













ИНДУСТРИЯ ПРОГРАММИРОВАНИЯ
Что такое PowerBuilder, Delphi, Cи++, Tcl/Tk? Инструменты, причем для “индпошива”, позволяющие, в зависимости от таланта мастера, получить плохое, хорошее или даже выдающееся изделие. А что такое индустрия? Это прежде всего такие технологии и методы организации производства, с помощью которых можно быстро и дешево получать стабильно качественный продукт.
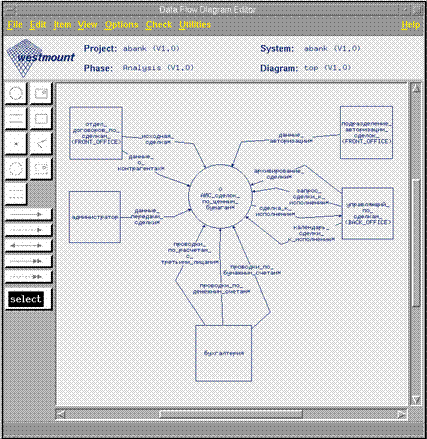
Диаграмма потоков данных верхнего уровня
Если вы скажете, что в программировании нет крупносерийного производства (кроме тиражирования дискет или компакт-дисков), что здесь штучный продукт и к нему нельзя подходить с мерками, скажем, производства автомобилей, я позволю себе с вами не согласиться.
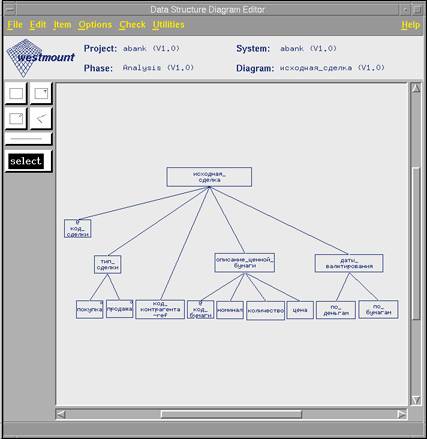
Диаграмма структуры данных
Чтобы выпускать хороший автомобиль нужно, во-первых, иметь хороший проект. В программировании это требование ужесточается, поскольку новый автомобиль еще можно довести до необходимого уровня, уже запустив в производство, в программировании же часто приходится ограничиваться первым экземпляром, который поэтому изначально должен быть достаточно качественным.
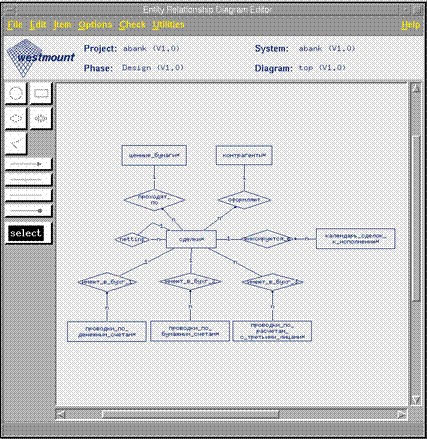
Диаграмма отношений сущностей
Во-вторых, для производства автомобиля нужны грамотные и энергичные технологи, которые решат, что и как лучше делать, то есть какими инструментами воспользоваться, какую дополнительную оснастку разработать или закупить. При программировании также необходимо выбрать инструментарий, в частности СУБД и язык программирования, проработать типовые решения, определить состав библиотек стандартных функций или классов.
