













ОБЗОРЫ
Принципы создания системы обработки информации в масштабе предприятия
История развития компьютерной техники (и соответственно программного обеспечения) началась с обособленных, автономных систем. Ученые и инженеры были озабочены созданием первых ЭВМ и в основном ломали головы над тем, как заставить работать эти скопища электронных ламп. Однако такое положение вещей сохранялось недолго - идея объединения вычислительных мощностей была вполне очевидной и витала в воздухе, насыщенном гулом металлических шкафов первых ENIAK’ов и Mark’ов. Ведь мысль объединить усилия двух и более компьютеров для решения сложных, непосильных для каждого из них по отдельности задач лежит на поверхности.
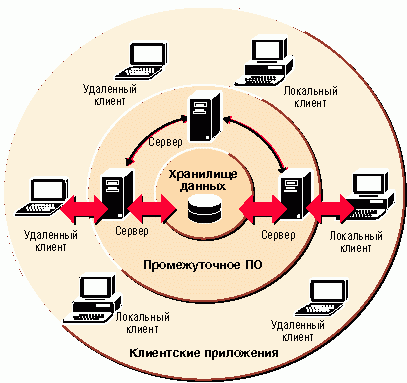
Рис. 1. Схема распределенных вычислений
Однако практическая реализация идеи соединения компьютеров в кластеры и сети тормозилась отсутствием технических решений и в первую очередь необходимостью создания стандартов и протоколов взаимодействия. Как известно, первые ЭВМ появились в конце сороковых годов двадцатого века, а первая компьютерная сеть ARPANet, связавшая несколько компьютеров на территории США, - только в 1966 г., почти через двадцать лет. Конечно, такое объединение вычислительных возможностей современную распределенную архитектуру напоминало весьма отдаленно, но тем не менее это был первый шажок в верном направлении.
Появление локальных сетей со временем привело к развитию новой области разработки программного обеспечения - созданию распределенных приложений. Заниматься этим пришлось, что называется, с нуля, но, к счастью, заинтересованность в таких приложениях сразу же выказали крупные компании, структура бизнеса которых требовала подобных решений. Именно на этапе создания корпоративных распределенных приложений были сформированы основные требования и разработаны основные архитектуры подобных систем, используемые и в настоящее время.
Постепенно мэйнфреймы и терминалы эволюционировали в направлении архитектуры клиент - сервер, которая по существу была первым вариантом распределенной архитектуры, т. е. двухуровневой распределенной системой. Ведь именно в приложениях клиент - сервер часть вычислительных операций и бизнес-логики была перенесена на сторону клиента, что, собственно, и стало изюминкой, визитной карточкой этого подхода.
Именно в этот период стало очевидно, что основными преимуществами распределенных приложений являются:
· хорошая масштабируемость - при необходимости вычислительная мощность распределенного приложения может быть легко увеличена без изменения его структуры;
· возможность управления нагрузкой - промежуточные уровни распределенного приложения дают возможность управлять потоками запросов пользователей и перенаправлять их менее загруженным серверам для обработки;
· глобальность - распределенная структура позволяет следовать пространственному распределению бизнес-процессов и создавать клиентские рабочие места в наиболее удобных точках.
Шло время, и небольшие островки университетских, правительственных и корпоративных сетей расширялись, объединялись в региональные и национальные системы. И вот на сцене появился главный игрок - Internet.
Хвалебные панегирики в адрес Всемирной сети давно стали общим местом публикаций по компьютерной тематике. Действительно, Internet сыграл решающую роль в развитии распределенных вычислений и сделал эту довольно специфическую область разработки программного обеспечения предметом приложения усилий армии профессиональных программистов. Сегодня он существенно расширяет возможности применения распределенных приложений, позволяя подключать удаленных пользователей и делая функции приложения доступными повсеместно.
Такова история вопроса. А теперь давайте посмотрим, что представляют собой распределенные приложения.
