













Следующее поколение хранилищ больших данных строится на основе транзакционных таблиц. Конечно, транзакции допускают новые сценарии использования, которые подчас требуют обновления, удаления и объединения строк данных. Но важно то, что ориентированная на транзакции архитектура позволяет реализовать расширенные функции, такие как материализованные представления, агрессивное кэширование данных и эффективная репликация между хранилищами данных. Эти функции имеют решающее значение для современной аналитики и бизнес-аналитики (BI).
Ранее такие продвинутые функции были доступны для традиционных хранилищ данных — дорогих и ограниченных проприетарными инструментами вендора, масштабируемых до ограниченных объемов данных, что вынуждало создавать изолированные «островки данных». Важной характеристикой экосистемы больших данных, напротив, был богатый набор инструментов с открытым исходным кодом для доступа к таблицам в большом общем озере данных. В хранилищах больших данных следующего поколения мы сохранили инновационный набор инструментов и добились успехов в оптимизации системы, чтобы эти хранилища общего типа могли также хорошо работать в медленном облачном хранилище, используя при этом предоставляемые нашим движком возможности кэширования.
Сценарий для транзакционных таблиц
Экосистема больших данных явно мигрирует к таблицам в качестве предпочтительной модели для хранения данных. Таблицы достаточно гибки для использования в пакетных и потоковых системах. Они могут моделировать традиционную реляционную таблицу, группу ключей и значений, как в Apache HBase, набор объектов в S3, файлы в каталоге или поток Apache Kafka. И они поддерживают достаточное количество метаданных, таких как схема, информация о формате хранения и статистика, чтобы повысить производительность, а инструменты могли бы реализовать расширенные функции.
Первоначально экосистема Hadoop поддерживала транзакционную вставку в таблицу новых партиций. Замена, добавление, обновление или удаление данных в партиции не были транзакционными и во избежание ошибок требовали координации действий пользователей. Обновление и удаление в одной строке требует перезаписи всей партиции или, как минимум, всего файла.
Сегодня пользователям нужна поддержка вставки, обновления, удаления и объединения строк данных, а не просто вставки или замены партиций. Медленно меняющаяся размерность, очень распространенный метод управления изменениями пользовательских данных с течением времени, требует обновлений. Удаление записей одного клиента в соответствии с правилами конфиденциальности требует уничтожения. Чтобы обеспечить непрерывную загрузку данных в хранилище в близком к реальному времени, необходимо поддерживать непрерывную вставку данных из потокового источника, такого как Apache Kafka. Для загрузки данных в хранилище с помощью небольших или микропартий из внешних систем нужно слияние. Все это требует транзакций. С их помощью можно гарантировать, что записи не конфликтуют и что читатели видят непротиворечивые данные независимо от происходящих во время их запросов изменений.
Поддержка транзакций также обеспечивает ряд расширенных функций благодаря своей модели согласованности. Последовательность — это прочная основа для быстрого, но безопасного движения. С транзакциями намного проще становится агрессивное, но корректное кэширование. Данные таблицы и даже метаданные можно кэшировать с повторным чтением, когда система транзакций отмечает, что таблица изменилась. Результаты запроса могут кэшироваться и пересчитываться, когда система транзакций указывает на изменение одной из базовых таблиц. Система транзакций также может отслеживать, когда обновляются материализованные представления. Это позволяет оптимизатору решать, что следует использовать материализованное представление, а не базовую таблицу. Как только материализованное представление определяется как устаревшее, алгоритм перестроения может использовать транзакции, чтобы определить, как перестроить материализованное представление с минимальной обработкой. Используя транзакции, система репликации может легко отслеживать, что изменилось в таблице и, следовательно, должно быть отправлена в целевую таблицу в новом инстансе.
Конечно, данные в этих таблицах транзакций должны быть защищены, и ими нужно управлять. Недостаточно контролировать доступ на уровне всей базы данных, таблицы или, что еще хуже, на уровне файлов, в которых хранятся данные таблицы. Разрешения доступа должны контролироваться и соблюдаться на уровне столбцов и строк. Сотрудники, отвечающие за соответствие нормативным требованиям, должны иметь возможность помечать данные как персональные (personally identifiable information, PII) и ограничивать доступ к этим таблицам, столбцам или строкам, предоставляя его только утвержденному персоналу. Это должно соблюдаться независимо от того, какой инструмент выбирает пользователь для доступа к данным.