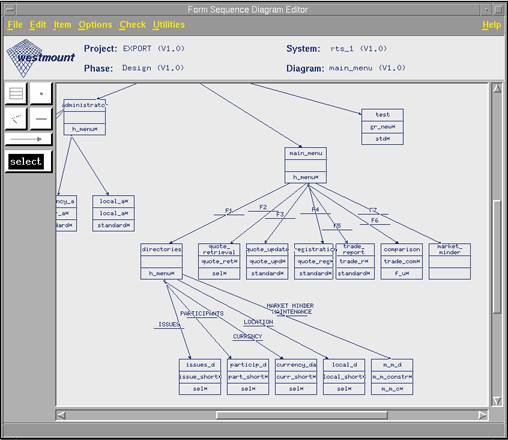
Диаграмма последовательности экранных форм (фрагмент)
После этого начинается массовое производство. Если это автомобиль, то вдоль конвейера расставляются рабочие и обучаются своим достаточно простым операциям. Если это программирование, то программистам-кодировщикам раздаются задания на программирование отдельных модулей или форм. И здесь, что бы вы ни производили, на первый план выходят вопросы соблюдения технологической дисциплины и взаимозаменяемости работников. Каждый сборщик на конвейере должен затянуть все гайки, которые ему положено, с требуемым усилием, чтобы автомобиль не заклинило и чтобы он не развалился, сойдя с конвейера. Каждый кодировщик, участвующий в проекте, должен не забыть, что “...кнопка F1 должна вызывать Help, кнопка F2 должна записывать в базу содержимое экранной формы, а кнопка F3...”, что необходимо предусмотреть ситуацию, когда по условию не выбралось ни одной записи, что в используемой версии языка есть такая-то ошибка, а потому такую-то конструкцию лучше не применять, чтобы программа не зависла.
Короче говоря, производство программ - это действительно производство, и так и надо к нему подходить.
Отличие же его от остальных видов производства - прежде всего в технической оснащенности производителя. Она потенциально очень велика, поскольку в руках у него один из наиболее мощных инструментов, созданных человеком, - компьютер. Вспомните научно-популярные книжки, где описывается мощь современной вычислительной техники, которая может и это, и то, и решения оптимальные принимать, и чертежи чертить, и уж не знаю, что еще. И учит ее этому не кто иной, как Программист, причем с большой буквы. Вот уж он, наверное, получает от компьютера все, что тот может дать. Как бы не так!
Выше я перечислил основные фазы разработки программного обеспечения, не важно, информационной системы или чего-либо другого.
Итак, каким образом компьютер помогает программисту на различных этапах этого процесса?
На стадии подготовки проекта - назовите ее разработкой эскизного и технического проектов, как это называлось при социализме, стадией анализа задачи и глобального проектирования системы или модным ныне сокращением BPR (реинжиниринг бизнес-процессоров) - компьютер чаще всего выступает в роли... пишущей машинки! Аналитик (если у него есть соответствующие навыки и если от него этого требуют заказчик, программисты и кодировщики) пишет некоторый текст. Компьютер с его интеллектуальной мощью, конечно, помогает - следит за орфографией.
В дело вступают собственно программисты - начинается разработка библиотеки стандартных функций или классов. На этом этапе роль компьютера резко возрастает: он теперь не только пишущая машинка, но и канцелярский шкаф! Причем интеллектуальный! Он позволяет всем участникам проекта видеть все написанное остальными, но текст на редактирование дает только одному программисту! Ай да интеллектуальная мощь!
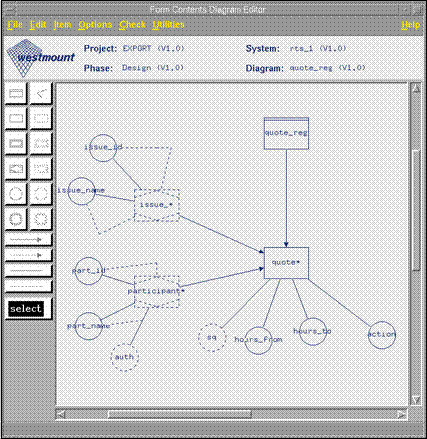
Диаграмма содержания экранной формы
Дальше в дело вступают программисты-кодировщики. Те, кто, используя разработанные библиотеки функций или классов, приспосабливает их к конкретным таблицам и экранным формам. Здесь компьютер выступает еще в одной роли - копира.
