













Хотя технологии NoSQL особо важны в бизнесе интернет-масштаба, продукты и сервисы с брендом NoSQL достойны внимания организаций всех размеров
В последние годы появился большой интерес к СУБД с собирательным наименованием NoSQL. Их много и сильно хвалят за то, что они позволяют компаниям, осуществляющим свою деятельность через Интернет и обслуживающим широкий круг людей, справляться с быстро растущими запросами пользователей и впитывать гигантские объемы создаваемых данных.
Понятно, что внедрение NoSQL принесло существенные дивиденды всевозможным Твиттерам и Нетфликсам. Сложнее, однако, оценить в какой мере этот тренд заслуживает внимания основной массы организаций, учитывая, что реляционные базы данных знакомы, привычны и занимают прочное место в ИТ, а для их масштабирования существует немало общепризнанных решений.
Хотя технологии NoSQL особо выигрышны для предприятий интернет-масштаба, продукты и сервисы, созданные под брендом NoSQL, вполне достойны внимания организаций всех размеров — не в смысле всеобъемлющей замены реляционных баз данных, а как дополнительные инструменты, работающие на бизнес.
Под NoSQL понимают широкий класс СУБД-продуктов, которые по возможности не обращаются к SQL-интерфейсам. Отличием этих продуктов от традиционных СУБД является стремление реже прибегать к SQL и чаще использовать отступления от реляционных моделей.
В базах данных NoSQL нет фиксированных схем, и это выгодно в плане разработки приложений с изменяющимися требованиями. Для таких продуктов нереляционность — более подходящий инструмент, хотя она и сужает возможности ссылочных связей.
Один из канонических документов, описывающих идеи проектирования и логику нереляционных баз данных, – опубликованная в 2007 г. статья Amazon.com о ее хранилище данных Dynamo, разработанном компанией для решения внутренних задач сервисного уровня.
В статье описывается, почему традиционные реляционные СУБД с их упором на приоритет согласованности данных над доступностью операций записи оказываются непригодными для потребностей розничной интернет-торговли в контексте инфраструктуры Amazon, включающей множество товарных серверов. Для Amazon было бы крайне накладно блокировать возможность покупателей добавлять новые позиции в свою корзину в ожидании синхронизации всех узлов, используемых приложением. Поэтому Dynamo было спроектировано с прицелом на повышение доступности за счет снижения приоритета согласованности.
Хотя масштабы инфраструктуры и пользовательской базы Amazon сравнительно уникальны (как и возможности этой компании по развертыванию собственного решения хранилища данных), потребность в расстановке приоритетов одних характеристик приложения над другими существует у любой организации. Современные нереляционные СУБД-продукты в этом смысле расширяют возможности компаний, не требуя создания решений с чистого листа.
Что скрывается за NoSQL
К категории NoSQL относятся несколько типов нереляционных СУБД. Сюда входят хранилища “ключ – значение”, документно-ориентированные СУБД, поколоночные СУБД и СУБД, работающие с графами. Все они имеют свои модели данных, стратегии масштабирования и сценарии применения.
Отнести какую-либо NoSQL-СУБД к конкретной категории не всегда просто, так как некоторые категории зачастую взаимно пересекаются. Чтобы разобраться в основных типах NoSQL-хранилищ данных, по моему мнению, полезно прочитать статью Рика Кэттела (tinyurl.com/3gh98mw). В ней бывший архитектор баз данных Sun Microsystems подразделяет обсуждаемый предмет на хранилища ключ – значение, документные хранилища и хранилища наращиваемых записей.
В хранилище ключ – значение отдельные записи представляют собой произвольные куски информации, проиндексированные ключом. Эти системы обычно не интерпретируют данные, предоставляя эту функцию приложению. Популярными примерами таких хранилищ являются Riak (поддерживается компанией Basho Technologies) и Oracle Berkeley DB.
