













Несмотря на то, что при внедрении искусственного интеллекта многие обращают основное внимание на технологию, на самом деле наиболее сложными являются аспекты, связанные с людьми и процессами, пишет на портале The New Stack Дормейн Дрюитц, вице-президент по маркетингу продуктов и связям с разработчиками компании PagerDuty.
ИИ сегодня повсюду, во многом благодаря влиянию ChatGPT. Но в среде ИТ-специалистов и технологов в основном обсуждаются преимущества производительности, которые получают от него команды разработчиков. О том, что нужно делать после создания и доставки продукта, говорится существенно меньше. Это оставляет несколько открытых вопросов. Как насчет других технических ролей? Что происходит после того, как код, созданный ИИ, становится функцией в сервисе, на который полагаются клиенты? Что произойдет после запуска функции, основанной на большой языковой модели (LLM), в производство?
Операционализация ИИ означает несколько разных вещей.
Для начала полезно рассмотреть три классические концепции: люди, процессы и технологии. И хотя технологии — это та часть, на которую многие в первую очередь обращают внимание, на самом деле наиболее сложными являются элементы, связанные с людьми и процессами.
Потенциал искусственного интеллекта
ИИ начали внедрять в продукты и бизнес-процессы довольно быстрыми темпами еще до того, как ChatGPT продемонстрировал преобразующий потенциал LLM. По оценкам McKinsey, среднее количество используемых возможностей ИИ в каждой организации удвоилось за три года и в конце
Невозможно переоценить влияние генеративного ИИ на рынок в целом. По прогнозам, эта технология может приносить от 2,6 до 4,4 трлн. долл. в год, увеличивая экономический эффект от всего ИИ на
Выравнивание игрового поля для ИИ-бенефициаров
При всех рассуждениях о том, что ИИ отнимет рабочие места, экономический анализ и история говорят о том, что повышение производительности труда гораздо более вероятно, чем уничтожение профессий. Но каких именно?
Начнем с разработчиков. Некоторые тематические исследования показали повышение производительности труда разработчиков на
Главное — учитывать влияние повышения производительности на другие команды. Что произойдет с операционными и инфраструктурными командами? Что произойдет с командами платформенных разработчиков, инженерами по надежности систем (SRE) и сотрудниками центров сетевых операций (NOC)? Если разработчики будут доставлять в производство больше кода и быстрее накапливать технический долг, это может привести к перегрузке команд, поддерживающих этот код в производстве.
Частично решение заключается в процессах (о которых мы поговорим далее), а частично — в устранении неравенства в получении выгоды от генеративного ИИ. Таким образом, возникает вопрос, как сделать так, чтобы команды, не являющиеся разработчиками, получили возможность участвовать в повышении производительности на эти
DataOps: поддержка современных архитектур данных
Далее следует процесс. Команды инженеров легко могут увлечься собственными функциями и не обратить внимания на более широкий опыт. Чтобы запустить LLM в производство, необходимо учесть очень многое — от инженерии подсказок до ценообразования. Но для эффективного выпуска высококачественной продукции организации должны видеть общую картину: весь продукт от начала до конца. Это означает, что при внедрении генеративного ИИ или любой другой ИИ-возможности
В июне компания Andreessen Horowitz опубликовала полезную схему зарождающейся архитектуры LLM.
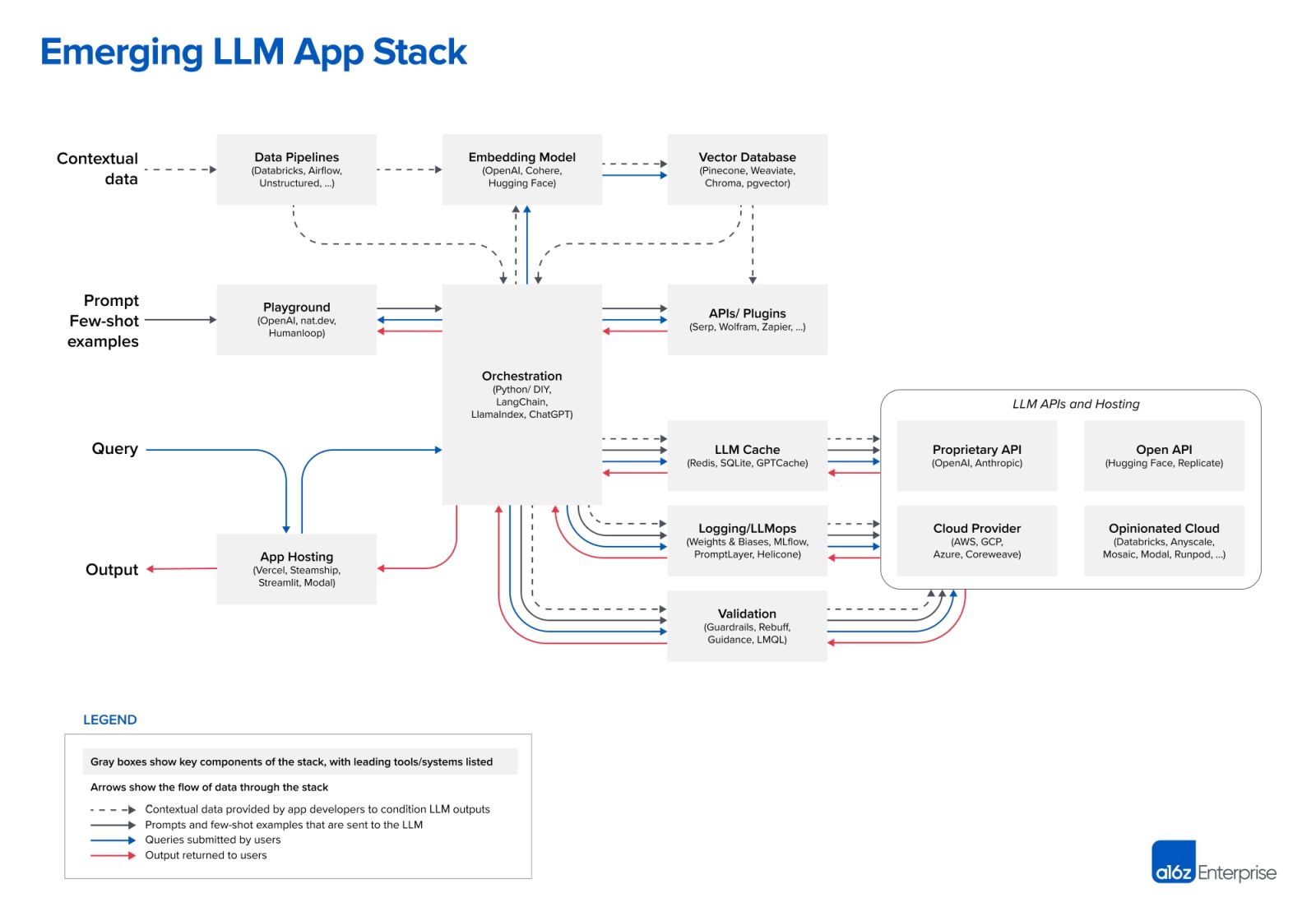
Она сложна. Конвейеры обработки данных уже стали более сложными еще до добавления сложности стека LLM. Команды, занимающиеся инженерией данных, имеют дело с различными облачными сервисами, а зачастую и с локальными системами. Так, поставщики платформ ServiceOps получают данные из