Поддержка транзакционных таблиц в разных инструментах
Транзакции на уровне строк должны поддерживаться всеми инструментами. Ключевым аспектом экосистемы больших данных является возможность выбора пользователем лучшего инструмента для работы из набора инновационных технологий с открытым исходным кодом, а не единый, универсальный подход, подходящий для всех и не оставляющий выбора. А такая гибкость необходима, так как со временем появляются новые инструменты. Нужна возможность потоковой передачи записей в таблицу с помощью Spark и чтения этой таблицы с помощью Presto. Нужно иметь возможность обновить таблицу в Hive и запросить ее с помощью Impala, обеспечивая согласованность транзакций. Помимо работы с инструментами, нужна работа с системами хранения и с размещением таблиц в S3, GFS, ADLS и HDFS.
Что необходимо сделать для удовлетворения этих требований в экосистеме больших данных? Для поддержки взаимодействия транзакционных таблиц при работе с разными инструментами требуется три вещи: общее хранилище, общие метаданные и транзакции, а также общая безопасность и управление. Все они должны быть открытыми и использоваться всеми поддерживаемыми пользовательскими инструментами.
Даже при соблюдении этих трех требований обмен данными между инструментами сопряжен с проблемами. Ранее инструменты могли взаимодействовать с данными через файловые форматы. Но транзакции и повышенная безопасность требуют не только файловых форматов. Кроме того, не стоит ожидать, что любой инструмент поймет схему хранения данных другого инструмента. Различные инструменты могут хранить данные по-разному, даже если они используют один и тот же файловый формат. Некоторые инструменты могут не поддерживать все функции безопасности, необходимые для доступа к определенному набору данных. Чтобы обеспечить доступ через инструменты, нужны связки.
Cloudera создает три основы: общее хранилище, общие метаданные и транзакции, общую безопасность для таблиц хранилища данных, а также необходимые связки с открытым исходным кодом, чтобы пользователи могли применять при работе с этими таблицами выбранные ими инструменты.
Экосистема Hadoop уже давно поддерживает общее озеро данных, используя общее хранилище, будь то в облаке или на локальной площадке. Поскольку облачные системы хранения несколько отличаются от HDFS и работают значительно медленнее, мы оптимизировали наши таблицы хранилищ данных для объектных хранилищ.
Has metastore (HMS) де-факто является для экосистемы Hadoop репозиторием метаданных. Он поддерживается различными инструментами с открытым исходным кодом, включая Hive, Spark, Impala и Presto.
Транзакции требуют записи в журнал (Write Ahead Log, WAL). Когда мы пять лет назад начали работу над транзакциями Hive, стало ясно, что HMS является естественным местом для хранения WAL. HMS хранит свои данные в самой СУБД и, таким образом, является транзакционным. Он уже используется в разных инструментах. Кроме того, репозиторий метаданных уже доступен для каждого запроса, поэтому при планировании запроса издержки минимальны.
Эти транзакции ACID предназначены для работы в системах с однократной записью, таких как облачные объектные хранилища и HDFS, которые хранят данные таблиц и в больших распределенных вычислительных машинах без существенного влияния на производительность. Эта архитектура сводит конфликты к минимуму, максимально увеличивает число одновременно работающих читателей в разных инструментах и позволяет одновременно записывать сообщения, избегая конфликтов и блокировок. Изменения в данных хранятся таким образом, чтобы свести к минимуму накладные расходы для читателей, даже если одновременно существует несколько версий данных.
Для обеспечения безопасности и управления естественным выбором стали Apache Ranger и Apache Atlas, поскольку в экосистеме больших данных они обеспечивают наиболее совершенную защиту и управление. Они работают с различными инструментами и разными видами данных, будь то файлы, таблицы или потоки Kafka.
