Чтобы масштабировать искусственный интеллект, организации должны адаптироваться к меняющейся роли современного хранилища данных. О том, как это сделать, на портале The New Stack рассказывает Тайлер Роквуд, главный инженер-программист Redpanda Data.
ИИ трансформирует любой бизнес, и каждая организация пытается выяснить, как они могут запустить его и извлечь из него выгоду. Где бы вы ни находились на дорожной карте, вот две истины, которые вы должны знать: ИИ нужен контекст, чтобы быть полезным, и уровень развития ИИ стремительно растет.
Хранилище данных — это первый ключевой момент: именно там сходятся организационные данные, что делает его идеальным центральным источником истины для агентов ИИ. Второй ключевой момент — нам также нужно, чтобы эта платформа была гибкой и могла идти в ногу с текущими инновациями.
Маховик данных
Как заявил генеральный директор Nvidia Дженсен Хуанг на прошлогоднем саммите Snowflake, ИИ позволяет извлекать больше с каждой фазой раскрутки «маховика данных» (Data Flywheel, концепция самоподдерживающегося цикла, в котором данные непрерывно способствуют улучшению системы и инновациям).
По сути, концепция маховика заключается в том, что люди, использующие ваши продукты, будут генерировать данные об их использовании; больше данных об использовании даст вам лучшее представление о том, как люди получают выгоду от ваших продуктов; и, в свою очередь, вы сможете лучше усовершенствовать продукт, в конечном итоге увеличивая его потребление (и получая больше данных). Давайте разберем, как ИИ улучшает вашу способность выполнять каждую из следующих фаз:
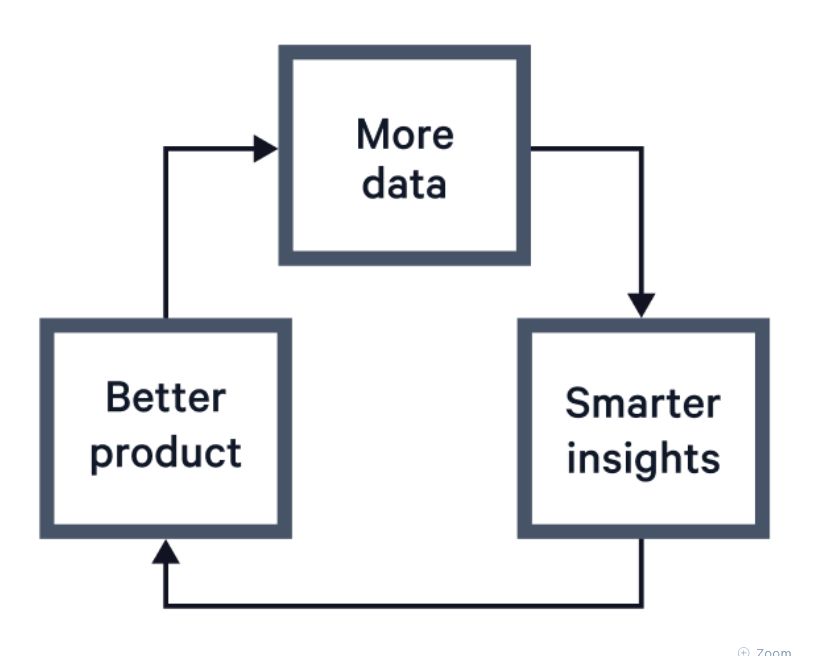
- Более «умные» инсайты. ИИ может улучшить процесс анализа данных несколькими способами. Он может автоматизировать процессы написания информационных панелей и SQL-запросов. Он может обрабатывать отчеты о неструктурированных данных — такие как отчеты об ошибках, отзывы пользователей и вопросы поддержки — выявляя общие тенденции и шаблоны. Вы можете использовать вложения для кластеризации информации в больших масштабах и выявления пробелов в пользовательских путях, а также упущенных возможностей.
- Лучшие продукты. ИИ можно интегрировать в набор продуктов разными способами: включение персонализации или рекомендаций в реальном времени, предоставление пользователям возможности автоматизировать задачи или использование моделей для обобщения исторической активности и тенденций. Важной частью при интеграции ИИ в продукт является добавление защитных барьеров, измерение производительности и предоставление вам и вашим пользователям уверенности в том, что агентная автоматизация работает так, как задумано. Наконец, продуктовые команды и команды разработчиков могут интегрировать ИИ в свои рабочие процессы, чтобы быстрее отправлять и тестировать новые функции, что позволит им сокращать, а не увеличивать сроки.
