Базовые возможности облачного сервиса хранения данных Amazon Simple Storage Service (S3) рассматривались в статье “Как хранить данные в облаках Amazon”, однако этот сервис предоставляет ещё целый ряд услуг по хранению информации, только они более специализированны.
Храним редко используемые бэкапы по дешёвке
Сервис S3 сам по себе весьма недорогой в сравнении, например, с расценками на веб-хостинг. Однако Amazon предлагает и более дешёвое по отношению к S3 (причём почти на порядок, всего один цент на гигабайт в месяц) облако Glacier, ориентированное на обработку редко используемых данных — например, объёмных архивов и бэкапов. Данные содержатся и передаются только в зашифрованном виде с помощью технологий SSL и AES. Надёжность и целостность обеспечиваются на беспрецедентном уровне 99,999999999% за счёт системы периодической верификации хранимой информации, её распределённого хранения в нескольких физически разнесённых копиях и т. д. По этой причине выбирать подходящий регион с ближайшим ЦОДом Glacier не позволяет: формально доступен только один дата-центр в США (по слухам, это крупный ЦОД с дешёвыми жёсткими дисками и даже с ленточными накопителями, для виртуальной замены которых он и позиционируется). Сделано так потому, что Glacier не предназначен для срочного использования хранимой информации. Так, выгрузку своих данных придётся скорее всего ждать часами (официально заявлено о 3–5 ч), причём основные расходы придутся именно на этот процесс. Оперативное получение своих данных в принципе тоже возможно, только обойдётся такой вариант сервиса уже сильно дороже.
Пользовательские архивы в Glacier держатся в “погребах” (vaults). Создание последних столь же просто, как и формирование “вёдер” в S3 — например, через консоль управления AWS или программным путём. Но Glacier в отличие от S3 не поддерживает ручной режим загрузки и выгрузки самих архивов в “погреба” — он фактически функционирует в пакетном режиме, ведь заставлять пользователя часами ожидать ответа в браузере негуманно. Клиентам Glacier предоставляется простой программный интерфейс, который можно реализовать на платформах .NET или Java. Достаточно единичных строчек кода, чтобы активизировать процесс обмена данными с “погребами”.
Glacier хорошо интегрируется с различными сервисами Amazon. Так, данные между S3 и Glacier можно свободно перемещать, в том числе и в автоматическом режиме, с помощью правил поддержки жизненного цикла объектов S3.
Организуем оперативную и надёжную поставку контента
После того как данные загружены в хранилище S3, пользователи могут их скачивать свободно или в платном режиме. Однако качество доставки этих данных будет зависеть от того, какой физический ЦОД был выбран для их размещения. Особо важно учитывать этот момент, когда S3 используется для хостинга сайтов (скорость загрузки HTML-страниц играет важную роль) или для распространения объёмных данных (например, в качестве видеохостинга).
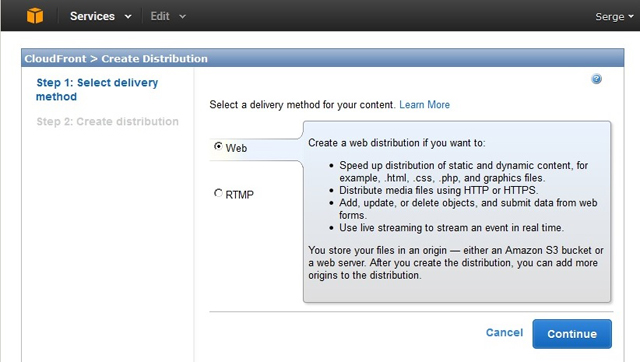
Веб-сервис Amazon CloudFront обеспечивает надёжную и быструю поставку контента через распределённую сеть ЦОДов с помощью продуманной системы маршрутизации, минимизирующей время задержки. Только в декабре 2013-го к этой сети были подключены ЦОДы на Филиппинах, во Франции и Польше. Для активации CloudFront предварительно требуется загрузить данные в хранилище S3 и сделать их общедоступными. Подлежащий распространению дистрибутив будет сформирован на основании одного из “вёдер” S3 со всем его содержимым. Далее надо перейти в консоль CloudFront, которая предложит единственную функцию создания на основе выбранного “ведра” дистрибутива Create Distribution, подлежащего оптимизированному распространению. Формат дистрибутива может быть веб-ориентированным (преимущественная поставка по протоколу HTTP) или рассчитанным на поставку потоковых данных по протоколу Real Time Messaging Protocol (рис. 1).