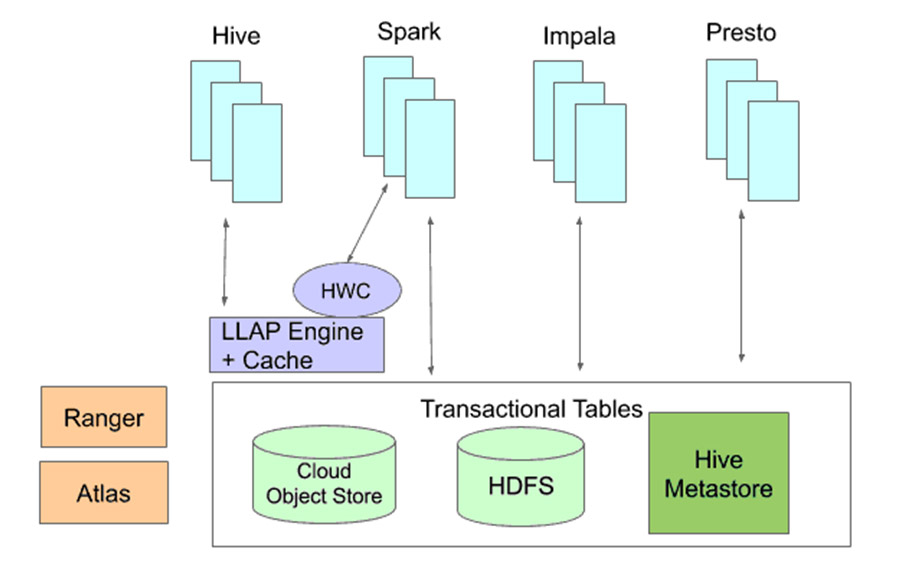
Создание связок для инструментов
При принятии решения о том, как подключить инструменты к существующим транзакционной основе и системе безопасности, нужно найти компромисс. Например, Qubole работает над реализацией прямого доступа к транзакционным таблицам для Spark. Это позволит пользователям Spark транзакционно вставлять, обновлять и удалять записи в своих таблицах. Однако поскольку Spark работает в контексте пользователя с произвольным кодом, непосредственно обращающимся к данным, более сложные параметры безопасности, доступные в Ranger и Atlas, такие как разрешения на уровне столбцов и строк и политики на основе тегов, реализовать нельзя. Для пользователей, которым нужны эти механизмы безопасности, мы создали Hive Warehouse Connector (HWC). Он позволяет пользователям Spark получать доступ к транзакционным таблицам через демоны LLAP. Это обеспечивает соблюдение политик безопасности и предоставляет пользователям Spark быстрый параллельный доступ для чтения и записи. Поскольку Impala уже интегрирована с Ranger и может применять политики безопасности, она напрямую интегрируется с транзакционными таблицами.
При взаимодействии между инструментами помимо возможности чтения и записи транзакционных таблиц возникают дополнительные вопросы. Один инструмент может выбрать реализацию конкретной функции одним способом, тогда как другой реализует эту функцию другим, несовместимым способом. Взять, к примеру, хеширование данных в сегменты. Spark использует хэш-функцию, отличную от последней версии Hive. Если прочитанные данные записаны другим, и предполагается, что данные упакованы в пакеты в соответствии с их собственной хэш-функцией, они будут возвращать неверные результаты. Тем не менее, репозиторий метаданных позволяет легко фиксировать, как данные были объединены в сегменты, и, чтобы избежать проблем, информировать читателей, когда схема группирования отличается от схемы читателя.
Для решения проблемы сегментирования и других подобных проблем мы добавили в HMS функциональность для поддержки трансляции метаданных между инструментами. Таким образом, в примере с группированием репозиторий метаданных будет отслеживать, какой механизм используется. Когда данные, упакованные в соответствии с алгоритмом Spark, читаются Hive, транслятор не будет изменять данные. Вместо этого он сообщит Hive, что читаемые Spark данные не сегментированы. Тем самым можно избежать того, что Hive станет рассматривать схему распределения Spark как свою собственную и даст неправильные результаты.
Конечно, все это делается в системах с открытым исходным кодом. В большинстве случаев это улучшает существующие проекты Apache. Там, где нужны новые компоненты, работы также ведутся в Open Source. Мы работаем с Qubole, чтобы предоставить Spark прямой доступ к транзакционным таблицам, и в ближайшее время планируем расширить его до Presto.
Авторы статьи — со-основатели Hortonworks, эксперты компании Cloudera.