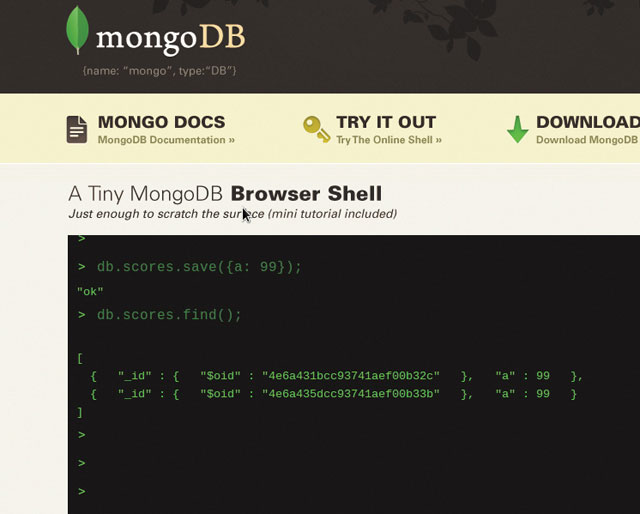
В документных хранилищах записи содержат “документы”, состоящие из переменного числа именованных атрибутов разных типов, таких как целые числа, символьные строки и вложенные объекты. Документо-ориентированные СУБД стремятся распознавать структуру хранимых данных и имеют более развитую функциональность запросов, чем хранилища ключ – значение. Примерами популярных документных хранилищ являются MongoDB компании 10gen и Apache CouchDB (поддерживается Couchbase).
Хранилища наращиваемых записей, также называемые широко-колоночными хранилищами, имеют модель данных, похожую на реляционные СУБД, но с организацией данных в столбцы (вместо строк) и семейства столбцов (вместо таблиц). Apache Cassandra (поддерживается компанией DataStax) и Apache HBase (поддерживается Cloudera) — примеры популярных хранилищ наращиваемых записей.
Для пользователя не столь важно, к какому виду правильнее отнести ту или иную нереляционную СУБД, главное для него –конкретный набор предлагаемых функций. В частности, следует обратить внимание на рычаги управления балансом доступности, согласованности и отказоустойчивости системы, на средства масштабирования и на интерфейсы, обеспечивающие доступ к данным.
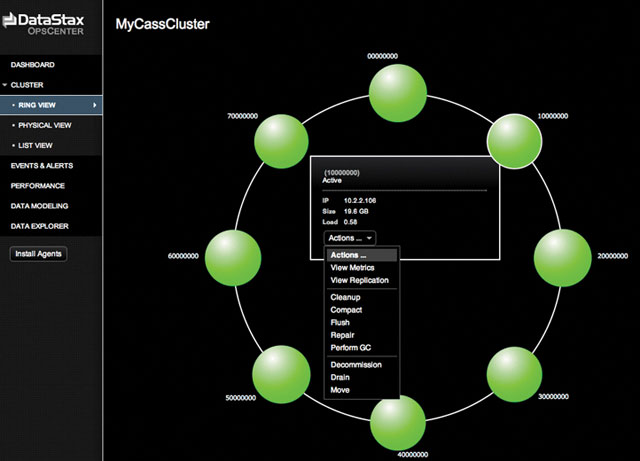
Например, Apache Cassandra позволяет администраторам регулировать желательные компромиссы между доступностью и согласованностью, исходя из характера запросов. Чтобы максимизировать согласованность, администратор может сконфигурировать кластер Cassandra так, чтобы задерживать сообщения о завершении записи или ответы на запросы чтения, пока не отреагируют все узлы кластера.
Чтобы максимизировать доступность, система может завершить операцию, когда хотя бы один узел завершит запись или отреагирует на запрос чтения. В распоряжении администратора также есть ряд других градаций для обеспечения баланса и устойчивости системы к отказам отдельных узлов.
MongoDB предусматривает масштабирование между узлами кластера посредством авторазделения. Если набор данных становится слишком велик для одной единицы аппаратуры, MongoDB может укрупнить коллекцию и распределить ее между заранее выделенными узлами, параллельно распределив ее дубль для восстановления при отказе узла.
Основные сложности
К числу главных проблем, которые могут возникнуть у администраторов, осваивающих возможности NoSQL, относятся различия в доступе к данным, хранимым в этих системах. Из-за сильных различий между этими СУБД-продуктами здесь нет прямого эквивалента SQL реляционного мира. И большинство нереляционных СУБД обеспечивает связи для доступа к данным посредством многих языков программирования.
Для высокоуровневого доступа к данным придуман ряд SQL-образных языков запросов. К ним относится GQL компании Google для ее AppEngine PaaS (платформа как сервис), язык Mongo Query Language для MongoDB, Cassandra Query Language и еще разрабатываемый UnQL (Unstructured Query Language). Для систем на базе Apache Hadoop существует два независимых способа высокоуровневой работы с данными — Apache Pig и Apache Hive.