В современной архитектуре данных многое может сломаться. Большая сложность означает большую взаимозависимость между различными компонентами. В то же время сегодня ставки выше, чем в те времена, когда конвейеры данных питали относительно статичные отчеты, к которым терпеливо обращались несколько внутренних сотрудников. Сегодня приложения для работы с данными питаются потоковыми данными и вплетены в экосистему взаимодействия с клиентами.
Однако командам, работающим с LLM, не придется изобретать велосипед для поддержки этих новых архитектур в производстве. Некоторые из проблем, с которыми они столкнутся, будут старыми и довольно знакомыми, а некоторые могут быть новыми вариациями на хорошо известные темы, характерные для вселенной LLM.
Например, команды должны убедиться в том, что данные подготовлены должным образом, прежде чем они попадут в модель, и что обеспечены управление, безопасность и наблюдаемость. Доступность баз данных — привычная практика, даже если векторные базы данных для многих команд могут оказаться новыми. Задержка всегда была проблемой в приложениях, интенсивно использующих данные, но теперь командам необходимо также учитывать влияние свежести данных на результаты работы LLM. С точки зрения безопасности мы уже давно имеем дело с такими векторами атак, как SQL-инъекции, а теперь нам необходимо защититься от инъекций через подсказки.
Одним словом, для нефункциональных аспектов внедрения LLM можно и нужно использовать множество ценных знаний и практик из областей DevOps, инженерии надежности баз данных и систем, а также безопасности. Следуйте лучшим практикам тестирования, мониторинга, управления уязвимостями, установления целей уровня обслуживания (SLO) и управления бюджетами на устранение ошибок, чтобы обеспечить изменения в режиме реального времени. Выполняйте все эти действия, ориентируясь на общую картину, и тогда вероятность того, что ваши функции на базе LLM обеспечат обещанный эффект для бизнеса благодаря высокой производительности и доступности, будет гораздо выше.
Использование ИИ для операционализации ИИ
Наконец, настал черед технологической части. Хорошая новость заключается в том, что мы действительно можем использовать ИИ для операционализации ИИ. Более того, это просто необходимо, учитывая сложность стека приложений LLM. Есть вещи, в которых компьютеры разбираются лучше, чем люди, и нам необходимо признать это и использовать возможности машин для повышения эффективности.
Где машинное обучение может помочь больше всего? Подумайте об объеме данных о событиях, генерируемых этими сложными, оснащенными измерительными приборами системами. Если где-то произошел сбой, это может отразиться на множестве систем, что вызовет потенциальный поток предупреждений. Но МО может помочь нам в сжатии и корреляции данных, чтобы уменьшить шум от оповещений и определить источник проблемы. Кроме того, оно обогащает данные о событиях, что позволяет специалистам быстрее и эффективнее выявлять первопричину и решать проблемы.
МО не только способно помочь в решении трех задач — контекстуализации, корреляции и компрессии, но и делает это лучше человека. Но зачем на этом останавливаться? Мы можем взять результаты работы по идентификации и автоматизировать следующие шаги. Такие шаги, как захват состояния, перезапуск, сброс и множество оперативных задач, которые выполняются специалистами для сбора дополнительных данных и восстановления работоспособности. Подключив обработку событий к условной логике для предопределенных задач, мы можем ускорить разрешение инцидента в сложных системах. Даже если сервис не может быть полностью восстановлен самовосстанавливающимся способом, команды, которым придется вмешаться в ситуацию, смогут получить более точный контекст и отправные точки для устранения неполадок.
Будущее широко открыто
Когда речь идет о генеративном ИИ, мы еще только прощупываем рамки возможного. Но по мере того, как занимательные проекты превращаются в важные сервисы для клиентов, начинается тяжелая работа. Чтобы все могли пользоваться преимуществами ИИ, нам необходимо эффективно его рационализировать. Мы не начинаем с нуля. В этом нам может помочь ускоренное использование автоматизации, DataOps и AIOps.