Парадигма распределенных вычислений
Представьте себе довольно крупное производственное предприятие, торговую компанию или фирму, предоставляющую услуги. Все их подразделения уже имеют собственные базы данных и специфическое программное обеспечение. Центральный офис каким-то образом собирает сведения о текущей деятельности этих подразделений и обеспечивает руководителей информацией, на основе которой они принимают управляющие решения.
Пойдем дальше и предположим, что рассматриваемая нами организация успешно развивается, открывает филиалы, разрабатывает новые виды продукции или услуг. Более того, прогрессивно настроенные руководители на последнем совещании решили организовать сеть удаленных рабочих мест, с которых клиенты могли бы получать некоторые сведения о выполнении их заказов.
В описываемой ситуации остается только пожалеть руководителя ИТ-подразделения, если он заранее не позаботился о построении общей системы управления бизнес-потоками, ведь без нее обеспечить эффективное развитие организации будет весьма затруднительно. Более того, здесь не обойтись без системы обработки информации в масштабе предприятия, спроектированной с учетом возрастающей нагрузки и к тому же соответствующей основным бизнес-потокам, поскольку все подразделения должны выполнять не только свои задачи, но и при необходимости обрабатывать запросы других подразделений и даже (ночной кошмар для менеджера проекта!) заказчиков.
Итак, мы готовы сформулировать основные требования к современным приложениям масштаба предприятия, диктуемые самой организацией производственного процесса.
Пространственное разделение. Подразделения организации разнесены в пространстве и зачастую имеют слабо унифицированное программное обеспечение.
Структурное соответствие. Программное обеспечение должно адекватно отражать информационную структуру предприятия - соответствовать основным потокам данных.
Ориентация на внешнюю информацию. Современные предприятия вынуждены уделять повышенное внимание работе с заказчиками. Следовательно, ПО предприятия должно уметь работать с новым типом пользователей и их запросами. Такие пользователи заведомо обладают ограниченными правами и имеют доступ к строго определенному виду данных.
Всем перечисленным требованиям к программному обеспечению масштаба предприятия отвечают распределенные системы - схема распределения вычислений приведена на рис. 1.
Безусловно, распределенные приложения не свободны от недостатков. Во-первых, они дороги в эксплуатации, а во-вторых, создание таких приложений - процесс трудоемкий и сложный, а цена ошибки на этапе проектирования очень велика. Тем не менее разработка распределенных приложений успешно развивается - ведь игра стоит свеч, поскольку такое ПО способствует повышению эффективности работы организации.
Итак, парадигма распределенных вычислений подразумевает наличие нескольких центров (серверов) хранения и обработки информации, реализующих различные функции и разнесенных в пространстве. Эти центры помимо запросов клиентов системы должны выполнять и запросы друг друга, так как в ряде случаев для решения первой задачи могут понадобиться совместные усилия нескольких серверов. Для управления сложными запросами и функционированием системы в целом необходимо специализированное управляющее ПО. И наконец, вся система должна быть "погружена" в некую транспортную среду, обеспечивающую взаимодействие ее частей.
Распределенные вычислительные системы обладают такими общими свойствами, как:
· управляемость - подразумевает способность системы эффективно контролировать свои составные части. Это достигается благодаря использованию управляющего ПО;
· производительность - обеспечивается за счет возможности перераспределения нагрузки на серверы системы с помощью управляющего ПО;
· масштабируемость - при необходимости физического повышения производительности распределенная система может легко интегрировать в своей транспортной среде новые вычислительные ресурсы;
· расширяемость - к распределенным приложениям можно добавлять новые составные части (серверное ПО) с новыми функциями.
Доступ к данным в распределенных приложениях возможен из клиентского ПО и других испределенных системах может быть организована на различных уровнях - от клиентского ПО и транспортных протоколов до защиты серверов БД.