- Больше данных. Продукты, оснащенные ИИ, открывают широкие возможности для фиксации и измерения вовлеченности, наблюдая за тем, какие подсказки отправляются чат-ботам, или используя ИИ для рассуждения о данных, которые было бы слишком утомительно анализировать вручную. Кроме того, такие функции, как автоматизация на основе ИИ, позволяют опытным пользователям глубже погрузиться в ваш продукт и извлечь еще больше ценности. Модели также способны очищать и извлекать структуру из ранее непригодных для использования источников — озер данных, предоставляя вам еще больше данных для работы.
Создание оснащенных ИИ продуктов
Нельзя просто прилепить чат-бот к существующему продукту и назвать его оснащенным ИИ. Нужно поразмышлять и постараться понять, где вы можете получить наибольшую ценность, избегая при этом рисков, связанных с этой новой и недетерминированной технологией.
Главное, что следует помнить, — эти модели не хранят состояние и не располагают контекстом относительно того, какую задачу вы пытаетесь побудить их выполнить. Вы должны предоставить им всю информацию и инструкции, необходимые для выполнения их задачи. Этот контекст должен быть как точным, так и актуальным: устаревшая информация подрывает производительность, приводит к дрейфу и вносит риск в принятие решений.
Например, агенту-представителю по развитию продаж необходимо знать, какие новые функции были запущены или какие болевые точки могут испытывать потенциальные клиенты. ИИ, работающий от имени вашей службы поддержки, должен уметь определять другие недавние проблемы, рекомендовать обходные пути для распространенных проблем и быстро выводить на экран соответствующую историческую информацию о клиенте и использовании им продукта.
Чтобы запустить этих агентов, вам необходимо хранилище данных, в котором вся эта информация доступна. Вам необходимо иметь возможность добавлять данные из любой точки вашего предприятия в централизованный банк данных. Более того, информация в хранилище должна быть актуальной — никто не хочет получать рекомендацию для старой версии продукта или неправильно определять болевые точки, с которыми вы можете помочь потенциальному клиенту.
Благодаря новейшим достижениям ИИ разрыв между пониманием и действием сокращается. Появляется возможность вызывать агента для реагирования на событие при его возникновении, а не при выполнении следующего задания. Учитывая быстрые ИИ-инновации вам нужна платформа данных, которая достаточно гибка для размещения новых функций и удовлетворения новых требований.
Потоковая передача — ключ к гибкой платформе данных
Создание платформы данных сильно зависит от вашего технологического стека, поставщика инфраструктуры и отрасли. Однако все они имеют общие шаблоны, и один из них особенно важен для быстрой итерации: потоковая передача.
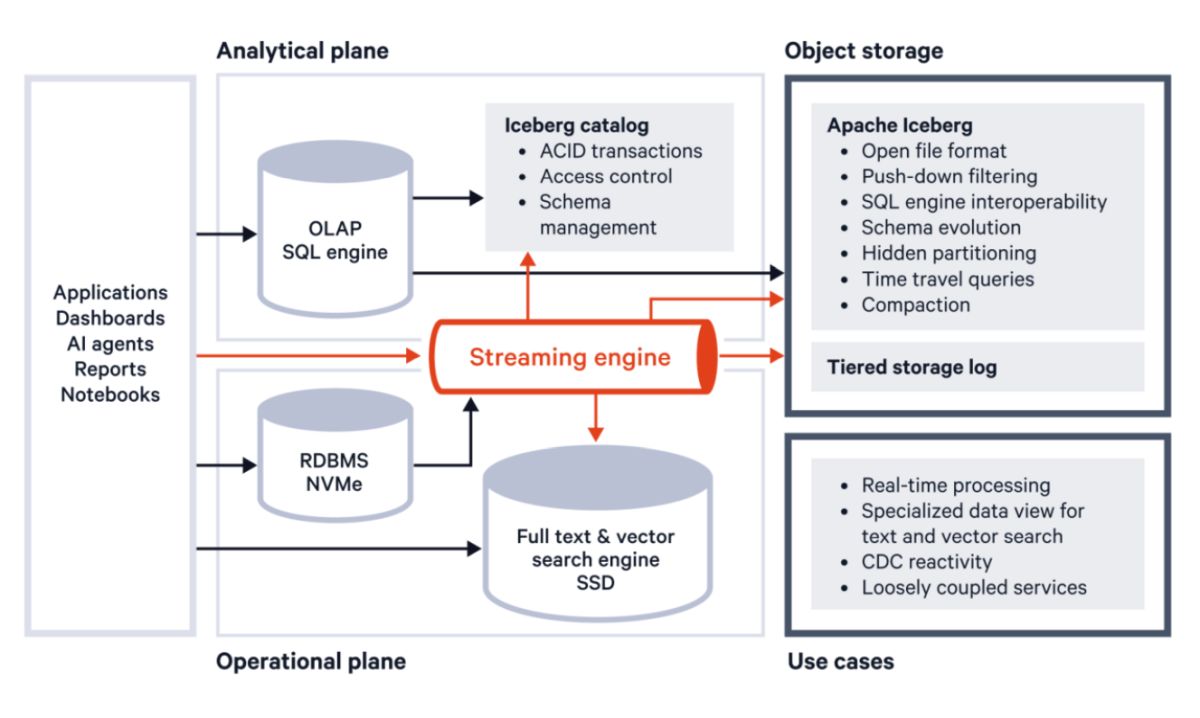
Потоковая передача данных — это непрерывный, инкрементный поток данных, отправляемых в шину сообщений или журнал предзаписи (WAL). Основное преимущество внедрения потокового движка заключается в том, что он позволяет вам разделить производителей (приложений, генерирующих события) и потребителей (получателей записей в журнале). Это позволяет легко динамически добавлять или удалять источники, используя ваши данные реального времени, выводя последнюю информацию в ваши приложения и запуская агентов, когда событие происходит впервые.
