













СЕМИНАРЫ
В последнее время много говорится о том, что нужно улучшать защиту корпоративных ИТ-систем от сбоев оборудования, аварий и природных катастроф. Еще в 2001 г. консультанты из Gartner заявляли, что из каждых пяти предприятий, сталкивающихся с аварийной ситуацией, в течение ближайшего пятилетия три потерпят крах. Помимо потери дохода из-за неработоспособности ИТ-системы существует и целый ряд косвенных издержек из-за аварий - уменьшение доли рынка, стоимости торговых марок и акций компании, снижение продуктивности сотрудников, недовольство клиентов и ущерб репутации. По данным проводившегося три года назад исследования Meta Group, только прямой ущерб из-за простоя в течение 3,5 ч для торговой компании составит 195 тыс. долл., а для финансовой организации - 58 млн. долл.
Однако, как свидетельствуют последние исследования, далеко не все руководители бизнеса сознают необходимость защиты от аварий.
На семинаре Veritas Software (www.veritas.ru), который прошел в Москве 6 апреля, менеджер компании по продукции и маркетингу в EMEA Адриан Греневельд огласил результаты прошлогоднего опроса, проведенного среди 850 ИТ-директоров из США, Западной Европы и Ближнего Востока. Как оказалось, в 84% компаний перебои в работе ИТ-систем возникают по крайней мере раз в год, в 26% - каждый квартал и даже чаще. При этом 14% опрошенных менеджеров заявили, что на их предприятиях перебои длились от 24 до 48 часов, и 16% компаний в результате аварий потеряли важную информацию. Одна из причин таких потерь - отсутствие или неэффективность процедур послеаварийного восстановления работоспособности компьютерных систем и данных. Интересно, что 17% компаний вообще не имеют плана таких работ, в 57% этот план не корректировался в течение года (хотя наверняка за это время в их ИТ-инфраструктуре произошли значительные изменения), 6% - никогда не пересматривали свои планы аварийного восстановления, а 25% никогда их не тестировали (прежде всего из-за того, что при таком тестировании неизбежен длительный перерыв в работе основной системы) .
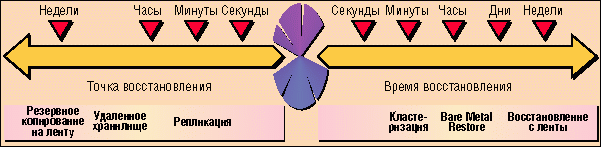
Шкала времени для оценки риска от аварий
Кроме того, опрос выявил еще одно слабое место в защите от аварий: 62% опрошенных заявили, что план аварийного восстановления их компании хранится только в центре обработки данных (ЦОД) - т. е. в случае крупной аварии на ЦОД он будет недоступен, всего 20% компаний держат его в другом здании и только 15% - в защищенном хранилище в третьей фирме. Наконец, 5% опрошенных вообще не знали, где он находится.
Как же предлагает Veritas реализовать аварийное восстановление? Прежде всего следует начать с планирования - определить сотрудников, которые будут участвовать в разработке плана и четко сформулировать роли и обязанности каждого (разумеется, не забыв проинформировать об этом самих ответственных лиц), затем определить риски возникновения аварий и ущерб от них, после чего можно сформулировать стратегии аварийного восстановления. С учетом доступного бюджета эти стратегии нужно детализировать в плане и внедрить необходимые для его выполнения решения. Теперь план должен быть опубликован, но на этом планирование аварийного восстановления не заканчивается: план необходимо регулярно пересматривать и не реже одного раза в квартал тестировать.
Для оценки рисков аварий Veritas предлагает использовать понятия целевой точки восстановления (RPO) - момента, до которого необходимо восстановить данные (фактически это допустимый объем потерянных данных), и целевого времени восстановления (RTO) - времени, необходимого на восстановление данных (работоспособности системы). Для систем электронной коммерции RPO и RTO не должны превышать нескольких секунд, а для принт-сервера эти показатели могут измеряться днями. Для некоторых приложений эти параметры могут отличаться на порядок - например, хотя для Web-сервера допустима потеря данных (RPO) за последние несколько дней, обычно перерыв в их работе (RTO) не должен превышать нескольких минут.
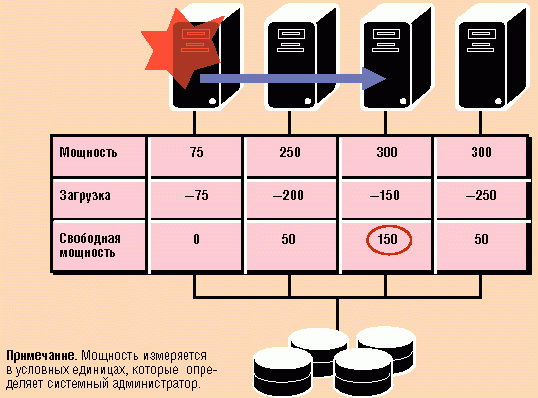
Управление переключением приложения в Veritas Cluster
В зависимости от RPO и RTO конкретной системы определяются оптимальные методы аварийного восстановления. Если эти показатели измеряются днями, то можно применять относительно медленное резервное копирование на ленту; когда речь идет о часах, то подойдет репликация данных, а для самых ответственных приложений, простой которых не должен превышать нескольких минут даже в случае природных и техногенных катастроф, следует использовать глобальную кластеризацию.
