ИТ-индустрия любит свои стеки. Сначала был стек LAMP, затем стал популярен стек Hadoop. За последние пять лет в нашей коллективной психике укоренилось нечто, называемое Modern Data Stack (MDS, современный стек данных), а теперь появились слухи о Composable Data Stack (композитный стек данных), сообщает портал Datanami.
ИТ-стеки выросли из желания делать как можно меньше работы по интеграции при сборке производственных систем, обычно из частей с открытым исходным кодом. В 2005 г. вы могли загрузить все части оригинального стека LAMP — операционную систему (Linux), веб-сервер (Apache), базу данных (MySQL) и язык программирования (PHP или даже Python или Perl) — и соединить их вместе для обслуживания веб-приложений, не заключая огромный контракт с системным интегратором.
К 2010 г. наступила эра Hadoop, которая ознаменовалась очередными упражнениями со стеками. Изначально построенный на сочетании распределенной файловой системы (HDFS) и вычислительного фреймворка (MapReduce), стек Hadoop рос и рос, в итоге превратившись в набор из примерно двух десятков различных проектов (Hive, Spark, HBase и т. д. и т. п.).

В теории это звучало прекрасно, но на практике поддерживать актуальность «диаграмм спаржи» (asparagus charts), не говоря уже о совместимости десятков постоянно развивающихся Open Source-проектов, для компаний Hortonworks и Cloudera оказалось слишком сложно, и большой желтый слон и связанный с ним стек рухнули.
Подъем MDS
Хотя бизнес-модель Hadoop официально умерла в
MDS начал укореняться примерно в то же время, когда «большие облака» начали забирать рабочие нагрузки, связанные с большими данными. Вместо того чтобы пытаться запустить свой собственный стек аля Hadoop, поставщики публичных облаков, такие как AWS, предоставляли клиентам сервисы данных, такие как Glue для ETL, RedShift для анализа данных SQL или Elastic MapReduce (EMR) для традиционных рабочих нагрузок Hadoop. У Google Cloud был свой собственный стек, основанный на BigQuery, также свои стеки предлагали Snowflake, Microsoft и, в конце концов, Databricks. Вариантов развертывания и ручек для настройки было не так много, но в итоге это оказалось хорошо, так как клиенты быстро освоились.
Сегодня облако — неотъемлемая часть MDS. Предполагается, что если у вас есть MDS, то вы используете его компоненты в современном облачном стиле, что означает отделение вычислений от хранения и обеспечение бесконечной масштабируемости с помощью контейнеров и бессерверных технологий и методов. Поэтому инструменты, которые окружают MDS и взаимодействуют с ним, также должны соответствовать этой новой облачной эре, в отличие от старой эры локальных вычислений и хранения.
Одним из сторонников MDS является компания Alation, поставщик каталогов данных и инструментов управления. В 2023 г. она сообщила, что ее MDS состоит из хранилища данных, ETL-инструмента, сервисов ввода и интеграции данных, обратного ETL, оркестровки данных и инструментов бизнес-аналитики. «Современный стек данных, как правило, более масштабируемый, гибкий и эффективный, чем старый стек данных, — заявила Alation. — Современный стек данных опирается на облачные вычисления, в то время как устаревший стек данных хранит данные на серверах, а не в облаке».

MongoDB — еще один сторонник MDS. Как и Alation, она использует эту аббревиатуру для обозначения предварительно интегрированных комбинаций ПО, работающих в облаке. Компания считает себя участником нескольких стеков больших данных, включая MEAN, в который входят MongoDB, Express, Angular и Node; MERN, в который входят MongoDB, Express, React.js и Node; и MEVN, в который входят MongoDB, Express, Vue.js и Node.
Стеки порождают стеки
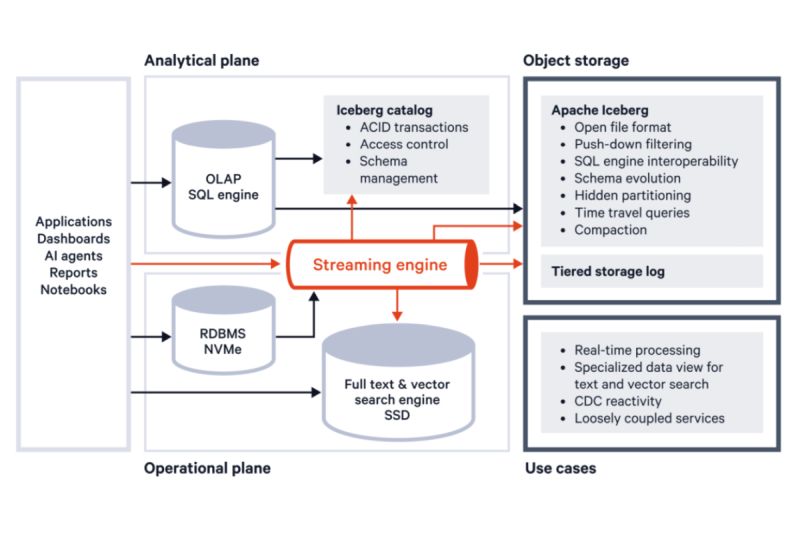
Компания InfluxData, разрабатывающая базу данных временных рядов, делает ставку на будущее InfluxDB на стеке FDAP. FDAP, согласно InfluxData (которая придумала этот термин), означает сочетание нескольких проектов Apache Arrow, включая Flight (сетевой протокол), DataFusion (механизм запросов) и сам Arrow (формат столбчатых данных in-memory), а также Parquet (формат столбчатых данных на диске).
