













Data Reliability Engineering — очень молодая концепция, и еще предстоит определить инструменты и методы, которые сделают DRE столь же эффективной, как SRE и DevOps, пишет на портале The New Stack Кайл Кирван, генеральный директор и соучредитель компании Bigeye.
Было время, когда ПО было довольно ненадежным. 20 лет назад один инженер-программист посетовал на то, что хорошее ПО «должно быть пригодно для использования, надежно, без дефектов, экономично и ремонтопригодно. А нынешнее ПО ничего из этого не обеспечивает». Прошло два десятилетия, и сегодня ПО лежит в основе бизнеса, начиная от обеспечения платежей и заканчивая CRM и включая все, что между ними.
По мере того, как данные превращаются из просто приятной вещи в то, на что полагаются компании для создания клиентского опыта и повышения доходов, они должны пройти аналогичную эволюцию — и здесь помогут уроки, которые можно извлечь из работы, уже проделанной пионерами программной инженерии.
Заимствуя принципы инженерии надежности систем (Site Reliability Engineering, SRE), DRE означает работу по улучшению качества данных, обеспечению своевременной передачи данных и предоставлению «здоровых» наборов исходных данных для аналитики и машинного обучения.
Эта работа выполняется инженерами по данным, специалистами по исследованию данных и аналитиками, которые исторически не имели в своем распоряжении развитых инструментов и процессов, которыми уже располагают современные команды разработчиков ПО и DevOps. Из-за этого работа по обеспечению надежности данных обычно включает в себя больше выборочную проверку данных, запуск поздней ночью резервного копирования и ручной мониторинг SQL в Grafana, чем масштабируемые и повторяемые процессы, такие как мониторинг и управление инцидентами.
Применяя подход DRE, некоторые команды по работе с данными начинают менять эту ситуацию, заимствуя опыт SRE и DevOps.
Почему сейчас?
Качество данных в целом было темой нескольких десятилетий, но в последние два года ему уделяется заметно больше внимания. Это обусловлено несколькими одновременно проявляющимися тенденциями.
1. Данные используются в приложениях со все более высоким уровнем воздействия. К ним можно отнести чатботы поддержки, рекомендации по продуктам, управление запасами, финансовое планирование и многое другое. Эти приложения, основанные на данных, обещают большой рост эффективности, но они также могут приводить к расходам для бизнеса в случае сбоя. По мере того, как компании стремятся к созданию все более и более окупаемых сценариев, данные становятся все более важными, что повышает требования к их качеству и надежности.
2. Люди все меньше вовлечены в процессы. Потоковые данные, модели МО, которые регулярно переобучаются по расписанию, приборные панели самообслуживания и другие приложения сокращают количество задействованных людей. Это означает, что конвейеры должны быть более надежными по умолчанию, поскольку аналитик или специалист по исследованию данных больше не проверяет данные — а этого и не должно быть, у них есть своя работа!
3. Инженеров по данным не хватает. Нанимать инженеров по данным сложно и дорого. Спрос на специалистов, способных создавать и масштабировать сложные платформы данных, растет, в то время как предложение за ним не успевает. Это оказывает огромное давление на эти команды, заставляя их быть эффективными с точки зрения ресурсов, избегать реактивного пожаротушения и применять все, что автоматизирует обнаружение и решение проблем, и особенно инструменты или практики, которые помогают предотвращать проблемы в первую очередь.
Где заканчивается DRE и начинается DataOps?
DRE является частью Data Operations (DataOps), но только частью. DataOps относится к более широкому набору всех операционных задач, с которыми сталкиваются владельцы платформ данных. Он охватывает такие задачи, как обнаружение и управление данными, отслеживание и управление затратами, контроль доступа, а также управление постоянно растущим количеством запросов, информационных панелей, функций и моделей MО.
