













ПРОЦЕССОРЫ
Олег Фоминов
Как-то незаметно длЯ знаЧительной части ИT-сообщества в начале февраля произошло событие, грозящее полностью перевернуть все представления о создании "правильных" микропроцессоров. Речь идет об анонсе на International Solid-State Circuit Conference (ISSCC) процессора Cell.
К сожалению, данные об этом процессоре в открытые источники просачиваются довольно медленно, хотя задержка с публикацией и позволила нам собрать достаточно подробную информацию о нем.
Для начала позволим себе пару небольших отступлений, которые помогут выявить особенности Cell.
Кто в ответе за порядок
Мы не будем углубляться в хорошо известную нашим читателям историю разделения всего процессоростроения на две школы - CISC и RISC - и их последующего сближения, связанного с превращением "истинных" СISC в "псевдо-CISC" типа Intel Pentium 4, а "пуританских" RISC - в несколько перегруженные дополнительными командами и длинными многостадийными конвейерами чипы вроде POWER5. Главное, что можно вынести из этого противостояния, заключается в следующем: существует два вполне жизненных и принципиально разных подхода к проблеме оптимизации программного кода.

Представители RISC-лагеря считают правильным почти всю оптимизацию перекладывать на плечи оптимизирующего компилятора, не без основания считая, что современный компилятор достаточно "интеллектуален" для учета всех деталей реализации того или иного процессора. Кроме того, компилятор обладает сведениями об общей структуре обрабатываемой программы, закодированной в высокоуровневых конструкциях одного из алгоритмических языков программирования, что также положительно сказывается на качестве оптимизации, тогда как позже, на этапе исполнения кода, большая часть этих сведений теряется. В результате работы такого компилятора программа в машинных кодах представляет собой последовательный ряд низкоуровневых инструкций, которые при последовательном же исполнении процессором приводят к оптимальной загрузке всех процессорных блоков.
Поклонники CISC-подхода предпочитают при компиляции не столь глубоко оптимизировать программный код, перекладывая большую часть работы на процессор. Следование этому подходу связано прежде всего с тем, что машинные команды современных "псевдо-CISC"-процессоров довольно далеки от исполняемых ядром чипа микроопераций, на которые распадаются CISC-команды, так что для подобных процессоров программа в машинных кодах представляет собой лишь эдакий слегка оптимизированный и изложенный в довольно общем виде алгоритм, допускающий, в зависимости от типа используемых в конкретном "псевдо-CISC"-процессоре микроопераций, весьма широкую трактовку - правда, всегда дающую один и тот же результат. В результате сам процессор на этапе между декодированием команд и преобразованием их в микрооперации и исполнением микроопераций вынужден заниматься глубоким переупорядочиванием микроопераций, оптимизируя загрузку параллельно работающих логических блоков.
Следствием переупорядочивания микроопераций стало резкое усложнение чипов: в них появились "окна инструкций", где размещаются декодированные команды (точнее, их микрооперации) с учетом их взаимного влияния, множество дополнительных невидимых программисту "виртуальных регистров", в которых хранятся промежуточные результаты исполняемых в измененном порядке микрокоманд, а также подсистемы установления соответствия между "виртуальными" и доступными программисту регистрами ("механизм переименования регистров"). В результате современные "псевдо-CISC"-чипы с точки зрения программиста и с точки зрения проектировщика микропроцессоров выглядят совершенно по-разному.
Правда, в последнее время и многие RISC-процессоры обрели блок переупорядочивания микроопераций, но это почти не связано с появлением в чипах RISC-архитектуры многостадийных конвейеров исполнения команд - все же каждая RISC-команда остается весьма примитивной и обычно не предусматривает включения в работу множества логических блоков процессора. Скорее перед нами - попытка максимально оптимизировать исполнение не всегда хорошего готового машинного кода (скажем, наследованного от процессоров предыдущего поколения и оптимизированного под их особенности).
