













ОБЗОРЫ
Высокий уровень публичности ПО требует всестороннего и добросовестного тестирования
Массовое применение публичных сетей, коллективно используемых приложений и Web-сервисов словно переселило разработчиков корпоративного ПО из подсобных помещений в демонстрационные залы.
Клиенты и партнеры в цепочках поставок все больше используют сетевые приложения для выполнения неотложных транзакций; правительственные учреждения и органы общественной безопасности внедряют в свою деятельность Web-сервисы. В таких условиях отсутствие адекватного тестирования ПО равносильно халатному бездействию. Поэтому статус тестовых групп необходимо поднять на более высокую ступень.
Тестированию приложений суждено пройти тот же путь, которым недавно проследовала ИТ-безопасность. Сочетание возросшей осведомленности пользователей и госрегулирование отрасли трансформировало отношение к защите информации. Если раньше к этой области относились по принципу "к чему чинить крышу, если на дворе нет дождя", то теперь осознана необходимость прилежного исполнения разработчиками данной задачи. Значит, командам тестеров легче будет находить необходимые человеческие и технические ресурсы, а также добиваться средств на приобретение современных проверочных инструментов.
В границах разумного
Сем Кейнер, профессор по конструированию ПО из Технологического института шт. Флорида и директор Флоридского технического центра по обучению и исследованиям в области тестирования ПО, предлагает руководителям корпоративных разработок поразмыслить над вероятностью такого отказа приложения, в результате которого гибнут люди.
Не так уж трудно вообразить обстоятельства, когда причиной печального случая может стать единственная строчка кода, ни разу не подвергавшегося, несмотря на наличие соответствующих средств, тестированию. А в итоге и разработчик, и его организация - пользователь приложения попадают в классическую ситуацию для возбуждения иска о халатности.
На Web-странице Кейнера "Небрежности в разработке ПО и тестовое покрытие" (www.kaner.com/coverage.htm) перечисляется более ста разновидностей "покрывающих" тестов, которые обязаны присутствовать в арсенале разработчиков (во всяком случае, отказ от их применения должен иметь убедительные объяснения). Часть из этих тестов самоочевидны (и дороги), но тем не менее их недостаточно: примером является рекомендация "тестировать каждую строчку кода". Другие подходы не столь очевидны, но могут играть чрезвычайно важную роль - это, скажем, такие советы, как "варьировать местоположение каждого файла, используемого программой", или "проверять ПО на соответствие всем нормам, под которые подпадают данные либо процедуры приложения" (имеются в виду предписания налогового управления США, комиссии по ценным бумагам и биржам, управления по надзору за качеством пищевых продуктов и медикаментов и других ведомств).
В списке Кейнера есть и такие пункты, как аудит пользовательских руководств и файлов справки, контроль за соблюдением прав на использование авторских изображений и звуков или проверка приемлемости текстов и графики приложения для разных национальных культур. Разработчики не всегда задумываются над подобными аспектами, хотя от них во многом зависит, как примут их продукт конечные пользователи и как на него потом отреагирует рынок.
Все это лишь отдельные примеры тестов, удостоверяющих, что приложение отвечает исходным замыслам и функционирует, не нарушая принятые нормы. Впрочем, приложение может строго соответствовать этим критериям, но тем не менее быть неудовлетворительным.
В нем, например, может быть корректно реализован неправильный алгоритм, скажем, так, что он будет рассчитывать выгоду по формулам, описывающим начало, а не конец периода, или осуществлять оценки с привязкой не к финансовому, а к календарному году. При обновлении приложения его в целом правильное поведение опять же может расходиться с поведением прошлой его версии, разрушая существующие схемы интеграции приложений или совместного использования данных. Есть риск, что ПО откажет при непредусмотренных нагрузках или не справится с поддержкой неустойчивых сетевых соединений. Это примеры предметно-специфических и динамических аспектов тестирования приложений, которые должны пребывать в поле зрения современных разработчиков.
Наконец, при проектировании приложений для открытых сетей следует предвидеть возможность целенаправленных, устрашающе разрушительных атак, тщательно спланированных опытными хакерами. Недавно мы уже анализировали вопросы проектирования и создания ПО в связи с обеспечением защиты на уровне приложений, однако тестирование безопасности имеет свои специфические проблемы.

Ситуация в целом, как мы видим, весьма сложна, но, по словам Кейнера, отнюдь не безвыходна. Существует формальное доказательство, что исчерпывающая проверка не только бессмысленна практически - она теоретически невыполнима. И к халатности, говорит Кейнер, относится не тот случай, когда не сделано невозможное или даже что-то из возможного, а когда не сделано разумное и необходимое.

