Анант Джингран, основатель и генеральный директор StepZen, и Мэтт Робертс, технический директор IBM Integration, рассказывают на портале The New Stack о том, как интеграционный слой дополняет приложения искусственного интеллекта и как интеграция может быть улучшена с помощью ИИ.
ИИ меняет ландшафт предприятия. Уже сейчас производительность разработчиков, цифровой труд, email-маркетинг, создание веб-сайтов и т. д. кажутся созревшими для серьезной трансформации. Также хорошо понятно, что для решения задач, специфичных для предприятия, базовые модели генеративного ИИ, такие как GPT-4 и Falcon-40B, нуждаются в тонкой настройке или настройке по подсказкам и поэтому им должны подаваться некоторые данные, позволяющие «подстраивать» некоторые подмножества параметров или изменять выходные данные на основе новой информации о задаче, предоставленной в подсказках.
Однако обучение моделей — это одно дело. Сегодня корпоративные приложения живут и умирают благодаря доступу к текущим данным предприятия. Например, сайт электронной коммерции может выдавать статус заказа вошедшего в систему клиента. Или приложение для чата может обрабатывать возврат товара. Ни в одном из этих сценариев нельзя сделать ничего полезного без реального подключения к одному или нескольким корпоративным приложениям (интеграции с ними). Поэтому сначала мы поговорим о том, как интеграционный слой дополняет приложения ИИ.
Надо понимать, что эти интеграции не появляются волшебным образом. Они должны быть закодированы, их необходимо тестировать и поддерживать. Позже мы поговорим о том, как можно улучшить интеграцию с помощью ИИ.
ИИ без интеграции является неполноценным
Каким образом приложение ИИ будет возвращать полезную информацию? ИИ без интеграции — это как рыба без воды.
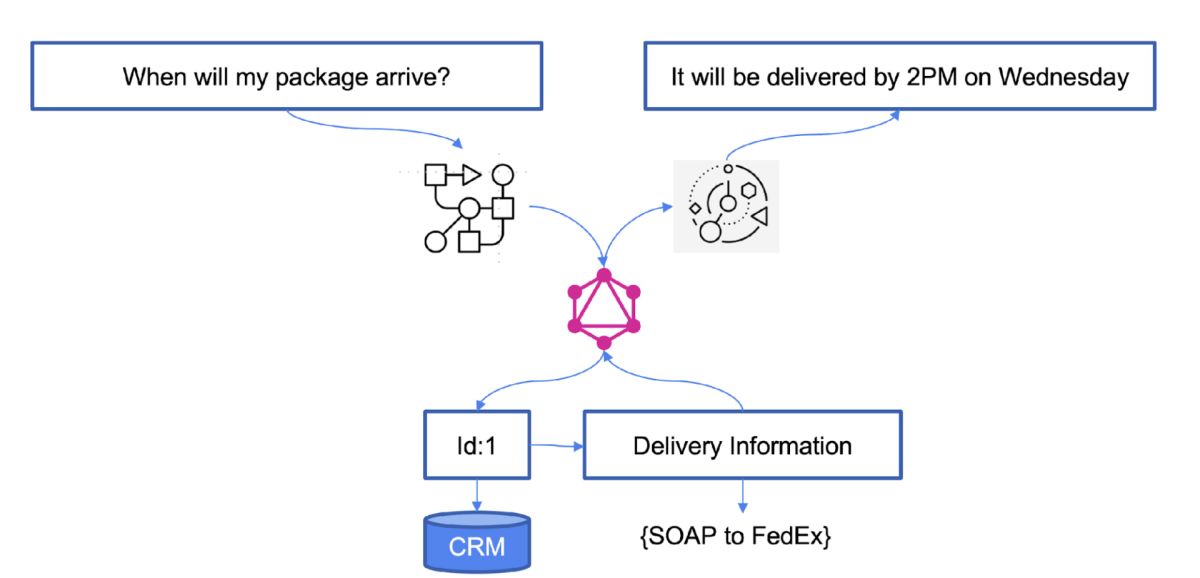
На приведенном выше рисунке вопрос на естественном языке «Когда придет моя посылка?» должен быть разобран базовой моделью и сформирован запрос GraphQL, который затем обращается к корпоративному источнику данных (в данном случае к сторонним системам, таким как FedEx), а затем ответ должен быть использован в качестве входных данных для генерации выходной информации.