Педант заметил бы, что существует и принципиально иной способ программирования - речь идет об "архитектурах с очень длинными машинными словами" (Very Long Instruction Word, VLIW). Каждое такое "длинное слово" содержит полный набор инструкций для каждого процессорного блока, так что сам процессор становится крайне простым. По сути, перед нами - доведение RISC-концепции полного контроля над процессом исполнения команд до ее логического завершения.
Однако архитектура VLIW встретила две проблемы. Во-первых, оказалось, что создать компилятор, действительно в совершенстве оптимизирующий программу на столь низком уровне, очень непросто, а любой просчет компилятора из-за полного отсутствия "внутричиповой" оптимизации обходится очень дорого. Во-вторых, получается, что для разных задач будет оптимальной разная архитектура VLIW-кристалла, так что с универсальностью этих процессоров все обстоит не столь безоблачно, да и самая небольшая ошибка при выборе числа и типов логических блоков процессора опять-таки ведет к резкой потере производительности... В общем, единственная коммерчески доступная сегодня архитектура подобного типа, Intel Itanium, оказывается не слишком популярной (правда, в Intel свою процессорную архитектуру предпочитают называть EPIC, избегая термина VLIW, но суть от этого не меняется).
Опережая память
Независимо от выбора архитектуры процессорного чипа любой проектировщик сталкивается с проблемой слишком медленной работы ОЗУ (конечно, по сравнению с внутрипроцессорными скоростями). Обращаться к памяти приходится за программным кодом и за данными для этого кода, а также для записи результатов обработки данных. Всем известен простой способ ускорения работы подсистемы памяти - использование кэш-памяти.
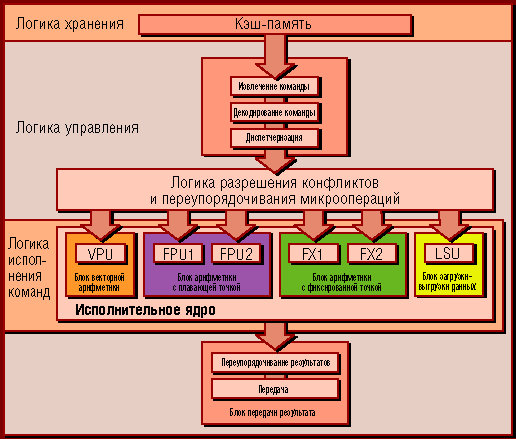
Блок-схема современного RISC-процессора семейства PowerPC.
Структура PPE должна быть почти такой же
Однако существуют и другие способы. Скажем, большое число регистров общего назначения в RISC-процессорах и отображение вершины стека вызовов в пул регистров - это способ создать внутри чипа сверхбыстродействующую оперативную память для данных. Заметьте его принципиальное отличие от применения кэш-памяти: в этом случае данными, помещаемыми в регистры, управляет программист (или оптимизирующий компилятор), так что эффективность процесса разделения данных на достойных и не достойных хранения в сверхбыстрой памяти гораздо выше, а необходимость в огромной, горячей и дорогостоящей кэш-памяти - заметно меньше.
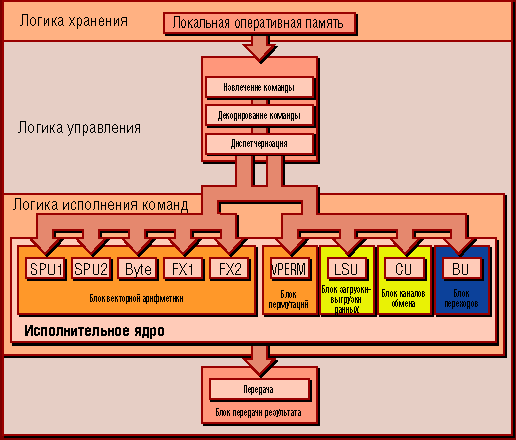
Блок-схема SPE - как видите, она значительно проще, чем у PPE
Вообще говоря, можно было бы сделать нечто подобное и для программного кода - чтобы в процессе работы алгоритма его части последовательно загружались во внутреннюю "программную память" чипа. В результате подсистема кэш-памяти для загрузки программного кода стала бы вообще (или почти) не нужна.