Экосистема Arrow в настоящее время быстро развивается, поэтому разработчикам больших данных имеет смысл использовать ее как ядро более крупного стека.
Уэс Маккинни, создатель Pandas и один из создателей Arrow, недавно выступил соавтором статьи «Манифест композитной системы управления данными», в которой говорится о росте числа сотен систем управления данными, каждая из которых создает монолитное хранилище данных, препятствующее интеграции и прогрессу. Выход, как нетрудно догадаться, заключается в том, что они называют «композитной системой управления данными».
«Мы выступаем за изменение парадигмы проектирования систем управления данными, — пишут Маккинни и соавторы. — Мы считаем, что, разложив их на модульный стек многократно используемых компонентов, можно упростить разработку, создав при этом более последовательный опыт для пользователей».
")
Предлагаемый Composable Data Stack строится на основе популярных Open Source-компонентов, таких как форматы данных Arrow, ORC, Parquet, Hudi и Iceberg; обработчики столбчатых запросов Velox и DuckDB; оптимизаторы запросов Apache Calcite и Orca; а также фреймворки выполнения Ibis, Spark, Ray и даже старый добрый MapReduce.
«Несмотря на общие архитектурные решения, структуры данных и внутренние методы обработки данных, степень их повторного использования на сегодняшний день весьма ограничена, — пишут авторы статьи. — Мы считаем, что, компонуя системы управления данными, можно ускорить темпы инноваций».
Теперь мы все в клубе MDS
Но не все согласны с тем, что стек MDS больше не нужен. По мнению Тристана Хэнди, соучредителя и генерального директора dbt Labs, идея всеобъемлющего стека для больших данных сейчас неактуальна.
Недавно он поделился своими мыслями о том, почему мы, возможно, живем в мире «после стека данных»: «Когда я был консультантом, помогая небольшим компаниям создавать аналитические возможности, я работал только с инструментами MDS. Они были настолько лучше, что я просто не брался за проект, если клиент хотел использовать дооблачные инструменты. Этот термин на самом деле передавал важную информацию... которая сейчас уже изжила свою полезность».
По словам Хэнди, ситуация с данными на местах кардинально изменилась, и сегодня большинство продуктов для работы с данными уже специально создано для облака. «Либо они были созданы за последние 10 лет и, следовательно, в них заложены особенности облачных технологиях, либо они были перепроектированы под облако», — пишет он.
Чтобы доказать свою точку зрения, Хэнди сравнил Looker и Tableau. Looker, который Google купила несколько лет назад, называли более современным набором аналитических инструментов для работы с облачными хранилищами данных, такими как Amazon Redshift. Tableau, которую несколько лет назад приобрела компания Salesforce, была доминирующим поставщиком дооблачной эпохи и ее решение хорошо подходило для работы с локальными хранилищами данных предыдущей эпохи. И хотя в 2016 г. Tableau не обладала такими же облачными возможностями, как Looker, команда Tableau проделала большую инженерную работу, чтобы предоставить эти возможности, и таким образом вошла в клуб MDS.
По словам Хэнди, таких примеров можно привести множество. «Я разговаривал с основателями многих таких компаний, и „миграция в облако“ почти всегда представляет собой мучительный марш-бросок по пустыне, — пишет он. — Но это настолько экзистенциально, что все равно все это делают (или погибают при попытке)».
Ярлык MDS теряет былую популярность
Почти все поставщики инструментов для работы с большими данными теперь могут с уверенностью сказать, что они являются частью клуба MDS, что в некотором смысле свело на нет полезность этого термина в качестве рыночного дифференциатора. Этот факт, а также ухудшение рыночной конъюнктуры в 2023 г., вместе взятые, выбивают почву из-под ног MDS.
«К 2021 г. интерес к MDS официально угас», — пишет Хэнди.
Это не значит, что покупатели не выиграли от наличия предварительно интегрированных инструментов, или MDS, если хотите. По словам Хэнди, готовность покупателей создавать стек из продуктов восьми-двенадцати поставщиков значительно снизилась. «Сегодня компании гораздо чаще рассчитывают приобрести от двух до четырех продуктов в качестве ядра своей аналитической инфраструктуры, — пишет он. — Это создает еще большее давление в плане консолидации и, вероятно, приведет к росту активности в сфере слияний и поглощений и конкуренции между поставщиками».
Фоном для всего этого является развитие искусственного интеллекта и генеративного ИИ (GenAI). Хотя MDS и GenAI дополняют друг друга, просить потенциальных покупателей или инвесторов держать в голове две идеи одновременно — это слишком, считает Хэнди.
«MDS была большой и важной тенденцией на рынке, — пишет он. — Но ИИ — это нечто большее. Намного большее. А инвесторам в данные и покупателям данных трудно сосредоточиться на многих тенденциях одновременно».
В конце концов, использовать ярлык MDS — значит вести уже закончившуюся войну. «Облако победило; все компании, занимающиеся данными, теперь являются компаниями, занимающимися облачными данными. Давайте двигаться дальше, — призывает Хэнди. — Будущее нашей индустрии — это аналитика».