Эффективная работа современных ИТ-систем немыслима без использования систем виртуализации данных. Они обеспечивают необходимую гибкость и простоту доступа к информации, позволяя компаниям совершать дальнейшие маневры, связанные, например, с переносом данных в другие хранилища, вводом новых системных ресурсов, контролем QoS и пр.
Соответственно важно выстроить эффективную систему виртуализации, правильно выделить нужные принципы для создания подходящей архитектуры размещения данных, обеспечить надлежащую координацию всех работ с гарантией качества предоставляемой информации и отсутствия рисков потери управляемости при работе с данными.
Требования, которые предъявляются сегодня к системам виртуализации данных, очевидны: предоставить доступ к данным, которые могут быть размещены в различных местах ЦОДа, не вводя при этом дополнительных ограничений. В идеале должны отсутствовать любые дополнительные условия, которые требуют понимания применяемой технологии доступа. Это должно распространяться как на пользователей, так и на настройку приложений. Добиться такого результата, несмотря на его очевидность, не так просто, как кажется.
Опрошенные порталом TechTarget эксперты высказали свое мнение о том, какие технические и нетехнических причины оказывают влияние на успешное развертывание системы виртуализации данных на предприятии, и рассказали, как следует правильно размещать виртуализованные данные в ЦОДе.
Необходимо создать абстрактную модель данных
«Чтобы работать с виртуализованными хранилищами, не задумываясь об особенностях размещения в них данных и технологии доступа, следует предусмотреть создание отдельного технологического уровня в архитектуре, который будет выступать промежуточным звеном между информацией и пользователями», — считает Ави Перес, технический директор компании Pyramid Analytics, занимающейся разработкой приложений для анализа данных.
Когда речь идет о работе с аналитическими системами, обычно такой инструмент для создания абстрактного представления данных уже входит в состав программного пакета. Это позволяет заказчикам работать с данными без написания собственных запросов. Пользователям нет необходимости понимать особенности технологии доступа, они применяют схематическую модель, которая в значительной степени скрывает реальную структуру хранения данных.
Благодаря созданию нового слоя, где данные представлены в абстрактном виде, пользователи получают возможность конструировать собственные виртуальные схемы хранения. Их можно применять в различных аналитических системах, получая согласованный доступ к данным, которые могут быть размещены в хранилищах различного типа.
Когда создается система виртуализации, то следует заранее предусмотреть, какой именно инструмент можно рекомендовать для использования в этом случае. Он должен быть достаточно гибким в применении и обеспечивать доступ к самым различным данным и технологиям.
Необходим каталог с актуальными данными
«Качественного применения виртуализованных данных удается достичь только после надлежащего „приземления“ информации со всех ресурсов хранения предприятия», — рассказывает Саптарши Сенгупта, директор по продуктовому маркетингу компании Denodo, предлагающей собственную систему виртуализации. Он считает, что недостаточно просто предоставить каталог информационных ресурсов, необходимо проработать с учетом пожеланий пользователей все правила, касающиеся подготовки и применения данных.
Чтобы работать с данными было удобно в подразделениях, необходимо провести классификацию используемой информации, осуществить ее разметку, обеспечить контроль над источниками ввода, предоставить подробное описание. Не будет лишним проработать возможность поиска по ключевым словам и другие способы выявления необходимых данных.
Реализация может потребовать создания специального словаря. Он поможет разметить имеющуюся информацию и предоставить ее пользователям в привычном виде.
Моделью хранения данных нужно управлять
Центральным элементом любой архитектуры виртуализации данных будет ее модель, или схема хранения. Она играет важную роль для решения различных задач, например, связанных с выборкой для аналитических расчетов.
«Для успеха проекта виртуализации важно не просто существование схемы хранения данных, а также то, как будет осуществляться управление элементами этой модели, как будет проводиться кодификация данных», — уверен Перес. Создаваемая процедура работ должна охватывать как точки поступления информации (входы), так и места ее раздачи (выходы). Другими словами, сфера влияния этого механизма должна охватывать как входящий контроль при получении данных и их распределении по стеку, так и места, где используется накопленная информация: аналитические отчеты, результаты расчетов, записи для машинного обучения.
Создаваемая схема данных и ее элементы должны быть под полным контролем. Необходимо предоставить документацию, провести тщательные исследования безопасности сохраняемых данных, отслеживать версионность применяемых в схеме определений.
Перес также советует ввести т. н. сертифицированную цифровую маркировку (watermarking) для создаваемого механизма. Она поможет судить о его качестве.