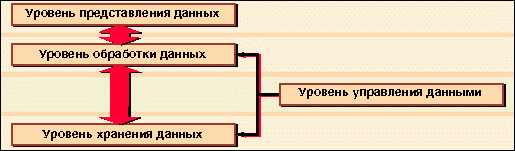
Рис. 2. Основные уровни архитектуры распределенного приложения
Перечисленные свойства распределенных систем являются достаточным основанием, чтобы мириться со сложностью их разработки и дороговизной обслуживания.
Архитектура распределенных приложений
Рассмотрим архитектуру распределенного приложения, позволяющую ему выполнять сложные и разнообразные функции. В разных источниках приводятся различные варианты построения распределенных приложений. И все они имеют право на существование, ведь такие приложения решают самый широкий круг задач во многих предметных областях, а неудержимое развитие средств разработки и технологий подталкивает к непрерывному совершенствованию.
Тем не менее существует наиболее общая архитектура распределенного приложения, согласно которой оно разбивается на несколько логических слоев, уровней обработки данных. Приложения, как известно, предназначены для обработки информации, и здесь мы можем выделить три главнейшие их функции:
· представление данных (пользовательский уровень). Здесь пользователи приложения могут просмотреть необходимые данные, отправить на выполнение запрос, ввести в систему новые данные или отредактировать их;
· обработка данных (промежуточный уровень, middleware). На этом уровне сконцентрирована бизнес-логика приложения, осуществляется управление потоками данных и организуется взаимодействие частей приложения. Именно концентрация всех функций обработки данных и управления на одном уровне считается основным преимуществом распределенных приложений;
· хранение данных (уровень данных). Это уровень серверов баз данных. Здесь расположены сами серверы, базы данных, средства доступа к данным, различные вспомогательные инструменты.
Нередко такую архитектуру называют трехуровневой или трехзвенной. И очень часто на основе этих "трех китов" создается структура разрабатываемого приложения. При этом всегда отмечается, что каждый уровень может быть дополнительно разбит на несколько подуровней. Например, пользовательский уровень может быть разбит на собственно пользовательский интерфейс и правила проверки и обработки вводимых данных.
Безусловно, если принять во внимание возможность разбиения на подуровни, то в трехуровневую архитектуру можно вписать любое распределенное приложение. Но здесь нельзя не учитывать еще одну характерную особенность, присущую именно распределенным приложениям, - это управление данными. Важность этой функции очевидна, поскольку очень трудно создать реально работающее распределенное приложение (со всеми клиентскими станциями, промежуточным ПО, серверами БД и т. д.), которое бы не управляло своими запросами и ответами. Поэтому распределенное приложение должно обладать еще одним логическим уровнем - уровнем управления данными.
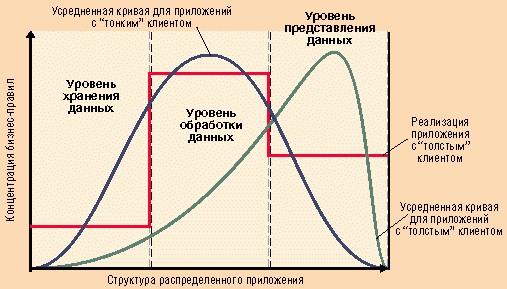
Рис. 3. Распределение бизнес-логики по уровням распределенного приложения
Следовательно, целесообразно разделять промежуточный уровень на два самостоятельных: уровень обработки данных (так как необходимо учитывать важное преимущество, которое он дает, - концентрацию бизнес-правил обработки данных) и уровень управления данными. Последний обеспечивает контроль выполнения запросов, обслуживает работу с потоками данных и организует взаимодействие частей системы.
Таким образом, можно выделить четыре основных уровня распределенной архитектуры (см. рис. 2):
· представление данных (пользовательский уровень);
· правила бизнес-логики (уровень обработки данных);
· управление данными (уровень управления данными);
· хранение данных (уровень хранения данных).
