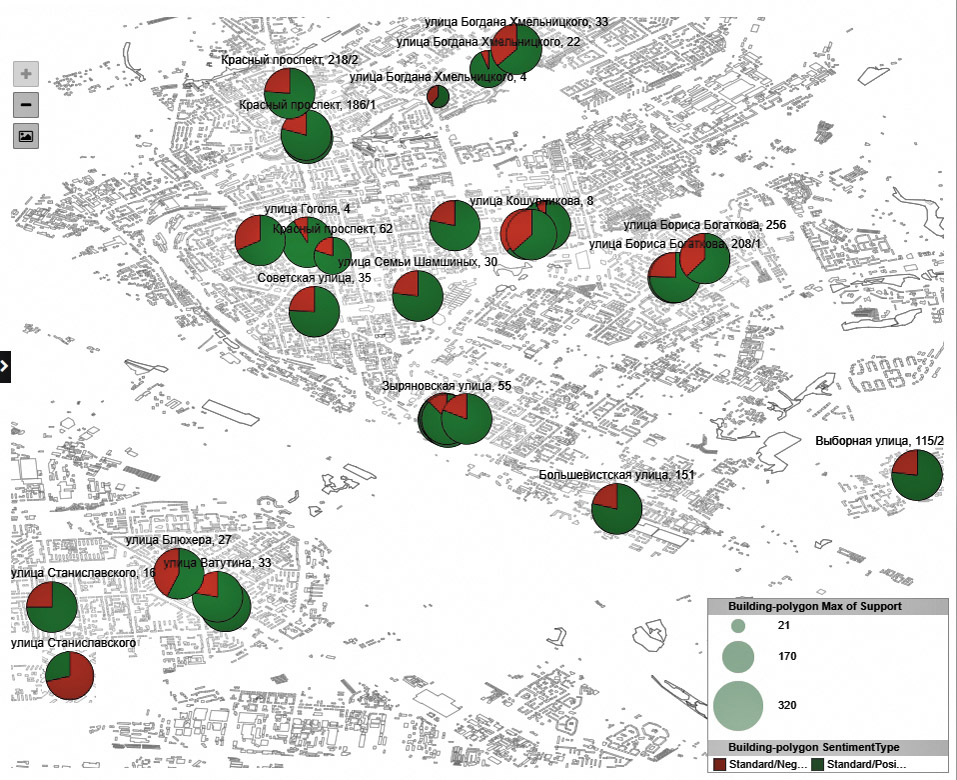
Итоги оценки степени удовлетворенности клиентов работой этих филиалов — они проводились с использованием системы интеллектуального анализа данных PolyAnalyst компании «Мегапьютер Интеллидженс» — изображены на карте города, где положение кружочка отображает местонахождение филиала, а его размер — количество автоматически обработанных отзывов, использованных для оценки степени удовлетворенности посетителей. Зеленая часть кружка отображает долю положительных отзывов, а красная — долю отрицательных. Даже из беглого взгляда на эту карту видно, что есть филиалы, о которых негативных отзывов больше, чем позитивных. Но есть и такие, о которых негативных отзывов очень мало. Вообще говоря, в данном случае в процессе построения соответствующего отчета каждому отзыву присваивался рейтинг от −5 (очень плохой отзыв) до +5 (очень хороший отзыв) и кружочки на карте могли быть раскрашены в большее количество цветов.
«В этом проекте в общей сложности было проанализировано около 4000 отзывов. Выкачивали их автоматически посредством веб-скрапера. Это небольшая программка, которая „бродит“ по заданным веб-страницам и собирает с них данные. В качестве источника данных использовался только 2Gis», — пояснил Давид Сазонов, руководитель направления текстового анализа компании «Мегапьютер Интеллидженс».
Он отметил, что алгоритмы анализа эмоциональной окраски текста не универсальны. Они сильно зависят от того, к какой предметной области данный текст относится. «Этих областей очень много. Нам, например, приходилось анализировать отзывы клиентов на работу различного оборудования, а также на деятельность авиаперевозчиков, банков, гостиниц, страховщиков, ресторанов/кафе, лечебных учреждений и т. д., — рассказал Давид Сазонов. — В системе PolyAnalyst используются алгоритмы, разработанные нашими специалистами с учетом новейших методов анализа текстов. При этом машинное обучение применяется на этапе предварительного анализа текстов. А само извлечение сущностей, фактов и/или тональностей проводится уже на основе правил с использованием информации, полученной на этапах предварительного анализа. Для написания этих правил, их отладки и валидации нами разработаны собственный язык (XPDL — Extensible Pattern Definition Language) и соответствующая среда разработки, позволяющая аналитику самостоятельно формулировать правила извлечения информации из текста. Что позволяет достаточно гибко подстраивать систему под конкретную задачу».
Одним словом, технологии NLP используются для решения очень широкого круга задач: от мониторинга публикаций в СМИ до мониторинга настроений членов конкретного трудового коллектива. В то же время аналитики не выделяют NLP-проекты в отдельную категорию ИИ-проектов. Причина, как уже говорилось, в том, что ИИ-проекты, как правило, носят комплексный характер. И их успех определяется не столько возможностями ИИ-технологий (а они очень велики), сколько правильностью постановки задачи и выбором правильных инструментов для ее решения.