Предоставить документацию на метаданные
Крис Лахири, соучредитель компании Egnyte, занимающейся разработкой безопасной платформы для совместной работы с данными, считает, что наиболее значимым элементом для создаваемой системы виртуализации являются ее метаданные. Это — тот уровень, где собираются данные, полученные из различных мест их размещения, и осуществляется привязка к смысловым конструкциям.
Используемый механизм работы с метаданными должен динамически отслеживать все происходящие изменения, которые возникают на уровне разметки данных, и проводить их синхронизацию. Разработчикам важно предложить такую виртуальную форму, которая станет единой схемой для работы инструментов аналитики и позволит скрыть изменения, происходящие на уровне источников данных. Какой применять доступ к исходной информации, зависит от реализации приложений. В одних случаях подойдет прямой доступ, в других — пользователям придется работать со копиями оригинальных данных (снапшотами).
Аарон Розенбаум, директор по развитию компании MarkLogic, отмечает, что очень часто при разработке подобных систем отсутствует документация с описанием конкретных полей и программного кода, используемых для работы с массивами данных. Для многократного использования данных в разных приложениях это недопустимо. Необходима подробная документация, которая будет постоянно обновляться и предоставлять актуальные описания данных.
В этой документации должна содержаться информация обо всех значимых элементах используемой архитектуры, включая схемы разметки данных, а также должна быть описана применяемая терминология, или глоссарий. Необходимо задокументировать также правила сопровождения данных и контроля безопасности.
В настоящее время подготовка документации при построении хранилища данных и создании системы метаданных часто ведется раздельно. По мнению Розенбаума, объединение этих направлений позволит снизить риски появления ошибок при использовании данных.
Не забывать о безопасности и контролировать распространение данных
При разработке виртуализованного хранилища непременно возникают вопросы, связанные с защитой распространения данных и разработкой правил соблюдения этих требований. «Создаваемая система должна отвечать не только этим правилам, но и требованиям контролирующих органов. Необходимо также вести учет мест, откуда поступают данные и где они используются», — разъясняет Розенбаум.
Проблемы начинаются, когда данные применяются в многочисленных прикладных системах. В этом случае контроль за исходной информацией может быть ограниченным на уровне системы хранения, и следует вводить контроль за доступом к данным на уровне системы виртуализации.
Это затрагивает не только техническую сторону работы системы виртуализации. «Все пользователи, коллективные или индивидуальные, должны быть уверены, что запрашиваемая ими информация защищена», — отмечает Розенбаум. Когда система обеспечивает автоматическую защиту при прямом обращении к данным, то упрощается контроль на уровне прикладных систем и снижаются риски. Это выгодно отличает их на фоне решений с «хитроумными» настройками защиты, которые вводятся для каждого канала доступа к данным.
Нужны четкие правила по работе с данными
Выполняя проекты модернизации на предприятиях, можно нередко услышать: «Получить данные из давно работающих систем крайне непросто». По существу это означает, что технически у компании нет возможности предоставлять уже используемые данные в новые системы, отмечает Розенбаум.
Чтобы снять ограничения, необходимо в первую очередь устранить организационные барьеры. Для этого нужны четкие административные правила, действующие в компании в отношении управления данными. Это избавит небольшие подразделения от насаждения собственной политики «на каждый случай».
Открытость в отношении работы с данными порождает доверие между отдельными группами пользователей. Появление контроля за распространением данных помогает быстрей решать возникающие организационные вопросы и способствует росту эффективности при совместном использовании данных.
Важно следить за достоверностью данных
Одно из самых важных требований к любому информационному каналу — это гарантия достоверности предоставляемых данных. Прежде всего это касается контроля обновлений, что позволяет предоставлять по запросу только последние, актуальные данные. На это обращает внимание Сенгупта: «При разработке системы виртуализации необходимо предусмотреть механизм контроля, который способен гибко исправлять на лету передаваемые данные».
Такой механизм должен гарантировать достоверность данных при любых обращениях. Для реализации этого требования необходимо ввести отдельное поле для всех запрашиваемых данных. Механизм валидации будет делать в нем отметку, отмечая определенный столбец или ячейку таблицы, где появились данные, потерявшие актуальность. В системе могут также вводиться специальные функции, которые позволят вносить изменения на этапе передачи данных пользователю.