Что интересно - гипотетический чип, созданный в соответствии с этими посылками, должен был бы оптимальным образом применяться там, где можно создать достаточно компактные алгоритмы, "перелопачивающие" большие объемы данных, желательно - с высокой повторяемостью последовательных обращений к ним. Именно таково подавляющее большинство мультимедийных и вычислительных алгоритмов, сопровождающих взрывной рост сегодняшней "цифровой вселенной".
Соучастники
В 2001 г. компании Sony, Toshiba и IBM образовали альянс (названный по первым буквам имен компаний STI) для разработки принципиально нового процессора, вскоре получившего обозначение Cell. Целью STI, похоже, является преодоление засилья Intel в области микропроцессоров для компьютеров несерверного класса и бытовых устройств.
Надо сказать, что IBM уже однажды участвовала в подобной попытке - это был альянс AIM, образованный в 1991 г. компаниями Apple, IBM и Motorola для завоевания desktop-рынка путем выпуска недорогого и сверхбыстрого по тем временам процессорного семейства PowerPC (в качестве прародителя выступал серверный чип IBM POWER). Хотя в результате деятельности AIM мир получил очень достойные процессоры, основная цель альянса достигнута не была.
Однако есть надежда, что STI добьется большего успеха: разрыв между принципами построения x86-процессоров и Cell сегодня гораздо шире, чем между RISC- и CISC-системами в 1991 г. Более того, выбранная в Cell идеология является вполне естественной для RISC-систем, тогда как скрестить ее с CISC, пожалуй, можно только путем создания нежизнеспособного монстра либо смирившись с надругательством над привычками и опытом программистов. Так что процесс адаптации принципов, заложенных в Cell, займет у CISC-лагеря немало времени (конечно, если Cell окажется успешным).
Главным двигателем STI является, похоже, компания Sony, которая вскоре собирается перевести на Cell почти всю свою потребительскую электронику, начав с нового поколения игровых приставок PlayStation. Хотя и другие участники альянса не дремлют.
Управление Cell
Что же необычного в процессоре Cell? Прежде всего он - многоядерный. Причем ядер там не два, как в довольно давно выпускаемых кристаллах POWER или готовящихся к выпуску Pentium 4 и Opteron, а целых девять! Но еще необычнее то, что ядра эти вовсе не одинаковые (что отличает Cell, скажем, от будущего процессора Sun Niagara).
Управляет всем процессором ядро, являющееся прямым родичем настольных чипов PowerPC и называемое Primary Processing Entity (PPE). Все детали этого ядра пока неизвестны, так что приходится довольствоваться малым. PPE является 64-разрядным ядром архитектуры PowerPC с набором команд версии 2.02 (сегодня публично доступна версия 2.01), оно имеет как минимум один блок арифметики с плавающей точкой и снабжено совместимым с Altivec/VMX блоком векторной арифметики, что вроде бы превращает его в родного брата чипа PowerPC 970FX. С другой стороны, ядро PPE значительно проще: в нем уменьшено число логических блоков, вообще отсутствует подсистема изменения порядка исполнения команд, да и длина конвейера тут, несмотря на высокие тактовые частоты, относительно невелика - всего 21 стадия.
PPE поддерживает технологию Simultaneous MultiThreading (близкий аналог Intel Hyper-Threading) - в чипах семейства PowerPC такой возможности пока не встречалось, да и в их старших серверных братьях она появилась совсем недавно. SMT ядра PPE работает довольно просто: поддерживается две очереди команд на исполнение (два "виртуальных процессора"), при наличии подходящих команд в обеих очередях они последовательно "кормят" логические блоки процессора, при отсутствии таких команд в одной из очередей используют лишь команды из другой. Это позволяет добиться заметного прироста производительности ценой увеличения размера кристалла примерно на 7% (за счет дублирования регистров данных, статусных регистров, указателей и буферов команд). Подсистема SMT для PPE особенно важна, поскольку, напомним, тут отсутствует оптимизация загрузки процессора путем переупорядочивания исполнения команд.