Возьмем в качестве примера полнотекстовую или векторную поисковую систему. В этих системах индексация данных приводит к перестройке различных структур на диске (особенно в векторных базах данных, которым требуется большая языковая модель для вычисления вложений для каждого фрагмента текста). Это делает пакетные операции, выполняемые из одного источника, гораздо более эффективными. Кроме того, воспроизводимость долгоживущего потока привлекательна при тестировании различных моделей вложений или различных методов фрагментации в ваших конвейерах генерации с расширенным поиском (RAG).
Традиционными методами это было бы неосуществимо, но современные потоковые движки могут использовать многоуровневое хранилище для выгрузки холодных данных в объектное хранилище, а это означает, что вы можете сохранить полную воспроизводимость без необходимости прокладывать другой путь данных. Все эти вспомогательные системы могут стать материализованными представлениями потока необработанных событий.
Другой пример — использование сбора данных об изменениях (CDC) из систем баз данных и запись их в потоковый механизм. Это позволяет вам иметь потребителей, которые передают изменения из базы данных по мере их возникновения, обеспечивая реакцию на события в базе данных. Это также помогает обеспечить наличие копии реляционной базы данных у вспомогательных систем данных (например, полнотекстового/векторного поиска или аналитической базы данных), не усложняя приложения попытками синхронизировать все эти системы.
Как правило, потоки CDC довольно дорогостоящие, поскольку они могут препятствовать очистке WAL или нагружать базу данных иначе, чем обычный трафик базы данных. Но если создать единый
Например, вы можете вызвать агента и проанализировать, что происходит, когда пользователь внезапно понижает свой аккаунт. Выполнение этого через поток CDC для таблицы user_plans означает, что прикладному уровню не придется перестраивать свою систему, чтобы позволить другим приложениям реагировать на эти изменения.
Открытые форматы = свобода и гибкость
Точно так же, как потоковая передача была центральной для описанных выше операционных сценариев использования, эти же события могут быть материализованы в вашем хранилище данных, предоставляя вам свежую и актуальную информацию для ваших аналитических запросов. Прямые данные событий можно преобразовать в открытые форматы, такие как Apache Iceberg (некоторые потоковые движки могут делать это напрямую), или транслировать их в проприетарные форматы (пример: потоковая передача Snowpipe в Snowflake). В качестве альтернативы потоки можно объединять и обрабатывать в режиме реального времени, чтобы обеспечить поступление данных в любой форме для максимального удобства запросов, без дорогостоящих пакетных заданий, которые постоянно перерабатывают весь набор данных.
Открытые форматы, такие как Apache Iceberg, дают вам свободу и гибкость в выборе из ряда различных движков запросов. Например, предположим, что вы являетесь пользователем Google Cloud Platform, но используете Snowflake в качестве хранилища данных для бизнес-аналитиков и ИИ-команд. Использование Apache Iceberg означает, что вы можете оставить Snowflake в качестве основного хранилища данных, но также задействовать BigQuery и все интеграции, доступные для обслуживания и обучения моделей, без необходимости хранить данные дважды. Это происходит без ограничения функциональности на любой платформе, поскольку Apache Iceberg поставляется с полной транзакционной моделью ACID, четко определенными политиками эволюции схем, запросами, позволяющими получить состояние в определённый момент времени, и тонким контролем доступа через каталог, подобный Apache Polaris.