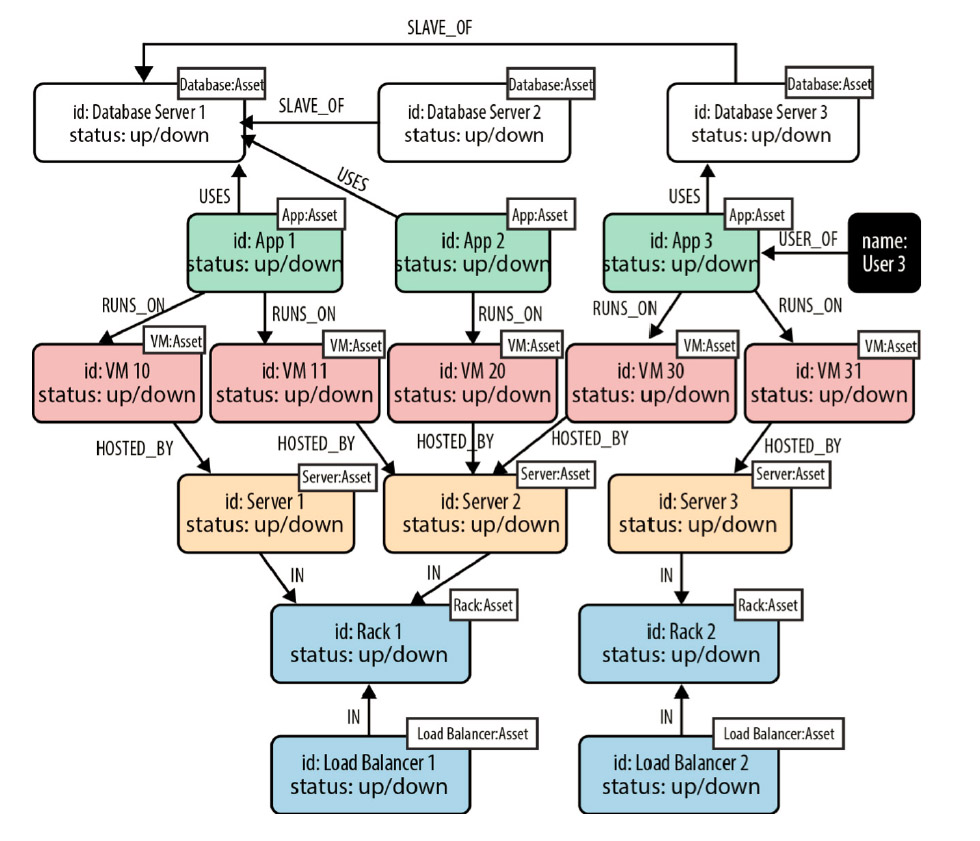
Графовый подход помогает решить множество проблем
Кейси Филлипс, директор по ИТ консалтинговой фирмы StrategyWise, обращает внимание на полезность использования графовых баз данных при осуществлении проектов виртуализации данных.
Существенным отличием графовых баз от реляционных является то, что в качестве основных сохраняемых сущностей они используют не только саму информацию, но и различные дополнительные атрибуты к ней. К их числу относятся например, теги, метки, характеристики связей между элементами или группами данных.
Графовые базы данных изначально были ориентированы прежде всего на работу со связями между объектами — в этом их главное отличие. Поскольку они выстраивают данные с учетом различных характеристик связей, то благодаря широкому распространению машинного обучения и искусственного интеллекта теперь эти технологии все чаще применяют для получения прогнозов. Они позволяют проводить анализ для неструктурированных данных, в том числе над информацией, которая хранится в виртуализованном виде.
Филлипс предлагает установить поверх традиционных разрозненных источников данных классическую графовую СУБД. Она будет собирать данные о востребованности сохраненных массивов и позволит делать гипотезы относительно оптимального выбора места для размещения данных. Если соотносить полученный прогноз с имеющейся конфигурацией ИТ-инфраструктуры, то можно оптимизировать выбор мест для хранения данных.
«Если заказчик заинтересовался развертыванием графовой базы данных, мы предлагаем ему для начала выделить используемые им прикладные системы и все, что к ним относится. В результате можно получить правила, в рамках которых осуществляется управление данными в компании и ведется их обслуживание», — рассказывает Филлипс. По его мнению, такие правила и стандарты необходимо сформулировать в ходе реализации любого проекта. Они будут распространяться на различные операции: клиринг данных или их идентификация, например. «Не имея таких правил, крайне сложно доводить проекты по виртуализации данных до успешного финала», — считает он.