













Едва ли не каждое печатное издание время от времени проводит опросы читателей и публикует сводные аналитические отчеты. Пишутся они легко и быстро. Строится полдюжины нехитрых таблиц Excel, да добавляется два-три бодрых вывода: смотрите, мы за год выросли, читатель наш поумнел и встал на ноги, а эффективность рекламы (ликуй, рекламодатель!) достигла прямо-таки сказочных высот. Жаль только, в памяти читателя это произведение удерживается аккурат до следующей страницы.
Такие размышления привели однажды группу аналитиков к решению использовать рутинную, в общем, задачу обработки читательских анкет в качестве полигона для "обкатки" новых интеллектуальных технологий, медленно, но верно прокладывающих путь на российский рынок. И вот, взяв наперевес десяток самых мощных и современных аналитических пакетов, бригада энтузиастов принялась за дело. Благо, повод был подходящим - приближался годовой юбилей еженедельника PC Week/RE, в связи с чем требовала осмысления гора пришедших в редакцию читательских анкет.
Умом Россию не понять
Первое же заключение патентованного западного пакета отправило участников эксперимента в глубокий нокдаун. Результаты кластерного анализа красноречиво свидетельствовали: основной контингент читателей респектабельного еженедельника составляют бомжи без компьютеров! Впрочем, это недоразумение разрешилось легко. Многие читатели не стали утруждать себя заполнением многочисленных полей анкеты, а педантичный американский пакет интерпретировал пробелы в полях "почтовый адрес" и "количество компьютеров" как отсутствие оных. Последующий анализ показал, что такой "забывчивостью" отличаются не только москвичи и петербуржцы, считающие родной город признанной столицей компьютерного мира. Уроженцы Оренбурга и Йошкар-Олы, большого Красноярска и маленьких Люберец показали себя подлинными жителями виртуальной реальности, указав в качестве почтового адреса только e-mail. И не раз еще в ходе эксперимента участникам приходилось брать на себя роль следователей, когда очередной западный алгоритм пасовал перед безграничным российским разгильдяйством (как вам, например, понравится фирма, обладающая, по утверждению автора анкеты, двумя тысячами локальных сетей?)
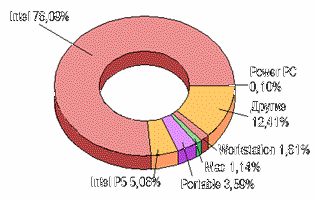
Распростанение аппаратных платформ среди читателей
Впрочем, первый этап - одномерный анализ по каждому из разделов анкеты и построение гистограмм - был пройден сравнительно легко. Выяснилось, что PC Week/RE читают жители 160 городов и областей России, а также восьми зарубежных государств (включая далекую Финляндию). Основной контингент читателей еженедельника сосредоточен помимо Москвы и Санкт-Петербурга в крупных индустриальных центрах - Нижнем Новгороде, Казани, Екатеринбурге, Новосибирске, Самаре, Тюмени, Набережных Челнах.
Подавляющее большинство читателей PC Week/RE - руководители предприятий или отделов, ответственные за информационные технологии и обработку данных. Около 26% респондентов руководят подразделениями, 11% имеют свой бизнес, 6% управляют финансовой деятельностью предприятий. Всего же в руководители различных рангов записалось 170% опрошенных (не удивляйтесь, просто многие руководят сразу несколькими направлениями).
Объектом администрирования чаще всего выступают корпоративные сети - 34%, информационные системы - 33%, разработка ПО - 32%, телекоммуникации - 23% и системное программирование - 19% (а сумма опять превышает 100%. Россия, Сэр!).
Основными направлениями деятельности читателей PC Week/RE являются непроизводственная сфера (24%), производство компьютерного оборудования и ПО (21%), коммуникации (17%), системная интеграция (16%). Приятно удивило развитие консалтинга, который еще год назад считался почти экзотикой. Консалтинг составляет предмет деятельности 7,5% опрошенных, почти догоняя сферу обслуживания (8%).
В государственном секторе занято 12% читателей, в производственной деятельности, не связанной с компьютерами, - 10%. Тяготение читателей PC Week/RE к компьютерному бизнесу выражено предельно четко. Так, среди тех, кто причисляет себя к дистрибьюторам, распространением компьютеров занято 13% от общего числа обработанных анкет.