Поэтому надо учитывать, что хотя некорректные расчеты затрат и полезных результатов могут стать почвой для предъявления исков, перестраховка будет оправданной только в случае не менее строгой и добросовестной оценки стоимости дополнительного тестирования и выгод от снижения риска.
Критерий разумности не содержит однозначных рецептов. Разработчики не должны рассматривать тестирование как механическую процедуру или математическое упражнение с трафаретными признаками достаточности. Оно требует умелых подходов и выработки реальных процессов для последовательной и добросовестной проверки правильно выбранных аспектов работы приложения.
Способности автоматики
Кроме уже упомянутых типов проверок словарь тестирования содержит длинные перечни привычных и скучных задач под весьма красочными наименованиями.
Проверки класса "white box", или "glass box" (прозрачный ящик), предусматривают тестирование путей - разновидность покрывающего тестирования, при котором стараются проследить все мыслимые траектории, логически пересекающие приложение. В современных условиях это все более трудная задача, так как приложения группируются в соцветия сервисов, разрабатываемых и поддерживаемых независимыми командами. Проверки типа "black box" (черный ящик) игнорируют внутренние связи и затрагивают только публично объявленные интерфейсы к прикладному компоненту; поэтому их эффективность зависит от полноты спецификации ПО, что является редкостью, разве лишь за исключением наиболее ответственных областей.
Проверки типа "basis path" (базисный путь) используют знание внутренних связей для формализованной генерации контрольных примеров, а тесты типа "monkey" ("обезьяньи"), или в более вежливой терминологии - тесты "ad hoc", попросту опираются на случайный перебор функций приложения.
Эффективность и воспроизводимость сочетаются во всех этих методах по-разному. Формально генерируемые и воспроизводимые тесты, казалось бы, можно считать золотым стандартом, однако это золото окажется мишурой, если на их генерацию и выполнение понадобится столько времени, что их нельзя будет использовать в процессе разработок.
Момент, когда попытки исчерпывающего тестирования начнут выдавать нечто информативное, может наступить столь поздно, что от его результатов уже не будет толку. И разработчикам, пожалуй, лучше использовать более ранние и менее формальные тесты на базе опыта специалистов, знающих, где в приложениях чаще всего встречаются проблемы. Это серьезный аргумент против обычной практики, когда группы тестирования комплектуются из еще не оперившихся разработчиков или слабейших членов команды. Самые эффективные проверки осуществляют разработчики, которые разбираются лучше других в наиболее вероятных и наименее терпимых ошибках.
Независимо от методов тестирования и кадровой политики кажется логичным, что тестирование компьютерных приложений можно усовершенствовать, если его превратить в программируемую и налаженную процедуру. Под "автоматизацией контроля" часто понимают разработку сценариев или иных механизмов тестирования ПО при помощи других программ.
Важно понять, что это не единственный и даже необязательно наилучший подход. Ведь средства автоматизированных проверок - сами по себе программные продукты, которые могут содержать собственные дефекты или не иметь необходимых полезных качеств. Хорошо организованный архив уже проводившихся тестов, полученных результатов и внесенных улучшений может оказаться практичнее, чем загадочное собрание тестовых сценариев, возможно, уже устаревших из-за сравнительных небольших изменений в основном коде.
К тому же когда автоматизированные тесты выполняют не те, кто их разработал, они могут использоваться не совсем правильно и не улавливать ошибок. Например, тест может быть неприменим к граничным условиям, или коррективы в приложении могли изменить эти краевые условия. Выявление критических граничных условий и генерация тестов, сфокусированных на этих вероятных точках отказов, является одним из важных достоинств таких современных инструментов тестирования, как Agitator фирмы Agitar Software (см. обзор eWeek Labs продукта Agitator 2.0 на сайте www.eweek.com/labslinks).
Надо также учитывать, что автоматизированный тест может генерировать огромное количество ложных тревог. Представьте себе, например, как простое средство воспроизведения экранных команд для ГИП вдруг спотыкается о косметические изменения в компоновке интерфейса. Наверняка тест, генерирующий ложные тревоги, будет так или иначе игнорироваться, а сотрудники группы тестирования могут прийти к убеждению, что предупреждения об ошибках следует воспринимать с недоверием.
Автоматизированные проверки нередко выдают формально точную, но обманчивую статистику. Скажем, тест может проинформировать, что конкретная порция строк программы проверена определенное число раз, - не умея измерить и, следовательно, сообщить, действительно ли эти многократные тесты проверяли поведение ПО в разных ситуациях.
Дело самих разработчиков позаботиться, чтобы способ применения их инструментов отражал это различие. При развертывании ПО в среде Web важно также проверить, как приложение обрабатывает ошибки, инициированные его зависимостью от удаленных ресурсов. Это одна из сильных сторон продукта DevPartner Fault Simulator корпорации Compuware, находящегося на этапе бета-тестирования и планируемого к выпуску в первые месяцы этого года (см. рис. 1).