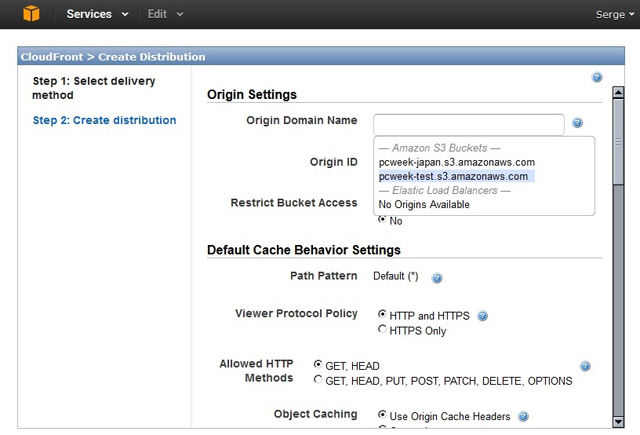
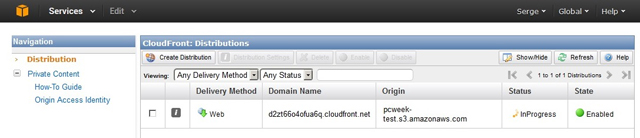
На втором, финальном, шаге задаются различные настройки процесса поставки, большинство из которых можно оставить выставленными по умолчанию. В поле Origin Domain Name надо указать одно из доступных “вёдер” S3, и нажать Create Distribution (рис. 2). Через некоторое время (от несколько минут и дольше, в зависимости от объёма “ведра”) сервис сформирует финальный адрес надёжного варианта поставки, который и надо будет предоставлять пользователям вместо прямых ссылок на объекты S3 (рис. 3). Дополнительно можно настроить альтернативные доменные имена для дистрибутива, дабы он выглядел хранящимся на сайте клиента, включить ведение лога и определить максимальный размер платы, которую владелец дистрибутива готов оплатить, если вдруг интерес к его информации окажется непредсказуемо большим.
Например, если исходный файл в хранилище S3 был доступен по прямым ссылкам
https://s3-eu-west-1.amazonaws.com/pcweek-test/testcat/kote.jpg
или
https://pcweek-test.s3.amazonaws.com/testcat/kote.jpg
то после превращения “ведра” pcweek-test в дистрибутив к нему можно будет обратиться так:
http://d2zt66o4ofua6q.cloudfront.net/testcat/kote.jpg
Фактически изменился только домен “ведра”, а адресация файлов и каталогов внутри него сохранилась без изменений.
На практике пользоваться сервисом CloudFront имеет смысл, когда трафик прикладного проекта достигает терабайтных значений, иначе вполне достаточно скорострельности S3 по умолчанию. Если месячный исходящий из Cloud Front трафик не превысит 10 Тб, потребуется заплатить примерно 0,2 долл./Гбайт, при больших объёмах стоимость снижается в разы. Если организуется HTTP-доступ, то каждые 10 тыс. запросов обойдутся в 0,1 долл.
Грузим данные “винчестерами”
В некоторых случаях исходные объёмы данных, подлежащих размещению в облаке Amazon, столь велики, что загрузка их в “вёдра” S3 даже по широкополосной линии займёт очень много времени. Пока что самый быстрый способ доставки сотен терабайтов информации до пользователя, как известно, — это перевоз на физических носителях, курьером на автомобиле или самолётом. Для подобных нужд Amazon предлагает сервис AWS Import/Export, когда данные можно выгружать в S3 или скачивать обратно по внутренней сети Amazon, подключая к ней свои накопители. С территории России ближайшими ЦОДами, куда можно отправить физическое устройство хранения, будут ирландский и сингапурский. К “винчестеру” предъявляются такие условия: поддерживать интерфейсы SATA или USB, общая масса не должна превышать 22,5 кг, а ёмкость — быть в пределах 16 Тб.