Три уровня из четырех, исключая первый, занимаются непосредственно обработкой данных, а уровень представления данных позволяет визуализировать и редактировать их. При помощи этого уровня пользователи получают данные от уровня обработки данных, который, в свою очередь, извлекает информацию из хранилищ и осуществляет все необходимые преобразования данных. После ввода новой информации или редактирования существующей потоки данных направляются в обратный путь: от пользовательского интерфейса через уровень бизнес-правил в хранилище.
Еще один уровень - управления данными - стоит в стороне от магистрального потока данных, но он обеспечивает бесперебойное функционирование всей системы, управляя запросами и ответами и взаимодействием частей приложения.
Отдельно необходимо рассмотреть вариант просмотра данных в режиме "только для чтения". В этом случае уровень обработки данных не используется в общей схеме передачи данных, так как необходимость вносить какие-либо изменения отпадает. А сам поток информации является однонаправленным - из хранилища на уровень представления данных.
Физическая структура распределенных приложений
А сейчас обратимся к физическим уровням распределенных приложений. Топология распределенной системы подразумевает разделение на несколько серверов баз данных, серверов обработки данных и совокупность локальных и удаленных клиентов. Все они могут располагаться где угодно: в одном здании или на другом континенте. В любом случае части распределенной системы должны быть соединены надежными и защищенными линиями связи. Что касается скорости передачи данных, то она в значительной степени зависит от важности соединения между двумя частями системы с точки зрения обработки и передачи данных и в меньшей степени от их удаленности.
Распределение бизнес-логики по уровням распределенного приложения
Настало время перейти к подробному описанию уровней распределенной системы, но предварительно скажем несколько слов о распределении функциональности приложения по уровням. Бизнес-логика может быть реализована на любом из уровней трехуровневой архитектуры.
Серверы БД могут не только сохранять данные в базах данных, но и содержать часть бизнес-логики приложения в хранимых процедурах, триггерах и т. д.
Клиентские приложения также могут реализовывать правила обработки данных. Если набор правил минимален и сводится в основном к процедурам проверки корректности ввода данных, мы имеем дело с "тонким" клиентом. "Толстый" клиент, наоборот, содержит большую долю функциональности приложения.
Уровень же обработки данных собственно и предназначен для реализации бизнес-логики приложения, и здесь сконцентрированы все основные правила обработки данных.
Таким образом, в общем случае функциональность приложения оказывается "размазанной" по всему приложению. Все разнообразие распределения бизнес-логики по уровням приложений можно представить в виде плавной кривой, показывающей долю правил обработки данных, сконцентрированной в конкретном месте. Кривые на рис. 3 носят качественный характер, но тем не менее позволяют увидеть, как изменения в структуре приложения могут повлиять на распределение правил.
И практика подтверждает это заключение. Ведь всегда найдется парочка правил, которые нужно реализовать именно в хранимых процедурах сервера БД, и очень часто бывает удобно перенести некоторые первоначальные операции с данными на сторону клиента - хотя бы для того, чтобы предотвратить обработку некорректных запросов.
Уровень представления данных
Уровень представления данных - единственный доступный конечному пользователю. Этот уровень моделирует клиентские рабочие места распределенного приложения и соответствующее ПО. Возможности клиентского рабочего места в первую очередь определяются возможностями операционной системы. В зависимости от типа пользовательского интерфейса клиентское ПО делится на две группы: клиенты, использующие возможности ГИП (например, Windows), и Web-клиенты. Но в любом случае клиентское приложение должно обеспечивать выполнение следующих функций:
· получение данных;
· представление данных для просмотра пользователем;
· редактирование данных;
· проверка корректности введенных данных;
· сохранение сделанных изменений;
· обработка исключительных ситуаций и отображение информации об ошибках для пользователя.