Проприетарные системы управляют как данными, так и метаданными для хранилища данных. Однако с Iceberg у вас есть возможность либо хранить метаданные в проприетарных системах, либо для управления метаданными выбрать открытый стандарт, такой как каталог Apache Iceberg REST.
Потоковая передача также позволяет преобразовывать и объединять ваши данные, когда они уже находятся в движении, что избавляет вас от дорогостоящей повторной обработки данных в больших пакетных заданиях. Например, если вам нужно выполнить требования комплаенса или маскирования, прежде чем данные попадут в долгосрочное хранилище в аналитической плоскости вашей платформы данных, вы можете выполнить небольшое преобразование ваших данных без сохранения состояния в момент их попадания в хранилище данных.
Лучшие практики и будущее ИИ-нативных платформ данных
Использование потокового движка в качестве ядра вашей платформы данных обеспечивает большую гибкость и отзывчивость, позволяя вам использовать ваши данные в режиме реального времени. Если у вас слабосвязанная система, которая быстро меняется, вам следует иметь в виду несколько лучших практик, направленных на обеспечение устойчивости и надежности.
Прежде всего, важно иметь реестр схем, чтобы при настройке новых приложений на чтение из ваших потоков данных они могли беспрепятственно и безопасно работать с эволюцией схемы. Эти схемы становятся контрактом между командами, так же как службы на основе HTTP имеют API-контракты. При потоковой передаче в хранилище данных поддержание синхронизации ваших схем между вашим реестром схем и каталогом механизма запросов может гарантировать, что пакетные и потоковые системы работают с согласованным представлением данных. Подключение изменений и публикаций схемы в рамках ваших конвейеров CI/CD и инфраструктуры как кода (IaC) также может помочь вашим инженерным группам выявлять проблемы на ранних этапах разработки, а не в промежуточных или производственных средах.
По мере роста вашей организации и внесения группами изменений наличие механизмов для определения их происхождения может помочь вам быстро отслеживать проблемы или понимать, откуда поступают данные. Использование передовых методов, таких как отслеживание стандартных соглашений OpenTelemetry и распространение трассировки с использованием заголовков записей, особенно полезно, поскольку организации принимают OpenTelemetry для всех своих данных наблюдаемости.
Хотя архитектуры, управляемые событиями, позволяют создавать адаптивные, устойчивые и отзывчивые платформы, их можно считать дорогими. Вы можете снизить расходы, используя такие функции, как многоуровневое хранилище для выгрузки данных в холодное хранилище, сжатие для уменьшения размера хранилища и требуемой пропускной способности, эффективные форматы, такие как Google Protocol Buffers или Apache Avro, и настройку пакетной обработки для обеспечения быстрой и производительной потоковой системы. Как и в случае с любой другой системой, начните с хорошей наблюдаемости и отслеживайте использование по мере расширения платформы и масштабов использования.
В то время как лучшие практики в области безопасности и эти новые приложения ИИ постоянно развиваются, основы для платформ данных — такие как контроль доступа на основе ролей, детальные списки контроля доступа (ACL) и принцип наименьших привилегий — применяются как к потоковым, так и к пакетным наборам данных. Воспользуйтесь такими стандартами, как OpenID Connect для аутентификации и ведения журнала аудита, чтобы контролировать доступ единообразно во всех системах.
Наконец, платформы потоковых данных реального времени позволяют развивать такие тенденции, как ИИ в операциях (AIOps), чтобы системы данных могли отслеживать, оптимизировать и реагировать на изменения в режиме реального времени. Без потоковой передачи данных вам придется периодически настраивать задания, что увеличит цикл итераций и уменьшит объем обучающих данных для агентов ИИ, которые будут выполнять операционные задачи на платформе.
Резюме
По мере развития технологий разрыв между пониманием и действием сокращается. Автоматизированные системы могут производить и обрабатывать данные мгновенно, а ИИ позволяет использовать эти данные в областях, где ранее это было невозможно.
Потоковая передача как основа платформы данных позволяет использовать все эти возможности в режиме реального времени, и она будет становиться все более важной по мере демократизации ИИ с помощью Open Source-моделей, а также по мере снижения стоимости внедрения этих мощных моделей ИИ. Поскольку организации стремятся ко все большей автономии своих ИТ-систем, важно убедиться, что ваша платформа данных разработана таким образом, чтобы реагировать в режиме реального времени и идти в ногу с темпами инноваций.