Тут меня должны остановить и сказать: “А как же системы визуального программирования, которые позволяют создавать программы без или почти без ручного программирования?”. А что они позволяют? По сути, это системы панельного домостроения, если опять воспользоваться индустриальными аналогиями. Вы может построить дом любого размера, лишь бы этот размер был кратен размеру панели. Попытайтесь отойти от этого условия, и вы опять придете к ручному написанию кода на соответствующем языке четвертого поколения, а то и просто на Си. Конечно, если вы начнете жаловаться, если фирма-производитель решит, что это действительно надо, то в следующей версии могут появиться “панели” под ваш проект. Однако для вас это будет уже старый проект, а перед вами же появятся совсем другие задачи.
Grindery Grabber
Кроме того, это не комплексная автоматизация, эти инструменты не поддерживают всего жизненного цикла проекта.
И что в итоге получается? Группа высокоинтеллектуальных разработчиков, оснащенная самой мощной техникой, вручную разрабатывает проект, хорошо, если не пожалев времени на изложение его на бумаге. После этого в дело вступают наиболее квалифицированные программисты. Эти еще кое-как оснащены: ERwin, там, для создания базы данных, средства разработки библиотек классов или готовые библиотеки. А дальше идут кодировщики, пищущие основную массу текста “по образцу” и вносящие в него основную массу ошибок, которые потом долго отлавливаются и исправляются. Конечно, объектный подход позволяет сократить число кодировщиков и вносимых ими ошибок. Это выход? Как бы не так! Тут легко можно попасть в другую западню. Какой программист любит документировать программу? А вносить исправления в чужую, достаточно сложную, но плохо документированную программу? И уход любого члена команды ставит под удар весь проект.
Интеллектуальная мощь компьютера на службе программиста
Конечно, все изложенное - лишь иллюстрация типичного на сегодня положения дел в России. Если не вдаваться в детали, это явные последствия слишком быстрого распространения персоналок и недостатка денег. В индустриальном же и тем более постиндустриальном мире существуют и активно используются инструменты, позволяющие аналитику получить как побочный продукт своего труда качественно оформленный проект, программисту тщательно проработать и оформить библиотеки, а кодировщику ограничиться внесением вручную небольших и хорошо документированных фрагментов текста программы, возложив всю рутинную работу на компьютер. И именно о такой технологии, позволяющей действительно рассматривать программирование как вполне индустриальную отрасль производства, а не как нечто непонятное на грани искусства и ремесленничества, я и хочу рассказать.
Инструменты, способные поднять программирование до индустриального уровня, традиционно называются CASE-средствами, где CASE - это не чемодан, а Computer Aided Software/System Engineering (автоматизированное проектирование систем).
Основу технологии, предлагаемой нашей фирмой DataX/FLORIN, составляют CASE-средства фирмы Cayenne Vantage Team для структурного подхода к проектированию (хочу подчеркнуть, к проектированию, а не программированию) и ObjectTeam for OMT для объектного подхода. Поясню: I-CASE Yourdon фирмы Westmount, Vantage Team builder фирмы CADRE и Vantage Team фирмы Cayenne - это один и тот же продукт, как и I-CASE OMT фирмы Westmount и ObjectTeam фирмы Cayenne. Короче, названия меняются, а продукты остаются.
В дальнейшем речь пойдет о Vantage Team. Это связано с тем, что сам я предпочитаю в проектировании структурную терминологию. В силу многолетней привычки она кажется мне более естественной и понятной для заказчика, не являющегося программистом. Возможности ObjectTeam for OMT в целом аналогичны.
Vantage Team фирмы CADRE позволяет использовать метод структурного проектирования Йордона (Edward Yourdon) с некоторыми расширениями и дополнениями. В целом метод весьма естественный и достаточно простой для освоения как разработчиком, так и заказчиком. То есть вы без проблем сможете обсуждать с заказчиком детали проекта, почти не тратя время на то, чтобы обучить его своему языку, в частности, благодаря графическому представлению основных результатов разработки.
При использовании Vantage Team работа над проектом разбивается на четыре фазы: анализ, архитектура (в соответствии с отечественными традициями - эскизное проектирование), дизайн (техническое проектирование) и программирование.
