













В условиях шумихи, доходящей порой до крайности, мы решили посмотреть, как в действительности предприятия используют большие данные (Big Data), и оценить общую степень зрелости самого нового направления.
Определение больших данных, хотя это, безусловно, один из самых модных новых терминов в области технологии, как правило, будет зависеть от того, кого вы спросите. Тем не менее ясно, что большие данные, важное новое направление нашего подхода к хранению и обработке информации, продолжают привлекать пристальное внимание, будучи главной тенденцией в развитии ИТ первой половины текущего десятилетия. Конечно, оценки рынка весьма оптимистичны. Deloitte недавно определила объем рынка в нынешнем году в 1,3—1,5 млрд. долл. А IDC прогнозирует, что к 2015 г. отрасль затратит 16,9 млрд. долл.
За этими огромными цифрами скрываются фундаментальные изменения, которые происходят под влиянием больших данных.
Первое из них — акцент на данные, который воплощается в попытках отбирать и обрабатывать сведения (с помощью поиска лучших сырых данных), а затем делать выводы на основе выявленных закономерностей (доморощенные средства бизнес-интеллекта), вместо того чтобы пытаться найти данные, подтверждающие правильность уже принятых стратегических решений.
Один из наиболее известных примеров акцента на данные — знаменитая история с Moneyball, изложенная в 2003 г. в книге Майкла Льюиса. Там рассказывается, как бейсбольная команда Oakland A нарушила традицию и стала использовать анализ многочисленных данных для выявления своих наиболее результативных игроков, добившись в результате значительного успеха. Хотя речь шла об использовании больших данных только с одной целью, эта история, как и множество других, подводит к мысли, что акцент на данные позволит решить многие давно известные проблемы борьбы с самыми разными недугами, от преступности и заболеваний до загрязнения окружающей среды и бедности. Возможно, это также станет ключом к решению несколько более приземленных проблем в наших компаниях.
Другое крупное изменение состоит в оттеснении на второй план — впервые на протяжении жизни более чем одного поколения — реляционной модели данных, которая занимала лидирующие позиции в области обработки информации. Конечно, перевод обращенной к клиенту технологии на такие платформы, как СУБД в стиле Hadoop и NoSQL, пока наиболее часто встречается в начинающих интернет-компаниях и в области потребительских услуг. Однако пета- и экзабайты данных во многих видах бизнеса требуют практического применения технологий, которые хорошо масштабируются в условиях неуменьшающихся наборов данных и временных шкал, нередко растущих по экспоненте.
По различным причинам, которые пришлось бы слишком долго перечислять, реляционная модель в конце концов начала сталкиваться и с серьезными покушениями на свою гегемонию, и с реальными проблемами, которые часто лучше решаются иными способами. И хотя многие организации будут по-прежнему использовать реляционную технологию при создании решений для больших данных, это давно уже не единственный вариант. Особенно в связи с тем, что сейчас объемы неструктурированных данных растут гораздо быстрее традиционных структурированных.
Третье изменение заключается в том, что большие данные начинают гораздо чаще использоваться в организациях и обращенных вовне продуктах. Если для извлечения из них максимальной пользы нередко требуются специалисты по данным (data scientists), то в результате получаются приложения или устройства для работы с данными, которыми может пользоваться практически каждый. Google обеспечила фактически любому человеку возможность составить из нескольких ключевых слов запрос ко всему содержанию Интернета. Так и следующее поколение корпоративных систем для работы с большими данными, вероятно, сможет подключать работников к данным своих организаций, как правило, без помощи ИТ-кудесников. Рядовые сотрудники должны быстро получать доступ к большим данным. Только в этом случае большие данные будут оказывать устойчивое и серьезное влияние на бизнес.
Освоение больших данных на предприятиях
Давайте посмотрим, что в действительности говорят сегодня организации, когда речь идет о реализации систем для работы с большими данными и их использовании. В этом году компания O'Reilly опубликовала результаты опроса участников очередной онлайновой конференции Strata Conference, содержащие полезные сведения об использовании участниками мероприятия больших данных:
- 18% уже имели решение для больших данных;
- 28% не имели в момент опроса таких планов;
- 22% планировали создать такое решение в течение 6 месяцев;
- 17% планировали создать такое решение в течение года;
- 15% планировали создать такое решение в течение двух лет.
Как известно, участники данной конференции в большей степени, чем среднестатистические ИТ-специалисты, готовы к работе с большими данными, так что эти цифры являются чрезмерно оптимистичными, тем более учитывая, что под зонтиком больших данных скрывается множество технологий для обработки и анализа значительных объемов данных.
Однако картина становится еще интереснее, если посмотреть на конкретные отрасли. Например, недавно сообщалось, что 15—20% страховщиков активно готовятся к использованию решений для больших данных. Правительство, которое, по данным полезного отчета компании McKinsey, по этому вопросу получит значительные выгоды от использования больших данных, медленно осваивает новую технологию. Недавний опрос работающих в государственном секторе CIO и ИТ-менеджеров показал, что потребуется три года, чтобы приступить к обработке больших данных. Если мы посмотрим не на отраслевой, а на функциональный срез, то увидим, что к революционным преобразованиям с помощью больших данных готовы в торговле. Недавний анализ компании CSO Insights показывает, что, согласно ожиданиям 71% компаний, большие данные окажут значительное влияние на продажи, хотя сейчас это имеет место лишь в 16% компаний. Совершенно очевидно желание сократить данный разрыв.