Среди других черт, роднящих PPE c традиционными PowerPC, отметим раздельную кэш-память первого уровня (32 Кб с двумя ассоциативными наборами для инструкций и 32 Кб с четырьмя наборами для данных). Снабжен PPE и локальной кэш-памятью второго уровня - ее объем составляет 512 Кб. Похож PPE на обычные PowerPC и по устройству подсистем обработки прерываний и работы с виртуальной памятью.
Интеллектуальная мощь Cell
Если PPE выглядит всего лишь несколько странно, то восемь остальных ядер процессора Cell, называемые Synergistic Processing Elements (SPE), совсем уж необычны.
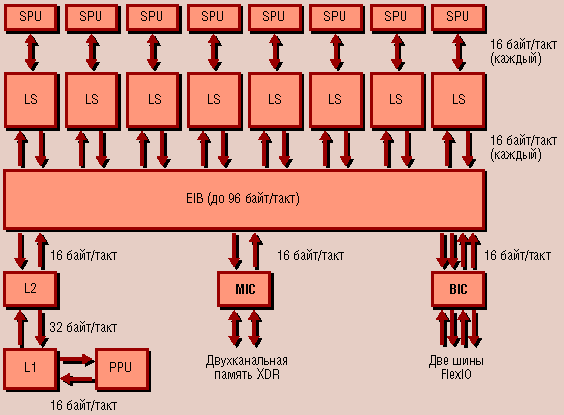
Блок-схема процессора Cell
Прежде всего каждый SPE состоит из двух подсистем - как такового процессорного ядра (SPU, Synergistic Processing Unit) и своей собственной локальной, напрямую адресуемой, сверхбыстрой оперативной памятью (LS, Local Store).
Главная черта ядра SPE (точнее, SPU) - то, что оно является не традиционным, а по сути чисто векторным 128-разрядным процессором. А поэтому и все регистры данных SPE - 128-разрядные, причем их аж 128 штук в каждом ядре! Можно сказать, что SPE реализует самые смелые фантазии создателей RISC-архитектуры...
Хотя система команд SPE несовместима с используемым в PowerPC 970 векторным блоком Altivec/VMX, она строилась на ее базе; кроме того, SPE разрабатывался с учетом опыта создания и применения векторного процессора Emotion Engine, используемого в игровой приставке Sony PlayStation 2 (набор команд которого является точным подмножеством набора SPE). Типы данных Altivec/VMX и SPE тоже очень похожи: регистр может интерпретироваться как вектор целочисленных данных (8-, 16 и 32-разрядных) или чисел с плавающей точкой (32-разрядных "одинарной точности" и 64-разрядных "двойной точности"). Хотя ядро SPE, в отличие от Altivec/VMX, поддерживает и плавающую арифметику с двойной точностью, все же оно явно оптимизировано для работы с одинарной точностью и выполняет операции с числами такого типа раз в десять быстрее. Так что для использования в качестве суперкомпьютерной "цифродробилки" в тесте Linpack процессор Cell подходит не слишком хорошо - все же он создавался для несколько иных задач...
Интересно, что первоначально инженеры из IBM пытались при создании SPE следовать канонам VLIW, однако столкнулись с серьезными проблемами и вернулись к уже хорошо обкатанной архитектуре SIMD-сопроцессора Altivec/VMX.
Как и в Altivec/VMX, каждая команда SPE может одновременно обращаться за данными к трем разным регистрам, а результат записывать в четвертый. Учитывая, что здесь имеются и соответствующие сложные команды (вроде команды одновременного умножения двух регистров и сложения с третьим, выполняемой всего за один такт), это позволяет чрезвычайно эффективно работать с векторной арифметикой.