Анализ: постановка задачи, общие принципы решения
В фазе анализа Vantage Team предоставляет редактор диаграмм потоков данных, используемых как для описания взаимодействия системы с внешним миром (контекстная диаграмма), так и для определения структуры процесса обработки информации (диаграммы потоков данных более низких уровней). При желании можно формализовать требования к разрабатываемой системе в виде списка событий и откликов. В этом случае обеспечивается контроль за соответствием контекстной диграммы и списка событий. Кроме того, контролируется правильность декомпозиции диаграмм при переходе с уровня на уровень.
Для анализа структуры и разработки модели данных предлагается весьма широкий спектр средств, включающий в себя диаграммы структуры данных, диаграммы отношений сущностей и текстовое описание в форме БэкусаНауэра. Различные типы диаграмм сравниваются между собой на непротиворечивость.
Архитектура - общие принципы решения задачи
С помощью оригинальных диаграмм архитектуры системы можно разработать архитектуру вычислительного комплекса и уточнить аппаратное оснащение рабочих мест системы. Определяются: распределение задач между вычислительными средствами (в том числе между клиентом, сервером и промежуточным слоем, если вы их используете), а также потоки данных между вычислительными средствами, задачами (отдельными исполняемыми модулями) и процессами обработки информации в составе одной задачи. Создаются спецификации (формализованные описания) процессов обработки информации нижнего уровня. При необходимости можно ввести управляющие потоки и процессы, а также их описание с помощью диаграмм состояний и переходов.
Для описания необходимой структуры базы данных используются диаграммы отношений сущностей в нотации Чена. Они позволяют указывать различные типы реляционных отношений между таблицами (общее, тотальное, слабое, рекурсивное), связи различной мощности (1-1, 1-N, N-N), а также различные суб- и супертипы.
Диаграммы структуры данных и аналогичные им по нотации диаграммы структуры управляющих потоков могут использоваться для определения структуры и типов программных переменных.
В фазе архитектуры начинается определение принципов построения интерфейса системы с использованием диаграмм последовательности экранных форм. Эти диаграммы позволяют указывать как условия переходов между экранными формами, так и выполняемые при этом действия.
Дизайн: детальная проработка основных решений на логическом уровне
Фаза дизайна завершается “за один шаг до программы”. Здесь осуществляются окончательная отработка модели данных, функциональной модели и проектирование интерфейса системы с помощью уже упоминавшихся диаграмм, а также ряда специальных типов диаграмм, позволяющих однозначно сформулировать требования к интерфейсу и программе.
Разработка структуры базы данных предполагает полное описание всех атрибутов сущностей (полей таблиц). Для этого используется механизм логических типов данных и логических ограничений, практически полностью поддерживающий понятие домена. Можно задать внешние (используемые при работе с заказчиком и в документации) и внутренние (программные) имена таблиц, полей и программных переменных. Определяются необходимые политики поддержания целостности базы по ссылкам при основных действиях (INSERT, UPDATE, DELETE) с различными таблицами.
В основу разработки приложения положены интегрированные диаграммы последовательности экранных форм. В фазе дизайна в этих диаграммах для каждой формы указывается имя диаграммы содержания экранной формы и имя структурной схемы программного модуля, реализующего соответствующий процесс обработки информации.
Диаграммы содержания экранных форм позволяют указать таблицы и их поля, представленные в форме, способ их представления (список - полноэкранная форма), а также основные функциональные возможности (доступность таблиц для записи или только для чтения информации). На диаграмме можно указать, необходимо ли открыть просмотровое окно для поиска значений в соответствующей таблице.
Структурные схемы программ - универсальное средство описания функциональных возможностей приложения. Они позволяют описать любую программу с произвольной точностью (до функции, до группы операторов, до отдельного оператора, до отдельных составляющих оператора типа структуры AFTER FIELD в операторе INPUT). Основными элементами структурных схем являются заголовок или вызов функции, хэт-модуль (“модуль со шляпой”, что соответствует используемому для него обозначению), позволяющий записать произвольные конструкции на языке программирования и указать их место в программном файле (например, из любого хэт-модуля можно добавить определение еще одной переменной в секцию описания глобальных, модульных или локальных переменных, добавить в файл описание еще одной функции и т. п.), операторы выбора (MENU, IF, IF...ELSE, CASE), операторы повтора (WHILE, FOR) и библиотечные операторы (предопределенные или стандартные модули), представляющие собой, как будет показано ниже, весьма мощный инструмент быстрой разработки приложений.