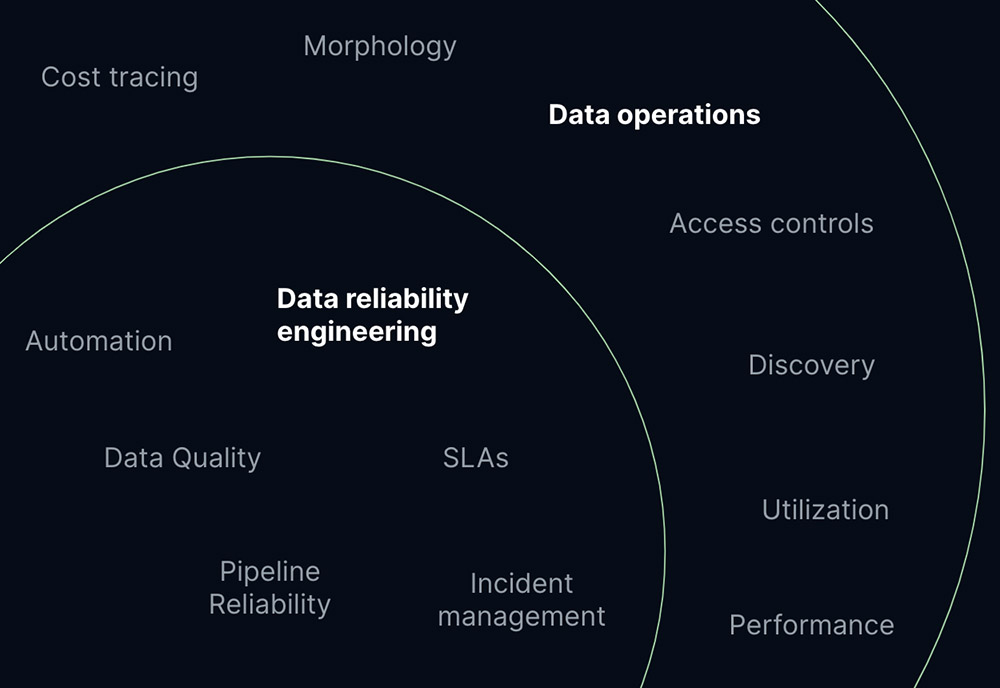
Если провести параллель с DevOps, то надежность и время безотказной работы, безусловно, являются показателями, за которые отвечают многие команды DevOps, но на них также часто возлагается ответственность за другие аспекты, такие как скорость работы разработчиков и соображения безопасности.
Инструменты и методы DRE
Чернила еще не высохли на лучших инструментах и практиках DRE, поэтому лучше ориентироваться на семь основных концепций из руководства Google SRE Handbook, которые создают прочную основу для работы дата-команд.
1. Примите риск. То, что что-то рано или поздно даст сбой, является неизбежным фактом. Команды должны планировать обнаружение, контроль и смягчение последствий сбоев, которые происходят, а не надеяться, что когда-нибудь они смогут достичь совершенства.
2. Отслеживайте все. Проблемы нельзя контролировать и смягчать, если их нельзя обнаружить. Мониторинг и оповещение дают командам необходимую видимость, чтобы понять, когда что-то идет не так и как это исправить. Инструментарий наблюдаемости является зрелой областью для инфраструктуры и приложений, но для данных он все еще находится в стадии становления.
3. Установите стандарты. Являются ли ваши данные высококачественными или нет? Это субъективный вопрос, который должен быть сформулирован, выражен количественно и согласован, чтобы команды могли добиться прогресса в его решении. Если определение хорошего или не очень качества размыто или не согласовано, будет трудно что-либо сделать. SLI, SLO и SLA — это инструменты установления стандартов, которые могут быть адаптированы из области SRE в область DRE.
4. Сократите трудозатраты. «Труд» — это слово, которое описывает человеческую работу, необходимую для эксплуатации вашей системы (операционную работу) в отличие от инженерной работы, которая улучшает систему. Пример: выдача задания Airflow vs. обновление схемы вручную. Для эффективности DRE стоит устранить как можно больше трудозатрат, чтобы снизить накладные расходы. Например, такие инструменты, как Fivetran, могут уменьшить трудозатраты на ввод данных, а тренинг-сессии Looker — уменьшить трудозатраты на ответы на BI-запросы.
5. Используйте автоматизацию. Сложность платформы данных растет экспоненциально, а управление ею вручную увеличивается линейно вместе с численностью персонала. Это дорого и неприемлемо. Автоматизация ручных процессов помогает командам по работе с данными повысить надежность, высвобождая умственные силы и время для решения проблем более высокого порядка.
6. Контролируйте релизы. Внесение изменений — это, в конечном счете, способ улучшения, но также и способ поломки. Этот урок команды по работе с данными могут напрямую позаимствовать из SRE и DevOps, код-ревью и конвейеров CI/CD. В конце концов, код на конвейере — это все равно код.
7. Поддерживайте простоту. Сложность — враг надежности. Сложность нельзя полностью устранить — в конце концов, конвейер что-то делает с данными, — но ее можно уменьшить. Минимизация и изоляция сложности в любой отдельной части конвейера в значительной степени способствует сохранению его надежности.