SPU включает в себя девять логических блоков (два для арифметики с фиксированной точкой, два для плавающей одинарной точности и по одному для байтовых операций, пермутаций, загрузки-выгрузки, работы с каналами обмена и осуществления переходов). Эти блоки обслуживаются двумя очередями (одна обслуживает пять блоков, другая - четыре), так что две команды из разных очередей (скажем, сложение и пермутация) могут исполняться SPE одновременно.
Несмотря на сложность операций и четырехадресные команды, конвейер SPE получился очень коротким, не более семи стадий.
Но самой интригующей чертой ядер SPE является организация локальной памяти LS. Повторюсь: LS - это не кэш-память, а самая обычная оперативная память (правда, сверхбыстрая и статическая), так что программист, пишущий код для Cell, может полностью управлять распределением памяти для данных или кода, оптимизировать обмен данными между локальной памятью каждого ядра SPE и глобальным пулом и оптимизировать программы тем или иным способом.
Объем LS составляет 256 Кб, организованных как набор 128-разрядных слов.
Для обмена данными LS с оперативной памятью каждый пул LS может на аппаратном уровне (контроллером памяти MFC - Memory Flow Controller) по команде PPE синхронизироваться с локальной памятью PPE, так что в этом случае именно PPE отвечает за загруженность SPE работой и выгрузку ее результатов. Однако возможен и иной сценарий обмена: каждое ядро SPE может, воспользовавшись контроллером DMA, инициировать обмен данными с LS любого другого SPE или с памятью PPE (в SPE могут быть одновременно активными до 128 однонаправленных каналов DMA). Наконец, можно воспользоваться программно-аппаратной подсистемой виртуальной памяти, являющейся расширением принятой в PowerPC, и отобразить LS в общее адресное пространство Cell.
Отметим, что в принятой в Cell модели организации памяти ни о какой автоматической когерентности данных в разных пулах речи не идет и никакие изменения в LS, сделанные своим собственным локальным SPU, не отражаются в других пулах, пока об этом не будет спрошено специально. Именно это "ограничение" и позволяет оптимизировать использование разных пулов памяти без требования безумно высоких скоростей обмена по межъядерной шине данных (хотя и скорость, обеспечиваемую в Cell, маленькой назвать трудно).
Интересно, что один SPE может быть почти полностью изолирован от всех остальных для задач обеспечения безопасности. В результате, хотя в Cell и нет специально выделенного "процессора безопасности", архитектура чипа нисколько от этого не страдает, обеспечивая и защиту от несанкционированного доступа, и работу системы управления правами доступа к цифровому контенту. Детали реализации пока не разглашаются.
Располагая столь большим количеством SPE, программист может сам выбирать наиболее приемлемый способ обработки данных. Самый очевидный из них - параллельный, когда все SPE загружаются одинаковым программным кодом, но каждому отводится свое множество данных. Однако во многих случаях более интересным оказывается последовательная обработка данных, когда единый алгоритм делится на стадии и программа для каждой из них загружается в свое SPE. В этом случае одни и те же данные последовательно обрабатываются всеми участвующими в работе алгоритма SPE, перемещаясь из одной LS в другую посредством каналов DMA. Последовательные алгоритмы позволяют добиться меньшей задержки при обработке данных и при этом обойти ограничение на объем загружаемого в LS программного кода.
Второе пришествие Rambus
Процессор Cell необычен и с точки зрения используемых внешних интерфейсов: и память, и внешняя шина построены с применением технологий компании Rambus, что и не удивительно, - столь мощное ядро нуждается в соответствующем по производительности окружении.