Vantage Team для программиста
Что же остается на долю программиста, осуществляющего разработку проекта с использованием Vantage Team.
Создание базы данных. SQL-скрипт для создания базы со всеми необходимыми операторами CREATE TABLE (с указанием нужных ограничений), ADD FOREIGN KEY и CREATE PROCEDURE генерируется автоматически. При этом для каждой таблицы создается описание трех хранимых процедур, обеспечивающих выполнение функций INSERT, UPDATE и DELETE. Использование процедур в приложении позволяет обеспечить выполнение требуемых политик поддержания целостности базы по ссылкам.
Генерация экранных форм. При переносе проекта в стадию программирования экранные формы генерируются автоматически в соответствии с диаграммами содержания экранных форм. Их ручная доработка для более рационального или эстетичного размещения полей на экране может осуществляться в любом текстовом редакторе.
Генерация кодов программ. Включает следующие стадии:
- дописывание необходимого кода в соответствии с описаниями процессов обработки информации, выполненными в предыдущих фазах разработки. Этот код записывается в виде спецификаций для соответствующих элементов структурной схемы;
- автоматическая генерация текста программных файлов, включая сбор и размещение в файле спецификаций элементов структурной схемы, а также генерацию текстов по шаблонам для библиотечных модулей.
Сборка программы. Vantage Team Builder предлагает программисту достаточно удобные инструменты для описания зависимостей между файлами с исходными текстами программ, а также между другими входящими в приложение файлами (например, файлами с текстами подсказок). На основе этого описания для приложения автоматически генерируется makefile, управляющий компиляцией и сборкой программы. По желанию программиста может быть собран как файл с интерпретируемым, так и с исполняемым кодом программы.
Vantage Team и техническая документация
Все диаграммы, которые вы рисуете с помощью CASE, все тексты с описаниями и комментариями включаются в документацию по определенным шаблонам. Генерация такой документации производится автоматически. Ее легко можно повторить после внесения любых изменений. Кроме того, она может поддерживаться одновременно для нескольких версий проекта (например, для тестируемой и той, что готова к продаже). По желанию можно изменить состав и формы представления отдельных документов в документации либо включить в нее дополнительные документы, указав правила их формирования.
Промежуточные итоги
Итак, CASE Vantage Team представляет собой единую среду, не выходя из которой вы проходите все стадии работы над проектом: от формулировки замысла через анализ задачи до внесения последних изменений в текст программ и документацию.
Аналитику она предоставляет все необходимые инструменты для того, что раньше называлось разработкой эскизного проекта, а теперь часто называется перепроектированием бизнес-процессов. Вы умеете это делать и без CASE-средств? Ну и прекрасно! Значит, вы быстро освоите CASE и оцените, насколько проще рисовать соответствующие диаграммы на экране, чем на обратной стороне старых распечаток. И насколько графическое представление на данной стадии работы над проектом компактнее, нагляднее и строже текстового документа. И какую пользу могут принести встроенные в CASE средства контроля корректности проекта.
Простейший пример. Для учебных курсов по CASE-технологии мы использовали реальный проект системы электронных платежей, подготовленный в Центробанке и выполненный как текстовый документ объемом в несколько десятков страниц. Чтобы прочитать его, требовалось не менее часа, а чтобы разобраться - много больше. После того как мы перевели его в CASE, он свелся к десятку весьма наглядных диаграмм с короткими пояснениями, в которых можно было разобраться за пятнадцать минут.
Короче говоря, аналитики Центробанка, занимавшиеся этим проектом, добились-таки, чтобы и у них CASE не лежал в коробке, а был установлен на машине и работал.
Хочу отметить несколько моментов, отличающих Vantage Team от большинства других CASE-средств, предназначенных для аналитика.