Все бизнес-правила желательно сконцентрировать на уровне обработки данных, но на практике это не всегда удается. Тогда говорят о двух типах клиентского ПО. "Тонкий" клиент содержит минимальный набор бизнес-правил, А "толстый" реализует значительную долю логики приложения. В первом случае распределенное приложение существенно легче отлаживать, модернизировать и расширять, во втором - можно минимизировать расходы на создание и поддержание уровня управления данными, так как часть операций может выполняться на стороне клиента, а на долю промежуточного ПО ложится только передача данных.
Уровень обработки данных
Уровень обработки данных объединяет части, реализующие бизнес-логику приложения, и является посредником между уровнем представления данных и уровнем их хранения. Через него проходят все данные и претерпевают в нем изменения, обусловленные решаемой задачей (см. рис. 2). К функциям этого уровня относятся следующие:
· обработка потоков данных в соответствии с бизнес-правилами;
· взаимодействие с уровнем представления данных для получения запросов и возвращения ответов;
· взаимодействие с уровнем хранения данных для передачи запросов и получения ответов.
Чаще всего уровень обработки данных отождествляют с промежуточным ПО распределенного приложения. Такая ситуация в полной мере верна для "идеальной" системы и лишь отчасти - для реальных приложений (см. рис. 3). Что касается последних, то промежуточное ПО для них содержит большую долю правил обработки данных, но часть из них реализована в серверах SQL в виде хранимых процедур или триггеров, а часть включена в состав клиентского ПО.
Такое "размывание" бизнес-логики оправданно, так как позволяет упростить часть процедур обработки данных. Возьмем классический пример выписки заказа. В него могут быть включены наименования только тех продуктов, которые имеются на складе. Следовательно, при добавлении в заказ некоторого наименования и определения его количества соответствующее число должно быть вычтено из остатка этого наименования на складе. Очевидно, что лучше всего реализовать эту логику средствами сервера БД - хранимой процедурой или триггером.
Уровень управления данными
Уровень управления данными нужен для того, чтобы приложение оставалось единым целым, было устойчивым и надежным, имело возможности модернизации и масштабирования. Он обеспечивает выполнение системных задач, без него части приложения (серверы БД, серверы приложения, промежуточное ПО, клиенты) не смогут взаимодействовать друг с другом, а связи, нарушенные при повышении нагрузки, нельзя будет восстановить.
Кроме того, на уровне управления данными могут быть реализованы различные системные службы приложения. Ведь всегда существуют общие для всего приложения функции, которые необходимы для работы всех уровней приложения, следовательно, их невозможно расположить ни на одном из других уровней.
Например, служба единого времени обеспечивает все части приложения системными метками времени, синхронизирующими их работу. Представьте, что распределенное приложение имеет некий сервер, рассылающий клиентам задания с указанием конкретного срока их выполнения. При срыве установленного срока задание должно регистрироваться с вычислением времени задержки. Если клиентские рабочие станции расположены в том же здании, что и сервер, или на соседней улице, - нет проблем, алгоритм учета прост. Но что делать, если клиенты расположены в других часовых поясах - в других странах или вообще за океаном? В этом случае сервер должен уметь вычислять разницу с учетом часовых поясов при отправке заданий и получении ответов, а клиенты будут обязаны добавлять к отчетам служебную информацию о местном времени и часовом поясе. Если же в состав распределенного приложения входит служба единого времени, то такой проблемы просто не существует.
Кроме службы единого времени уровень управления данными может содержать службы хранения общей информации (сведения о приложении в целом), формирования общих отчетов и т. д.
Итак, к функциям уровня управления данными относятся:
· управление частями распределенного приложения;
· управление соединениями и каналами связи между частями приложения;
· управление потоками данных между клиентами и серверами и между серверами;
· управление нагрузкой;
· реализация системных служб приложения.