Разумеется, подавляющее большинство читателей работают в локальных сетях (84%), более половины - в среде клиент - сервер. Любопытно распределение читательских пристрастий по используемым ОС. Бесспорно лидерство DOS и Windows - 89%, второе место у Windows NT - 20%, далее следуют OS/2 - 18% и UNIX - 16%. Поклонники Solaris составляют всего 3%.
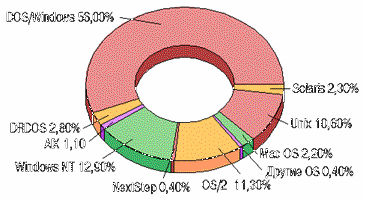
Распростанение программных платформ среди читателей
Итогом первого этапа анализа стал пухлый отчет, где добросовестно перечислялись приведенные выше результаты (и еще десяток второстепенных). Однако получение добротного отчета при помощи Excel (которым обычно анализ и ограничивается) в данном случае было лишь прелюдией к более серьезной и интересной работе.
"Мистер Читатель PC Week/RE"
Следующим этапом обработки анкет стал кластерный анализ. Дело в том, что итоговая диаграмма распределения какой-либо величины (например, возраста клиентов страховой компании) не отображает некоторой существенной информации. Если представить клиентов в виде точек на двухмерном поле, где по одной оси отложен возраст, а по другой, к примеру, заработок, то появится совершенно новое понимание ситуации. Вы увидите, что точки-клиенты рассыпаны по полю не равномерно, а образуют некоторое (обычно небольшое) множество четко выраженных групп-кластеров. Подробные сведения об этих группах - расположение, численность, размеры - поистине бесценны для компаний, поскольку позволяют составить типовые "портреты" клиентов. А это - залог эффективной рекламы, успешных целевых распродаж и грамотного стратегического планирования.
Существует несколько методов кластерного анализа, один из наиболее популярных основан на использовании самоорганизующегося классификатора Кохонена. Предложенный им в 1984 году алгоритм классификации базируется на использовании однослойной нейронной сети, на входы которой подаются вектора компонентов классифицируемых объектов, а выходы нейронов соответствуют различным классам. Подавая на вход сети вектор за вектором, мы ищем выходной нейрон с наибольшим значением функции возбуждения - он и показывает наиболее соответствующий данному объекту класс. Достоинством метода является самообучаемость (в отличие от других типов нейронных сетей, сеть Кохонена не требует построения целевых векторов), а также гарантированная сходимость - каждый объект будет обязательно причислен к тому или иному классу. Недостаток метода - сложность эффективной реализации параллельного алгоритма на обычном компьютере. Поэтому при работе с большими базами данных пользуются другими, более быстродействующими и мощными алгоритмами. Важность этой проблемы косвенно доказывает красная наклейка "Запрещен к экспорту из США", которая до сих пор украшает пакет RuleMaker фирмы HyperLogic, реализующий наиболее современные алгоритмы кластеризации (впрочем, пакет доступен на рынке Москвы).
Сеть Кохонена в ее классическом виде можно найти в программном комплексе AI Trilogy фирмы Ward Systems и нескольких других программах. А ее исходные тексты на языке Си включены в пакет OWL - своеобразное "собрание сочинений" по всем основным типам нейронных сетей.
Применение кластерного анализа к базе данных подписчиков PC Week/RE позволило разбить все множество читателей на несколько четко выраженных групп. Нас интересовала самая многочисленная, точнее - портрет ее наиболее типичного представителя. Каков он, "мистер читатель PC Week/RE?" Таких в итоге оказалось двое (поскольку два кластера явно выделялись своими размерами). Оба - жители городов, работают на платформе Intel, подключены к локальной сети и активно используют MS Windows (или Windows for Workgroups). Однако первый - компьютерный профессионал, работающий в небольшой (от 5 до 20 компьютеров) компании, а второй - руководитель или администратор в крупной фирме (20 - 100 компьютеров). На столе у первого - все богатство программного рынка, включая самые современные технологии (даже непонятно, откуда 730 читателей взяли CASE-пакеты - в России столько не продавалось!), второй же ограничивается MS Office, СУБД и бухгалтерскими программами. Первый активно использует электронную почту и средства мультимедиа, второй - текстовые редакторы и электронные таблицы. Компьютер первого мощнее, второго - престижнее (это непременно brand-name, иногда - портативный). Обоим по роду деятельности приходится заниматься информационными и коммуникационными задачами, оба надеются на некоторое (20 - 40%) увеличение компьютерного парка своей фирмы в следующем году. Оказавшись за одним столом, эта пара, вероятно, легко найдет общий язык, поскольку оба самых типичных читателя PC Week/RE принадлежат к зарождающемуся в России классу "белых воротничков" - квалифицированных работников и менеджеров.