Технология AWS Import/Export подразумевает создание уникального идентификатора задачи загрузки-выгрузки, который размещается в корне логического диска на передаваемом устройстве. Для формирования этого идентификатора с сайта AWS выгружается набор Java-утилит, вручную готовится описание задачи в виде текстового файла, задаётся уникальный пользовательский идентификатор. Утилиты отправляют запрос сервису Amazon, а получив ответ, создают файл-дескриптор, который надо разместить на жёстком диске перед отправкой.
Одно из полезных применений AWS Import/Export — это получение архивов из сервиса Glacier, который в онлайновом режиме будет отвечать на запрос несколько часов, а стоимость доступа к терабайтным наборам данных может быть весьма высокой. В таком случае полезно предварительно прикинуть возможные финансовые расходы: за выгрузку архивов с одного жёсткого диска с помощью AWS Import/Export возьмут 80 долл. и дополнительно 2,49 долл. за каждый час считывания данных (то есть за 61 мин спишется 5 долл.).
Развёртываем гибридную облачную инфраструктуру за один час
Ещё одна технология, оптимизирующая взаимодействие корпоративной ИТ-инфраструктуры с облаками Amazon, — это AWS Storage Gateway. Она реализует гибридную облачную модель: данные могут частично храниться в облаке S3 или Glacier в зашифрованном виде, и на локальных устройствах хранения клиента, при этом обеспечиваются различные режимы синхронизации содержимого по защищённым (SSL) линиям связи.
Amazon предлагает три схемы использования Storage Gateway.
- Кэширование в облаке (Gateway-Cached). Основные объёмы данных (до 32 Тб на логический том) хранятся в облаке, а локально держится та информация, к которой обращаются особенно часто. При этом можно одновременно минимизировать расходы на хранение больших данных за счёт их размещения в облаке и обеспечить низкое время задержки при обращении к локальным ключевым сведениям, а в периоды пиковых нагрузок быстро масштабировать ИТ-инфраструктуру.
- Хранение в облаке (Gateway-Stored; до 1 Тб на логический том). Если требуется высокая скорость обращения ко всему массиву информации, он может полностью храниться локально, а Storage Gateway будет использоваться для асинхронного создания резервных копий и образов данных.
- Хранение на виртуальных ленточных накопителях (до 150 Тб на библиотеку из 1500 условных лент). Эта оригинальная схема предлагает доступ по протоколу iSCSI к виртуальным лентам, которые идеологически отличаются медленным временем доступа, т. е. не подходят для хранения оперативной информации, однако за счёт дешевизны представляются идеальным решением при организации бэкапов.
Первые две схемы обойдутся примерно в 0,1 долл. на хранимый гигабайт в месяц, а вот хранение на “лентах” стоит на порядок дешевле. Правда, при восстановлении данных придётся раскошелиться на 0,3 долл./Гб, а также потребуется оплачивать исходящий из облака трафик — 0,1 долл./Гб.
Для организации гибридной схемы в клиентской сети потребуется установить виртуальную машину AWS Storage Gateway, которая исполняется под управлением гипервизора VMware ESXi или Microsoft Hyper-V. Далее выполняется настройка первой или второй схем и размещение пользовательских данных в облаке путём привязки IP-адреса виртуальной машины к Amazon AWS. Далее создаются логические тома и стыкуются по протоколу iSCSI с корпоративными серверами приложений, а в случае с лентами виртуальные устройства монтируются в гибридную систему типовым образом.
Несомненное удобство подхода AWS Storage Gateway — простота. Реорганизации действующей ИТ-инфраструктуры под гибридную модель не требуется, так как Amazon поддерживает стандартные протоколы взаимодействия с системами хранения данных.