Необходимо отметить, что часто уровень управления данными создается на основе готовых решений, поставляемых на рынок программного обеспечения различными производителями. Если разработчики выбрали для своего приложения архитектуру CORBA, то в ее составе имеется брокер объектных запросов (Object Request Broker, ORB), если платформу Windows, - к их услугам разнообразные инструменты: технология COM+ (развитие технологии Microsoft Transaction Server, MTS), технология обработки очередей сообщений MSMQ, технология Microsoft BizTalk и др.
Уровень хранения данных
Уровень хранения данных объединяет серверы SQL и базы данных, используемые приложением. Он обеспечивает решение следующих задач:
· хранение данных в БД и поддержание их в работоспособном состоянии;
· обработка запросов уровня обработки данных и возврат результатов;
· реализация части бизнес-логики распределенного приложения;
· управление распределенными базами данных при помощи административного инструментария серверов БД.
Помимо очевидных функций - хранения данных и обработки запросов, уровень может содержать часть бизнес-логики приложения в хранимых процедурах, триггерах, ограничениях и т. д. Да и сама структура базы данных приложения (таблицы и их поля, индексы, внешние ключи и пр.) есть реализация структуры данных, с которыми работает распределенное приложение, и реализация некоторых правил бизнес-логики. Например, использование в таблице БД внешнего ключа требует создания соответствующего ограничения на манипуляции с данными, так как записи главной таблицы не могут быть удалены при наличии соответствующих записей, связанных по внешнему ключу таблицы.
Большинство серверов БД поддерживают разнообразные процедуры администрирования, в том числе и управление распределенными базами данных. К ним можно отнести репликацию данных, их удаленное архивирование, средства доступа к удаленным базам данных и др. Возможность использования этих инструментов следует учитывать при разработке структуры собственного распределенного приложения.
Подключение к базам данных серверов SQL осуществляется в основном при помощи клиентского ПО серверов. Помимо этого дополнительно могут использоваться различные технологии доступа к данным, например ADO (ActiveX Data Objects) или ADO.NET. Но при проектировании системы необходимо учитывать, что функционально промежуточные технологии доступа к данным не относятся к уровню хранения данных.
Расширения базовых уровней
Рассмотренные выше уровни архитектуры распределенного приложения являются базовыми. Они формируют структуру создаваемого приложения в целом, но при этом, естественно, не могут обеспечить реализацию любого приложения - предметные области и задачи слишком обширны и многообразны. Для таких случаев архитектура распределенного приложения может быть расширена за счет дополнительных уровней, которые призваны отобразить особенности создаваемого приложения.
Среди прочих можно выделить два наиболее часто применяемых расширения базовых уровней.
Уровень бизнес-интерфейса располагается между уровнем пользовательского интерфейса и уровнем обработки данных. Он скрывает от клиентских приложений детали структуры и реализации бизнес-правил уровня обработки данных, обеспечивая абстрагирование программного кода клиентских приложений от особенностей реализации логики приложения.
В результате разработчики клиентских приложений используют некий набор необходимых функций - аналог интерфейса прикладного программирования (API). Это позволяет сделать клиентское ПО независимым от реализации уровня обработки данных.
Безусловно, при внесении серьезных изменений в систему без глобальных переделок не обойтись, но уровень бизнес-интерфейса позволяет не делать этого без крайней необходимости.
Уровень доступа к данным располагается между уровнем хранения данных и уровнем обработки данных. Он позволяет сделать структуру приложения не зависящей от конкретной технологии хранения данных. В таких случаях программные объекты уровня обработки данных передают запросы и получают ответы при помощи средств выбранной технологии доступа к данным.
При реализации приложений на платформе Windows чаще всего используется технология доступа к данным ADO, так как она обеспечивает универсальный способ доступа к самым разнообразным источникам данных - от серверов SQL до электронных таблиц. Для приложений на платформе .NET служит технология ADO.NET.
С автором, руководителем информационного отдела Генеральной сервисной компании, можно связаться по адресу: eugenem@cs.spb.su.