Хотя с повсеместным внедрением памяти типа RDRAM у Rambus ничего не вышло, эта компания вполне успешно продолжает разработку методов быстрой передачи данных. Так, каждый интерфейс предложенной компанией памяти типа XDR (данная технология ранее была известна как Yellowstone) может работать на эффективной тактовой частоте до 3,2 ГГц (400 МГц, передача 8 бит за такт). При этом один канал XDR представляет собой две восьмиразрядные шины, что дает результирующую производительность обмена данными в 6,4 Гб/с. Поскольку обычный модуль памяти XDR имеет ширину шины данных в 32 бита, а в Cell используется двухканальный контроллер XDR, то пиковая скорость обмена с памятью здесь достигает 25,6 Гб/c - сравните это с максимальной на сегодня 8,5 Гб/с для двухканальных контроллеров DDR2-памяти! Единственный недостаток XDR состоит в том, что этот тип памяти только начинает цикл своего развития.
С внешним миром Cell общается при помощи двух независимых интерфейсов FlexIO разработки той же Rambus (также известен как Redwood I/O). Последовательный интерфейс FlexIO является дальнейшим развитием идей HyperTransport и способен работать в широком диапазоне частот, вплоть до 8 ГГц, когда достигается пиковая скорость обмена данными в 6,4 Гб/c по каждому из однонаправленных каналов. Дизайн процессора Cell предусматривает семь исходящих каналов FlexIO и пять входящих, что дает скорость 44,8 Гб/c на передачу и 32,0 Гб/с на прием по каждому из двух интерфейсов FlexIO, или суммарно около 150 Гб/c.
Использование шины FlexIO позволяет очень просто, без всяких дополнительных контроллеров, построить систему на двух чипах Cell (вторые интерфейсы FlexIO каждого процессора обслуживают периферию). Впрочем, можно пойти и дальше и построить настоящую сеть из десятков Cell - но тут уж понадобятся дополнительные служебные кристаллы.
Объединяющие кольца
Не менее интересна и шина Element Interface Bus (EIB), связывающая все рассмотренные ранее компоненты (девять ядер процессора, интерфейс внешней оперативной памяти и контроллер внешней шины) в единое целое.
Шина EIB представляет собой четыре 128-разрядных (т. е. 16-байтных) кольца, причем каждый компонент-"клиент" Cell имеет доступ ко всем кольцам. Причина выбора такой ширины шины очевидна - именно такова разрядность SPE. EIB тактируется на частоте, равной половине тактовой частоты процессора.
Все четыре кольца EIB однонаправленны, причем два из них передают данные в одном направлении и два - в противоположном, что снижает максимальную задержку при передаче данных.
Два любых "клиента" EIB могут совместно и одновременно использовать до трех кольцевых шин (три транзакции передачи), причем если потоки данных пар "клиентов" не пересекаются, то разрешается параллельная работа нескольких пар "клиентов". Аппаратно это реализуется при помощи алгоритма типа Token Ring с токеном, возвращаемым на кольцевую шину после удаления из нее полученных данных.
Любителям Гиннесса
Процессор Cell будет производиться по технологии SOI компании IBM с технологической нормой 90 нм. При этом площадь кристалла составит 235 мм2 (предварительный вариант процессора чуть меньше - 221 мм2) и состоит из 234 млн. транзисторов. Ожидается, что тепла он будет выделять от 50 до 80 Вт. Это, конечно, немало - скажем, экстремальный настольный Pentium 4 XE с 2 Мб кэшем, выполненный по сходному техпроцессу, имеет площадь ядра всего 135 мм2 и состоит всего-то из 169 млн. транзисторов, правда, выделяет 115 Вт. Но остальные параметры Cell с лихвой покрывают его некоторую "тяжеловесность".
По предварительным оценкам, даже работая при напряжении питания 1,2 В, чип будет способен достичь тактовой частоты 4,0 ГГц, пока недостижимой для процессоров Intel. Впрочем, и тут возможны варианты: продемонстрированные на International Solid-State Circuit Conference сотрудниками IBM графики показывают, что кристалл может работать и при напряжении 0,9 В (тогда тактовая частота составит 3,0 ГГц), и при 1,4 В (в этом случае процессор разгоняется уже до 4,6 ГГц).