Для резервного копирования Veritas предлагает два основных решения - пакет программ Backup Exec, рассчитанный на обслуживание небольших сетей под Windows и NetWare, и NetBackup, предназначенный для гетерогенных сетей с серверами RISC и Intel. Адриан Греневельд сделал особый акцент на дополнительном ПО NetBackUp Vault, с помощью которого можно организовать дистанционное архивное хранение для обеспечения доступности данных в случае выхода из строя ЦОД. Этот продукт автоматизирует перемещение дубликатов лент в удаленное хранилище, контролирует их сохранение в течение заданного срока, после чего они стираются и возвращаются в ЦОД для повторного использования. Кроме того, NetBackUp Vault ведет единый реестр лент, находящихся в ЦОД и удаленном хранилище.
Другой дополнительный компонент NetBackUp под названием Bare Metal Restore (BMR) ускоряет восстановление сервера после аварии. Обычно после устранения аппаратной неисправности сервера (например, диска) требуется заново инсталлировать ОС, затем пакет резервного копирования и только потом с его помощью можно восстановить данные с лент. Все эти операции BMR заменяет одной командой, причем он способен идентифицировать изменения в конфигурации сервера, поэтому восстановление можно проводить на другой машине той же архитектуры.
Основой предлагаемых Veritas решений для репликации данных является ее пакет Volume Manager, создающий из физических дисков логические тома. Использование Veritas Volume Manager позволяет преодолевать аппаратные ограничения дисков, без перезагрузки добавлять в массив новые диски и менять конфигурацию логических томов дисковых массивов, а также использовать несколько копий данных. Возможности применения последней из перечисленных функций расширяет дополнительное ПО FlashSnap для создания мгновенных копий методом "расщепленного зеркала". Задействовав FlashSnap, можно получить для каждого тома до 32 копий на разные моменты времени, что может потребоваться не только для резервирования и быстрого восстановления данных, но и для их анализа на другой системе без прерывания работы основного приложения.
Кластерным решениям Veritas для обеспечения максимальной готовности систем и приложений на семинаре был посвящен доклад ведущего консультанта московского офиса компании Сергея Грищенко. В настоящее время большинство реализаций кластеров высокой готовности используют схему асtive/active (иначе называемую N:N), при которой на всех узлах работают приложения, а в случае отказа одного узла его приложения переключаются на другой, либо active:passive (N:1), когда один узел кластера выделен в "горячий" резерв. Однако обе эти схемы имеют серьезные изъяны - в кластерах N:N загрузка мощностей каждого сервера не должна превышать 50%, иначе он не справится с приложением, которое перейдет к нему с отказавшего сервера, а при использовании схемы N:1 один из серверов большую часть времени будет простаивать. В разработанном Veritas пакете Cluster Server применена схема асtive/active, но в дополнение к ней реализовано гибкое управление распределением нагрузки в многоузловой конфигурации: приложение с отказавшего сервера переносится на тот узел, где в данный момент имеется наибольшая свободная мощность.
Veritas Cluster Server поддерживает четыре основные архитектуры кластеризации, которые различаются степенью защиты от отказов и катастроф. Локальный кластер охватывает только одну площадку или здание, где находятся серверы и общий для них дисковый массив, и обеспечивает защиту от аппаратных или программных сбоев, но сам становится точкой отказа в случае катастроф. Городской (или кампусный) кластер является катастрофоустойчивым, но его построение требует больших затрат, поскольку узлы кластера должны быть подключены по Fibre Channel к сети хранения SAN, причем так, чтобы расстояние между ними не превышало 150 км. По словам г-на Грищенко, в Москве уже построено несколько таких кластеров для крупных организаций, у которых имелась сетевая инфраструктура Fibre Channel.
Альтернативным решением является кластер с дистанционной репликацией данных, узлы которого находятся на разных площадках и связаны между собой по более дешевому IP-каналу через Ethernet. При этом каждый узел имеет свою систему хранения и данные между ними реплицируются. Однако и у такой архитектуры есть недостаток - площадок не может быть больше двух (в последней версии Veritas Cluster Server 4.0 это ограничение устранено). Наконец, защиту от крупномасштабных катастроф обеспечивает кластер Wide Area Disaster Recovery, в котором удаленная резервная площадка располагается в нескольких тысячах километров от основной. При сбое на основной площадке переключение происходит как в локальном кластере, а при ее выходе из строя приложения переключаются на резервную. Разумеется, этот вариант является не только самым катастрофоустойчивым, но и самым дорогим: требуются большие затраты на поддержание "горячего" резерва на удаленной территории.
Упоминавшийся выше Volume Manager в катастрофоустойчивых кластерах используется для синхронного зеркалирования данных между площадками, соединенных каналом Fibre Channel, а если они связаны IP-каналами, то репликацию выполняет другой продукт Veritas под названием Volume Replicator.
Этот семинар стал первым большим публичным мероприятием, которое провел московский офис компании, а уже в сентябре нас ждет еще одна встреча со специалистами Veritas на конференции, посвященной ее подходу к реализации Utility Computing. В планах компании также русификация пользовательского интерфейса BackUp Exec, но сроки выполнения этого проекта пока не определены. Как выяснилось из завершившей семинар сессии вопросов и ответов, клиентов компании гораздо больше заботит отсутствие службы русскоязычной поддержки по телефону для продуктов Veritas. Ее региональный менеджер Василий Лиховайдо сказал, что возможен вариант, когда права на оказание такой поддержки будут предоставлены местным партнерам Veritas.