Приведенный пример, несмотря на свою простоту, показывает, что модели генеративного ИИ должны быть дополнены технологиями интеграции и API. Авторы данной статьи не скрывают, что питают особое пристрастие к API GraphQL. И в данном случае такой подход особенно полезен, поскольку ИИ-приложение может быть обучено вызову одного универсального API GraphQL, и ему не придется разбираться с тонкостями форматов, авторизаций и побочной передачи информации при взаимодействии с несколькими бэкендами.
Интеграция без ИИ неполноценна
Однако дополнением к вышесказанному является то, что верно и обратное. Применение ИИ дает свои преимущества для каждой из персон и наборов задач в интеграционном пространстве:
- В настоящее время в отрасли основное внимание уделяется разработчикам. До прихода ИИ такие области, как управление API и интеграция приложений, уже эволюционировали в сторону инструментов для создания интеграций low-code/no-code, позволяющих использовать их гражданским разработчикам с меньшими навыками и опытом. ИИ дает возможность расширить возможности этих разработчиков в более продвинутых или исторически специализированных сценариях.
- Администраторы, операторы и инженеры по надежности объектов (SRE) интеграционных развертываний также выиграют от применения ИИ. Обнаружение аномалий в таких операционных показателях, как коды ответов API, скорость транзакций, глубина очереди и системные журналы — все это сценарии, которые способны хорошо поддерживать модели машинного обучения, предоставляющие администраторам шестое чувство для наблюдения и поддержания здоровья системы.
- Менеджеры по продуктам и владельцы бизнеса, часто находящиеся на менее техническом конце спектра, также выигрывают от описанных выше генеративных и low-code возможностей, позволяющих им самостоятельно удовлетворять свои потребности в запросах и анализе данных для выявления бизнес-тенденций и новых потоков доходов.
Во всех сценариях существуют различные аспекты, которые требуют пристального отслеживания по мере развития технологии ИИ.
Во-первых, модели должны быть надежными. Искусство и наука доверия к ИИ развиваются быстро, но, конечно, темпы инноваций в основных алгоритмах ИИ еще выше. В какой-то момент времени исследования доверия должны будут догнать исследования моделей.
С этим связаны детерминизм и повторяемость. В таких сценариях, как генерация сопоставления (мэппинг) между двумя объектами данных, нежелательно, чтобы каждый раз, когда вы задаете один и тот же вопрос, создавалось другое сопоставление, и все же именно так обстоят дела сегодня для многих базовых моделей, поскольку они балансируют вероятность между несколькими конкурирующими вариантами.
Критически важной для эффективности возможностей ИИ является корректность. Существует множество известных примеров, когда контент, созданный ИИ, на первый взгляд правдоподобен, но на практике оказывается ошибочным. Сегодня для анализа, отладки и исправления сгенерированного ИИ артефакта часто требуется квалифицированный специалист, но по мере развития технологии мы ожидаем, что уверенность в достоверности результатов будет расти, что снизит потребность в человеческом контроле.
Далее, стоимость выводов, о которой часто не говорят, станет доминирующей операционной издержкой, и предприятиям придется научиться находить компромисс между размером модели и размером подсказки (линейное и квадратичное влияние соответственно на стоимость выводов) и качеством выходных данных (стоит ли переходить от модели с 8 млрд. параметров к модели с 100 млрд. параметров ради повышения качества выходных данных на 2%?).
Чувствительность владения данными также является ключевым вопросом для многих предприятий. Базовые модели работают наиболее эффективно, когда они могут быть обучены на самом большом корпусе доступных примеров, но если эти примеры содержат конфиденциальную информацию о клиентах или представляют конкурентное преимущество для предприятия, то необходимо позаботиться о том, как эти данные будут в дальнейшем использоваться владельцем модели.
Резюме
Интеграцию на основе ИИ ожидает большое будущее — как в области применения интеграции для обеспечения доступа инструментов ИИ к корпоративным данным, так и в области применения ИИ для реализации сценариев интеграции.