Аудитория PC Week/RE как зеркало российского бизнеса
Проведя кластеризацию данных, вы можете проделать над ними более сложные операции, связанные с корреляционным анализом или анализом временных рядов. Обычно для владельца базы данных представляет интерес развитие некоторых ключевых показателей во времени, региональное распределение, а также наличие корреляции с некоторыми другими параметрами.
Высший пилотаж в такого рода анализе продемонстрировала недавно фирма Microsoft. Используя известный нейросетевой пакет Brain Maker для обработки базы данных о своих клиентах, она "ухватила" основные закономерности, выделяющие наиболее перспективных клиентов. Это позволило во многих случаях заменить предельно дорогой и неэффективный способ массового распространения рекламных материалов избирательной рассылкой, "целясь" в потенциальных клиентов. Эффект от рекламных кампаний вырос почти на 15%. Если помножить это на оборот компании, можно понять причины настоящего бума маркетинговых исследований, охватившего в последнее время средние и крупные фирмы США.
Кстати, несмотря на то что в области прикладного корреляционного анализа за последние годы было сделано очень много и счет программных пакетов пошел на десятки, традиционные алгоритмы до сих пор в строю. Поэтому вовсе не обязательно гнаться за модными пакетами - вполне подойдет, например, классический пакет Statistica фирмы StatSoft. Тем более, что недавно на рынке появилась новая, упрощенная версия этого популярного пакета - Quick Statistica.
А что дал корреляционный анализ базы данных PC Week/RE? Программа позволила "спроецировать" результаты анкетирования на данные из других источников - данные о деловой активности в регионах (источник - "Коммерсантъ Daily") и структуру потребительского рынка ПК (источник - IDC). Оказалось, что структура распространения еженедельника по стране, первоначально развивавшаяся стохастически и определяемая участием в региональных выставках, обнаруживает явное тяготение к наиболее "здоровым" с точки зрения финансовой и деловой ситуации регионам. Первая десятка экономически передовых регионов практически точно отображается диаграммой распределения читателей: Москва, Санкт-Петербург, Нижний Новгород, Екатеринбург и т. д. И это не случайно - компьютерный бизнес является зеркалом российского бизнеса в целом, а уж корпоративному еженедельнику сам бог велел быть "слепком" своего сектора рынка.
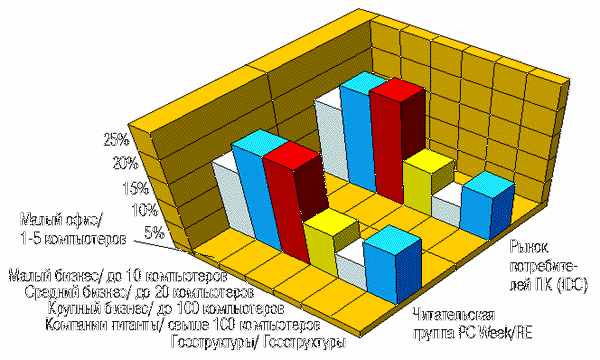
Сектор рынка ПК (IDC) / Читательская группа PC Week/RE
Второе приятное открытие - полнота охвата российского бизнеса. Каждое издание старается "бить по площадям", однако круг читателей, спроецированный на общую диаграмму бизнеса, обычно образует некоторое локальное "пятно". Одни издания находят отклик у молодежи и фанатов компьютерных игр, другие - у программистов-профессионалов, третьи - у крупных финансистов и бизнесменов и т. д. Как оказалось, PC Week/RE пришелся ко двору всем основным секторам бизнеса. Подтверждением этому может служить почти точное совмещение диаграммы потребительского рынка ПК по материалам IDC (май 1996 г.) и структуры читательской аудитории PC Week/RE.