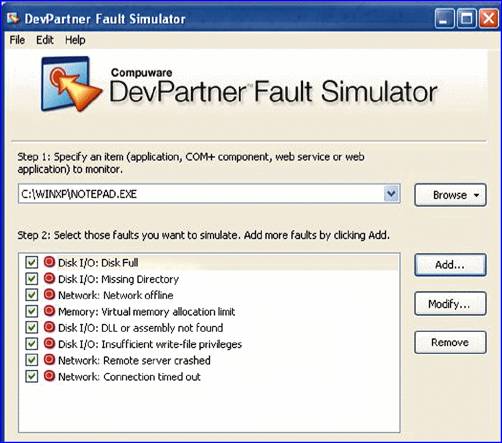
Рис. 1. DevPartner Fault Simulator помогает проверять устойчивость к внешним ошибкам
Автоматизированные тесты могут дать определенную уверенность, что приложение выполняет задуманные функции, но одновременно пропустить обширную мертвую зону, скрывающую вещи, которые ПО делать не должно.
Допустим, автоматизированная проверка способна легко удостоверить корректность изменений, вносимых в личные страховые данные. Тест, вероятно, даст и гарантию, что эти изменения соответственно отражаются в страховых данных супруга того же лица. Однако автоматические тесты зачастую пропускают появление изменений в тех местах, где их не должно быть. Например, если у отца появился новый ребенок, то разумная программа должна зарегистрировать этого ребенка и как сына его супруги. Однако программист может легко ошибиться, обобщив алгоритм так, что программа отметит как новоиспеченных родителей всех членов семьи - включая остальных детей.
Подобные дефекты ПО очень часто не замечаются, предупреждает консультант по тестированию ПО Брайан Марик из компании Testing Foundations в своей статье 1997 г. "Классические ошибки тестирования" (см. www.testing.com/writings/classic/mistakes.html).
И хотя такие ошибки уже давно вошли в категорию классики, их сплошь и рядом повторяют и сегодня.
Неспособность разработчиков предусмотреть подобные просчеты порождает серьезные дефекты ПО, открывающие дверь многим проблемам безопасности приложений. Программисты, как правило, хорошо представляют и могут протестировать все тонкости верного поведения приложения, прослеживая множество взаимодействий и сложных логических цепочек. Но они часто упускают из виду процессы, которые не должны происходить или должны быть заблокированы, если их кто-то попытается активизировать.
Хотя бдительный разработчик может эффективно выявлять непредусмотренное поведение ПО посредством протоколирования действий приложений, для этой процедуры нужен соответствующий код, требующий немалого времени на создание. Здесь помогут такие интеллектуальные инструменты, как AppSight 5.5 фирмы Identify Software (его последняя версия вышла в ноябре прошлого года), который умеет захватывать детальные данные о нестандартных ситуациях (см. рис. 2).
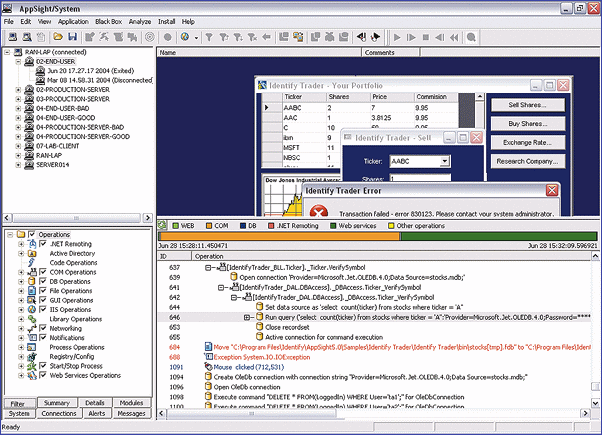
Рис. 2. Инструменты типа AppSight 5.5 позволяют протоколировать действия и поведение приложений
Мало признавать важность тестирования. Пока не отыщутся эффективные методы проверки значимых аспектов кода, тестирование ПО будет похоже на средневековую медицину. Отлаживать код, игнорируя фундаментальные пороки в конструкции приложения, - все равно что использовать кровопускание, не зная причин болезни пациента.
Автоматизированные средства тестирования не заменяют профессиональной дальновидности или предметно-специфического понимания того, что является важным, но они разгружают разработчиков от наиболее рутинных и трудоемких аспектов проверки приложений, высвобождая время для использования опыта и интеллекта.
С редактором по технологиям Питером Коффи можно связаться по адресу: peter_coffee@ziffdavis.com.