1. Диаграмма архитектуры системы - это уникальная диаграмма, которая позволяет вам привязать проект к вычислительному комплексу. С ее помощью можно определить потребность в вычислительных средствах для реализации вашего проекта, оценить и выбрать наиболее адекватное решение в части распределения задач между клиентом, сервером и промежуточным слоем.
2. Vantage Team - едва ли не единственное CASE-средство, в котором предусмотрена возможность анализа структуры реальных данных с помощью диаграмм структуры данных. Причем CASE обеспечивает автоматическое сравнение этих диаграмм с диаграммами отношений сущностей, с помощью которых проектируется реальная база данных, и указывает на обнаруженные расхождения.
3. Диаграмма содержания экранной формы. Этот инструмент позволяет не только указать поля, содержащиеся в форме, но и очень четко описать возможности пользователя при работе со сложными экранными формами.
Программист (напомню, это тот, кто пишет библиотеки и, как я однажды услышал прекрасный термин, “болванарий”, то есть типовые фрагменты, болванки, которые потом переписываются кодировщиками для многочисленных конкретных таблиц и форм) получает в CASE прекрасный и очень мощный инструмент предопределенных модулей. Это модули, генерирующиеся автоматически по заранее написанному шаблону. Один раз написанный шаблон может быть использован для разных экранных форм и для работы с различными таблицами базы данных. В Vantage Team входит набор шаблонов, достаточный для выполнения стандартных операций с таблицами базы данных. При этом поддерживаются весьма сложные экранные формы, включающие поля из нескольких таблиц с различными функциональными возможностями для каждой. Но главное, используя имеющийся набор функций доступа к репозиторию проекта, вы можете легко разрабатывать свои шаблоны, то есть, возвращаясь к старой аналогии, создавать “панели” необходимого размера и быстро собирать из них основной объем вашего приложения.
Шаблоны пишутся с использованием конструкций языка Tcl, предоставляющего массу удобств при работе с текстом. В нем есть мощные функции для работы со строками и со списками, а также в полной мере используются преимущества интерпретатора: вы можете собрать очередную команду как строку и тут же выполнить ее.
Шаблоны можно употреблять не только для кодогенерации на целевом языке, но и для усовершенствования или настройки генерации SQL-скрипта. Мы сами использовали Vantage Team для следующих целей.
Поддержка архивной базы данных. При разработке своей офисной системы мы решили хранить в основной базе данных только актуальную информацию, а в архивной базе - всю остальную. Реализация такого подхода в рамках СУБД Informix не представляет труда, за исключением одного момента - необходимо написать по два триггера на каждую таблицу для операций Insert и Update соответственно. При этом надо помнить, что поиск и исправление ошибок, неизбежно возникающих при ручном написании хранимых процедур и триггеров, - очень трудоемкое дело. Простые шаблоны позволили полностью автоматизировать процесс и обойтись без ошибок вообще. При этом для части таблиц поддерживалось принудительное удаление из основной базы неактуальной информации, а для других таблиц оно было оставлено на усмотрение пользователя.
Поддержка ролей. Сервер Informix OnLine до версии 7.11 не поддерживал механизма ролей в явном виде. С помощью CASE мы, во-первых, просто и наглядно описали права нескольких ролей, необходимых для нашей системы, и, во-вторых, сгенерировали хранимые процедуры, позволявшие без затруднений давать пользователю права, соответствующие произвольному набору его ролей.
При проектировании программы с помощью структурных схем легко выделить не только однотипные фрагменты, для которых можно использовать готовые шаблоны или разработать дополнительные, но и выделить те нестандартные фрагменты, которые в любом случае приходится дописывать вручную. Принятая в CASE технология написания таких фрагментов опять-таки совмещает разработку и документирование. Вы рисуете соответствующую структурную схему и в ее уникальные элементы вписываете нужный код на языке программирования.
А где же кодировщики, этот основной источник ошибок? Ау-у-у...
И при всем этом степень документированности такова, что ввести в проект нового человека не составит особого труда.
Индустриальной технологии - индустриального заказчика
Итак, вы тщательно проработали проект и, гордые собой, демонстрируете результат заказчику.