Судите сами.
+-------------------+----------------------+---------------+-------------------+
| Сектор рынка ПК | Читательская группа |Доля на рынке | Доля среди |
| (IDC) | (PC Week/RE) | ПК (IDC), % | читателей (PC |
| | | | Week/RE), % |
+-------------------+----------------------+---------------+-------------------+
|Малый офис |1 - 5 компьютеров | 16 | 15 |
+-------------------+----------------------+---------------+-------------------+
|Малый бизнес |До 10 компьютеров | 21 | 21 |
+-------------------+----------------------+---------------+-------------------+
|Средний бизнес |До 20 компьютеров | 22 | 21 |
+-------------------+----------------------+---------------+-------------------+
|Крупный бизнес |До 100 компьютеров | 10 | 10 |
+-------------------+----------------------+---------------+-------------------+
|Компании-гиганты |Свыше 100 компьютеров | 5 | 6 |
+-------------------+----------------------+---------------+-------------------+
|Госструктуры |Госструктуры | 10 | 12 |
+-------------------+----------------------+---------------+-------------------+
Как сказали бы специалисты-социологи, читательская аудитория PC Week/RE представляет собой репрезентативную выборку компьютеризированного бизнеса России.
Итак, проведя все перечисленные шаги, удалось составить достаточно полное представление о контингенте читателей, их компьютерном парке и т. д. Однако главных результатов мы ожидали от применения "тяжелой артиллерии" - интеллектуальных пакетов, основанных на новейших методах автоматического извлечения знаний из больших баз данных. Методах, объединенных непривычным названием data mining.
Data mining - "раскопки данных"
Что такое - "data mining" (в приближенном переводе - "раскопки данных", "добыча данных")? Новые вершины знаний или переделка хорошо забытых старых методов? Почему так дороги пакеты, использующие data mining?
Термином data mining (альтернативное название - information discovery) принято называть комплекс методов, направленных на извлечение полезных знаний из баз данных большого объема и информационных потоков. Лежащий в основе data mining математический аппарат весьма сложен и многообразен: здесь и нейронные сети, и нечеткая логика, и новые алгоритмы корреляции, и специальные средства обработки исключений, и предельно мощные методы визуализации. К примеру, знакомый многим (и один из самых мощных в своем классе) статистический пакет SAS одноименной фирмы во внутрифирменной системе data mining и data warehousing (хранилище данных) является лишь маленьким кирпичиком - одним из шестидесяти четырех программных компонентов!
Ключевое достоинство data mining по сравнению с упомянутыми ранее методами - возможность автоматического порождения гипотез о взаимосвязи между различными параметрами или компонентами данных. Работа аналитика при работе с традиционным пакетом обработки данных сводится фактически к проверке или уточнению одной-двух порожденных им самим гипотез. В тех случаях, когда начальных предположений нет, а объем данных значителен, существующие системы теряют работоспособность и превращаются в пожирателей времени аналитика. Еще одна важная особенность систем data mining - возможность обработки многомерных запросов и поиска многомерных зависимостей ("насколько повлияла недельная жара в южных штатах на объем продаж конкретной модели охладителей соков?"). Уникальна также способность систем data mining (впрочем, не всех) автоматически обнаруживать исключительные ситуации, т. е. элементы данных, "выпадающие" из общих закономерностей. На механизме обработки исключений, кстати, построена весьма эффективная система обнаружения случаев мошенничества с кредитными карточками, разработанная нейросетевой фирмой HNC. Система подает сигнал тревоги, если структура расходов владельца карточки вдруг резко меняется, что обычно свидетельствует о нежелательной смене владельца (т. е. элементарном воровстве карточки).