Что еще интереснее - исследования показывают, что основной причиной нагрева Cell является PPE, а SPE даже при полной их загрузке греются довольно слабо! Так, при работе на тактовой частоте 2 ГГц один SPE выделяет всего 1 Вт, на 3 ГГц - 2 Вт, а на 4 ГГц - 4 Вт! В принципе, это позволяет устанавливать в Cell и большее число ядер SPE - если только вас не пугает возросшая площадь кристалла. Дальнейшие исследования показали, что у SPE имеется и неплохой "потенциал разгона": предварительные образцы SPE (и SPU, и LS) замечательно работают даже на частоте 5,6 ГГц!!!
Но большинство склоняется к тому, что первый коммерческий вариант Cell будет тактироваться на частоте 4,6 ГГц. Давайте оценим производительность различных подсистем такого чипа.
Учитывая, что одна операция со 128-разрядным вектором - это четыре операции с плавающей точкой, а ядро способно совершать две операции за такт, получаем быстродействие 36,8 ГФлопс на ядро SPE, или 294,4 ГФлопс на процессор целиком. И это без учета PPE, готового подкинуть в общий котел еще предположительно 36,8 (Altivec/VMX) плюс 9,2 (FPU) ГФлопс! Для сравнения: новейший Pentium 4 XE дает около 15 ГФлопс, так что налицо 20-кратное преимущество Cell в скорости над самым быстрым из CISC-процессоров.
Неплохим претендентом в "Книгу рекордов Гиннесса" выглядит и шина EIB. Каждое ее кольцо обеспечивает скорость передачи 36,8 Гб/c, что дает общую производительность 147,2 Гб/c.

Фото кристалла процессора Cell с отмеченными на нем подсистемами
О скорости подсистемы памяти и внешних шин мы уже говорили - и тут налицо прямой вызов сегодняшним рекордсменам!
Напоследок отметим, что Cell снабжен и современной системой оптимизации энергопотребления.
Перспективы
Главный вопрос, по-прежнему остающийся неясным, - как альянс STI собирается позиционировать Cell? Как-то слабо верится, что подобное чудо обречено питать лишь игровые приставки, телевизоры высокой четкости и прочую бытовую мелочь.
Общие соображения подтверждаются действиями IBM: на днях Голубой гигант объявил о программе помощи независимым компаниям в освоении и внедрении нового микропроцессора Cell, причем декларируется крайне широкая область применения чипа, включая качественную обработку в реальном времени изображений для аэрокосмической, оборонной и медицинской промышленности. Программа во многом строится по образцу ранее запущенной POWER EveryWhere, призванной максимально упростить для сторонних разработчиков создание заказных "систем на чипе" на базе ядра POWER, и обеспечивается силами уже хорошо известного подразделения Engineering & Technology Services (E&TS).
Интересна и реакция потенциальных конкурентов на выпуск Cell. Фред Вебер, технологический директор (CTO) компании AMD, в интервью, данном нескольким технологическим сайтам, выразил сомнение в успешности Cell, причем в качестве главного недостатка процессора была отмечена гетерогенность ядер. Такая позиция AMD понятна - ведь на подходе двухъядерные Pentium 4 и Opteron. Сложно спорить с утверждением, что универсальные ядра удобнее в программировании, чем специализированные, - но только попробуйте представить, сколько будет стоить и сколько выделять тепла гипотетический процессор с девятью одинаковыми ядрами класса Opteron, и все вопросы сами собой отпадут.
Так что успешность Cell, похоже, будет определяться успехом программ по внедрению процессора в устройства сторонних фирм и, главное, в головы программистов, создающих стандартные библиотеки для SPE.
Только в случае принятия Cell этим сообществом он может стать действительно процессором общего назначения и не повторит судьбу Itanium