И тут заказчик, как это обычно и бывает, понимает, что вот здесь он забыл сказать о том, что должна быть еще вот такая опция меню, а вот здесь он о чем-то не подумал, а вот там вы его не точно поняли, и вообще, он себе это представлял совсем иначе.
Короче говоря, технология новая, а заказчики-то старые.
Но и здесь есть новые решения. CASE позволяет вам легко создать прототип, по которому заказчик определит, что же его не устраивает в вашей разработке. Для этого не нужно даже тщательно прорабатывать экранные формы. Достаточно для каждой из них указать, с какой таблицей она должна работать. После этого вы получаете возможность достаточно быстро доработать те экранные формы, которые не устроили заказчика, и уточнить задание на те уникальные функции, которые необходимо написать. При работающем прототипе все это делается значительно эффективней.
Но именно здесь мы и столкнулись с самой большой проблемой при использовании CASE-средств. Стандартный вариант генерации на уровне таблицы до обидного примитивен, а тратить много времени на подготовку первой версии для первых замечаний - значит тратить его зря. То есть нужно суметь быстро сгенерировать вариант программы с достаточными функциональными возможностями и с достаточно продвинутым интерфейсом. Такой кодогенератор был нами создан. Причем опыт его использования показал, что часто он обеспечивает получение экранной формы с теми возможностями, которые и нужны. Это кодогенератор Grindery OneStep для Informix-4GL. С одной стороны, у него более широкие возможности работы со связанными таблицами, чем у стандартного кодогенератора, а с другой - его использование требует минимальной предварительной проработки содержания экранной формы.
Написанный нами кодогенератор прошел серьезную практическую проверку как основной инструмент написания кода при разработке системы автоматизации коммерческой и производственной деятельности нашей фирмы. С его помощью было сгенерировано не менее 80% общего объема приложения (около 2 Мб исходных текстов программ) и почти все экранные формы. В целом он, по нашим оценкам, сократил в несколько раз время написания кода (если сравнивать с проектами, выполнявшимися вручную). Еще сильнее сократилось время на отладку и тестирование приложения, поскольку из автоматически сгенерированного кода для работы с примерно полусотней таблиц достаточно проверить один-два стандартных варианта. Тщательного тестирования требуют лишь те 20% кода, которые написаны вручную полностью или частично.
Переносимость
Еще одно модное нынче понятие - это переносимость проекта на различные платформы и средства разработки. Стандартно Vantage Team поддерживает возможность использования в качестве целевой СУБД Informix, Ingres и Oracle. Код программы при этом генерируется на соответствующем 4GL. Однако есть здесь и дополнительные возможности.
Во-первых, фазы анализ и архитектура выполняются вообще без привязки к конкретной СУБД или средству разработки. Конечно, если это ясно заранее, вы, скорее всего, что-то такое специфическое заложите и в решения, которые вы принимаете. С другой стороны, если есть возможность выбора, то, представляя конкретные особенности проекта, его сделать легче.
Во-вторых, логические типы данных привязываются к конкретной СУБД через промежуточный слой - стандартные типы, общие для всех серьезных реляционных СУБД. Так что и здесь проблем не будет.
В-третьих, диаграммы последовательности и содержания экранных форм фактически не привязаны к средствам разработки, поскольку основные элементы их алфавита могут быть реализованы практически любым современным средством.
Остаются структурные схемы программ. Сами диаграммы, вообще говоря, тоже не привязы к конкретному языку. Вызов функции, цикл или проверка условий есть практически во всех языках. Остаются спецификации элементов диаграмм, выполняемые на целевом языке, и предопределенные модули. Перепишите их - и вы перенесли проект в новую среду разработки.
Для нас наиболее актуальной была проблема переноса приложения на NewEra.
И тут встал вопрос: “А как же быть с NewEra?” NewEra, современное средство разработки приложений фирмы Informix, поддерживает визуальную разработку. Cтандартные рекомендации для таких средств обычно сводятся к использованию простого CASE типа ERwin только для генерации базы данных. Все остальное предлагается выполнять непосредственно из них. Такой подход дает огромное ускорение по сравнению с прямым программированием на том же Informix-4GL. А вот если сравнить с генерацией Informix-4GL из Vantage Team, то получается сильное замедление.