Аналитическая фирма Gartner Group недавно провела масштабное исследование рынка систем data mining. Сведя результаты в общий график, где по оси абсцисс отложена мощность базовых методов, а по оси ординат - функциональность и полнота интерфейса, исследователи получили характерный рисунок пирамиды. Левый край ее основания составляют дешевые массовые пакеты фирм Ultimate Resources, Inductive Solutions и др., правый край - сверхдорогие и сверхмощные "монстры" фирм Lockheed и IBM, вершину - многофункциональные системы Epsilon, Logica и Cross/Z. Однако можно предположить, что освоение рынка России начнут не представители вершин этой пирамиды (либо слишком дорогие, либо слишком маломощные для нашего специфического потребителя), а пакеты, располагающиеся ближе к центру и соответственно обладающие лучшим балансом характеристик мощность/гибкость/цена. В первую очередь, к ним относятся пакет IDIS фирмы Information Discovery и пакеты Marksman и DMW фирмы HNC.
Кому на Руси жить хорошо?
Для обработки редакционной базы данных был применен набирающий популярность пакет IDIS фирмы Information Discovery (PC Week/RE уже неоднократно писал о нем). Этот пакет позволяет работать с реляционными базами данных и текстовыми таблицами, обнаруживая корреляции между различными элементами данных и формулируя гипотезы в виде отчета на английском языке. Так, при пробном тестировании базы данных по продажам компьютерных игр, пакет самостоятельно обнаружил эволюцию видеоадаптеров (EGA - VGA - SVGA), возвестил наступление эры multimedia-игр, а также проследил историю "звезды и смерти" многих фирм-поставщиков.
Наиболее интересным оказалось применение методов data mining к информационным полям, касающимся размеров, вида деятельности и перспектив фирм-подписчиков. Шаг за шагом, разрозненные гипотезы пакета начали складываться в некую общую систему, абстрагируясь от частных сведений о читателях и формируя обобщенную картину российского бизнеса. Выяснилось, что для каждого вида деятельности можно сделать заключение не только о его сегодняшних позициях (что элементарно), но и о перспективах его развития на ближайший год. Выбрав в качестве критерия перспективности соотношение фактического числа компьютеров на фирме к планируемому расширению компьютерного парка на год (выраженное в процентах), мы увидели, что для каждого вида бизнеса и размера компании существует совершенно четкий (и достаточно узкий) диапазон вариантов их дальнейшей судьбы.
Наиболее тоскливо себя чувствуют производственные и сельскохозяйственные предприятия и госструктуры - большая их часть собирается сокращаться. Грустную картину кризиса являют собой также государственные системы образования и здравоохранения - их ожидает сокращение примерно на треть. Любопытна волна предприятий-переростков, чей размер перестал соответствовать понизившейся норме прибыли, наблюдается среди системных интеграторов, дистрибьюторов и производителей вычислительной техники. При этом, заметим, сам бизнес остается доходным - речь идет лишь о необходимости реинжиниринга и оптимизации структуры стихийно развивавшихся фирм. Резкий рост - в 2 - 5 раз - планируют для себя (возможно, не всегда обоснованно) небольшие динамичные предприятия, связанные коммуникациями и некоторыми видами научно-технической деятельности.

Доля предприятий, планирующих прирост (%),
по отраслям
Чтобы увидеть картинку в натуральном размере дважды щелкните мышкой по этой строке.
Спокойно смотрят в будущее фирмы, занятые сервисным обслуживанием и консалтингом, их размеры увеличатся в следующем году в полтора-два раза.
Любопытно и еще одно открытие, сделанное при обработке гипотез пакета IDIS. Для каждого вида бизнеса существуют так называемые "островки стабильности" - фирмы, состав и размер которых позволяет им планировать развитие выше среднего по отрасли (и, вероятно, более высокую норму прибыли). Обычно это не очень большие фирмы, имеющие от 20 до 100 компьютеров, хотя каждый вид бизнеса демонстрирует свою специфику.
Таким образом, начав с рутинной обработки скучных таблиц, касающихся частных сведений о подписчиках, мы вышли на уровень обобщения, достаточный (а почему бы и нет?) для проведения консалтинга и целевого реинжиниринга в самых разных отраслях деятельности, подтвердив тем самым, что применение интеллектуальных аналитических инструментов к обработке редакционной базы данных оказалось интересным и плодотворным. А бравурные выводы об эффективности рекламы в нашем издании рекламодатели могут сделать сами.
Андрей Масалович