Тем не менее в большинстве компаний многочисленные перемены, которые принесут большие данные, явно будут происходить постепенно, хотя и в широких масштабах. Необходимо разработать технологию и процесс, создать инфраструктуру и систему управления, а также привлечь специалистов по данным, разбирающихся в вашем бизнесе (или готовых его изучить). А еще потребуются доступные пока лишь немногим концепции вроде DevOps, которые связывают использование и разработку и позволяют быстро решать проблемы бизнеса с помощью анализа с акцентом на данные в сочетании с ограниченными по срокам исследованиями и развертыванием.
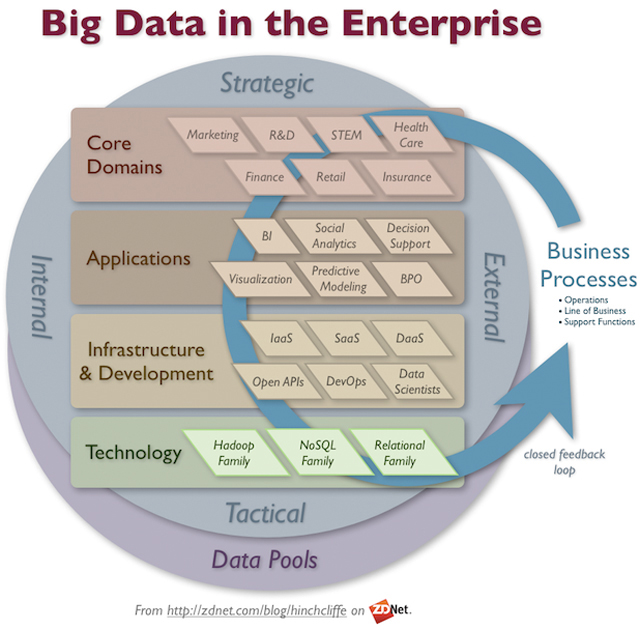
Кроме того, придется создать набор всего необходимого для больших данных. В данный набор непременно войдут компоненты, созданные на базе ПО с открытым исходным кодом, коммерческих приложений, облачной и собственной инфраструктуры, а также данные практических из любых источников. На иллюстрации изображен такой обобщенный набор.
Структура корпоративной системы для работы с большими данными
- Технология. В общем случае она состоит из трех главных семейств, два из которых являются новыми, а одно унаследованным: Hadoop и его варианты, семейство NoSQL и реляционные СУБД, дополненные функциями для обработки больших данных.
- Инфраструктура и разработка. Сюда относятся “инфраструктура как сервис” (IaaS), “ПО как сервис” (SaaS), “данные как сервис” (DaaS), открытые API-интерфейсы, DevOps и специалисты по данным. Последние компонуют решения из перечисленных компонентов, которые заимствуют внутри компании и извне.
- Приложения для работы с большими данными. Этот список популярных приложений для больших данных включает бизнес-интеллект, социальную аналитику, поддержку принятия решений, виртуализации и моделирования, прогнозирование поведения, оптимизацию бизнес-процессов и многое другое.
- Адаптированные решения. Когда подготовлены технология, инфраструктура и приложения для больших данных, компании должны сосредоточить свои усилия на придании им отраслевой специфики. Основными отраслевыми и/или функциональными сферами применения больших данных (теми, кто может рассчитывать на максимальную выгоду от их использования) являются маркетинг, исследования и разработки, наука, техника, инжиниринг и математика, здравоохранение, финансовые услуги, розничная торговля и страхование.
- Бизнес-процессы с использованием больших данных. Чтобы решения для обработки больших данных приносили пользу, они должны быть включены в бизнес-процессы организации, включая текущие операции, основной бизнес и функции поддержки. В частности, максимальный экономический эффект дадут наиболее важные и широко используемые бизнес-процессы.
Подведем итог сказанному. Мы находимся в начальной стадии роста потока данных. Лучший тезис о больших данных принадлежит Бену Вертеру, который отметил недавно, что мы все еще пребываем “в доиндустриальной эпохе больших данных”. Большинство организаций их не применяют, но уже появились признаки того, что использующие их могут получить существенное конкурентное преимущество. Как я и предсказывал ранее в этом году, социальная аналитика станет областью особенно широкого применения больших данных и предоставит организациям возможность широкого выбора инструментов и производителей.
В конечном итоге основной проблемой станет интеграция больших данных в обновленные и пересмотренные бизнес-процессы. Таким образом, главным препятствием окажется необходимость перестройки, поскольку требования технологии превышают возможности большинства организаций. По этой причине работа с большими данными, вероятно, будет перенесена в облака, что позволит основной массе организаций ускорить ее освоение и даст дополнительный импульс миграции многих ИТ в облака. Что может оказаться совсем неплохо.