Конечно, можно было взять ObjectTeam for OMT, изначально поддерживающий генерацию кода для объектных языков, включая NewEra, Си++ и Smalltalk. Но выше я уже упоминал о своем предпочтении структурных подходов к проектированию. Как показал наш опыт, это не является препятствием для реализации приложения с использованием объектно-ориентированных средств. Более того, генерация кода для объектно-ориентированного языка из структурного CASE оказалась проще, чем для процедурного языка. По крайней мере в том смысле, что значительная часть кода выносится в библиотеки классов и непосредственно на долю кодогенератора его остается значительно меньше.
Тем не менее при построении генераторов для NewEra нам пришлось решать весьма сложный принципиальный вопрос: как осуществить переход между богатыми возможностями графического интерфейса и значительно более ограниченными возможностями алфавитно-цифрового? В отличие от многих универсальных (позволяющих для одного приложения создавать и тот и другой интерфейсы) средств разработки мы пошли не по пути копирования экрана, а по пути реализации аналогичного по функциональным возможностям набора методов.
Когда через некоторое время мы занялись освоением еще одного объектного средства программирования - SuperNova, для него мы также написали кодогенератор. В результате появилось семейство кодогенераторов Grindery фирмы DataX/ FLORN для пользователей Vantage Team. Причем кодогенератор для SuperNova на сегодняшний день обладает наибольшими возможностями в части разнообразия генерирующихся автоматически интерфейсов. Управление кодогенерацией, как и в остальных генераторах, осуществляется в нем очень ограниченным набором дополнительных атрибутов.
А нельзя ли подешевле и побольше?
Увы, на сегодня потребители CASE в России - это лишь самые крупные банки. Фирмы поменьше просят чего-нибудь подешевле. А почему бы и нет? Технология, заложенная в основу нашей кодогенерации, предполагает определение для полей таблиц базы данных небольшого набора дополнительных атрибутов: альтернативный (предметный) ключ, участие поля в look up-формах и еще буквально два-три.
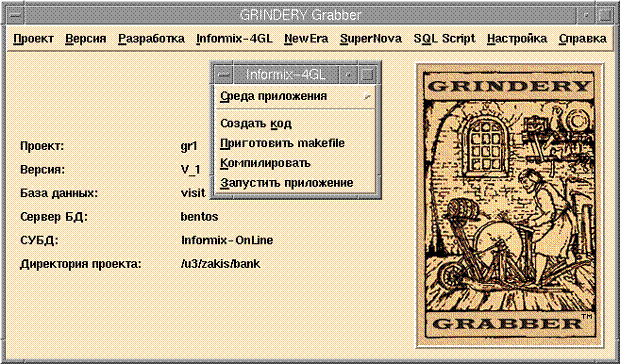
Итак, проект у вас небольшой. Для создания базы данных вам хватило того же ERwin. Информация обо всех полях базы данных лежит в системных таблицах. Прочитать бы ее, обеспечить возможность задать еще по нескольку атрибутов и запустить кодогенератор. И такой инструмент действительно есть. Это Grindery Grabber (несмотря на свое английское название, продукт предоставляет русскоязычный интерфейс).
Grindery Grabber позволяет прочитать структуру реальной базы данных, проставить необходимые атрибуты и сгенерировать код. Но на сегодня пропадает возможность более тонкой настройки кодогенерации по диаграмме содержания экранной формы или какому-нибудь ее аналогу.
Планы и перспективы
В планах дальнешего развития семейства кодогенераторов Grindery Grabber предусматривается создание относительно дешевой среды быстрой разработки, ориентированной на использование различных визуальных средств и поддерживающей полный жизненный цикл проекта.
Проект этот развивается весьма быстро, поэтому самый простой способ ознакомиться с его текущим состоянием и ближайшими перспективами - посетить наш web (www.florin.ru).
Алексей Закис
С Алексеем Закисом, старшим аналитиком фирмы DataX/FLORIN, можно связаться по адресу: zakis@florin.ru.








