













Объектно-ориентированные технологии и имитационное моделирование
Для проведения любого аналитического исследования необходимо собрать и классифицировать исходные данные. Это особенно важно, если изучаются различные аспекты общественных процессов, а для автоматизации анализа используется вычислительная техника. Подобное сочетание предмета анализа (социальные процессы) и используемого средства анализа (компьютерная техника) требует решения непростых задач формализации информации об общественных отношениях, обеспечения полноты и четкости данных, создания однозначных алгоритмов их обработки. Существующие технологии автоматизированного хранения, обработки и анализа трудноформализуемых данных (такие, как реляционные банки данных, программы контекстного и индексируемого поиска и статистической обработки текстовых файлов, гипертекстовые поля) не учитывают многоуровневость и направленность связей между реальными объектами, а также динамику изменения как самих объектов, так и связанных с ними процессов и явлений. В силу этого с их помощью удается решать лишь частные задачи изучения социальных отношений. В качестве универсального метода исследования общественных явлений может быть предложено имитационное моделирование, основанное на объектно-ориентированной технологии.
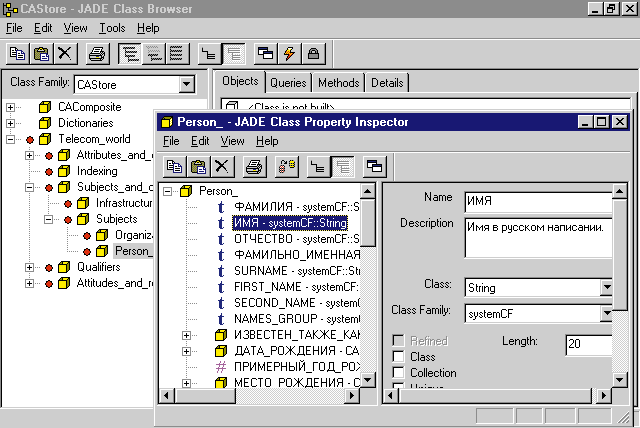
Экранный интерфейс СУБД Jasmine, фрагмент описания класса “Лицо”
Под имитационным моделированием будем понимать метод анализа и прогнозирования развития некоторой системы с помощью имитационной модели. В свою очередь, под имитационной моделью понимается модель, сохраняющая с требуемой наблюдателю степенью адекватности логическую структуру системных явлений и процессов, а также характер и структуру информации о состоянии и изменениях системы и составляющих ее элементах и отношениях.
Имитационное моделирование общественных отношений имеет свои особенности, что отражается на составе и структуре классов объектов; характере и направленности допустимых взаимосвязей объектов, принадлежащих к различным классам (о структуре имитационной модели см. “Объектные модели данных и их реализация”, PC Week/RE, № 20/98, с. 48); методах обработки информации, подаваемой пользователем на вход системы.
Вообще говоря, в нашем понимании, имитационная модель - это объектная модель данных, имеющая определенную минимальную опорную структуру, которую пользователь может дополнить и расширить с учетом специфики решаемых задач, а также базовых методов обработки. В совокупности технология имитационного моделирования позволяет:
- обеспечить комплексность и системность сбора, обработки и анализа информации за счет концентрации в рамках единого информационного поля взаимоувязанных объектов разнородной структуры;
- создать многомерную информационную модель реального мира, в котором каждому явлению, процессу или участнику в каждый промежуток или момент времени его существования будет соответствовать уникальный информационный аналог;
- отслеживать динамику изменения процессов во времени, хронометрировать поступающие данные и осуществлять автоматическую актуализацию хранимой в банке информации без дополнительных затрат на поддержание информационного архива;
- учитывать, хранить и анализировать информацию о структуре и содержании связей и отношений объектов реального мира;
- хранить в рамках единого информационного пространства документальную и фактографическую информацию, иметь удобный и простой интерфейс для быстрых переходов из документальной подсистемы в фактографическую и наоборот.
Наиболее эффективно использование имитационных моделей в системах слежения, призванных регистрировать и обрабатывать данные о состоянии, взаимодействии и изменениях динамических объектов в режиме реального времени, а также в системах анализа исторических событий, обусловленных общественной деятельностью людей.
Управление имитационными моделями осуществляется с помощью объектно-ориентированных СУБД. Однако не всякая объектно-ориентированная СУБД может быть использована для этих целей. Ниже описан опыт автоматизации изучения социальных процессов в сфере телекоммуникаций с помощью СУБД CronosPlus российской фирмы “Кронос”, а также СУБД Jasmine фирмы Computer Associates.
Сравнение объектно-ориентированных СУБД и возможностей их использования для управления имитационными моделями
СУБД CronosPlus изначально разрабатывалась как инструмент информационно-логической обработки и анализа трудноформализуемых данных, имеющих сложную структуру связей, в том числе и опосредованных. Ориентируясь изначально на сетевую модель данных, разработчики СУБД впоследствии добавили в систему интерпретатор собственного языкового средства, который позволяет пользователям создавать методы уровня реализации. Однако подобная эволюция системы до настоящего времени не привела, например, к появлению такого классического атрибута объектной технологии, как наследование. В рамках модели данных CronosPlus (разработчики данной системы назвали ее объектной сетевой моделью) возможно наследование свойств путем задания ссылки на родительский объект и перенесения наследуемых свойств на уровень порожденного объекта. Крайне ограничены возможности пользователя и по созданию собственных методов уровня класса.
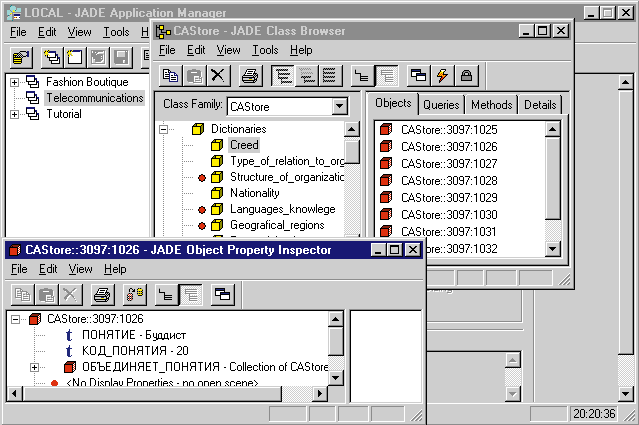
Экранный интерфейс СУБД Jasmine, пример объекта класса “Вероисповедание”
Подобных недостатков нет у СУБД Jasmine, которая сразу создавалась на принципах объектной технологии с целью (как следует из документации) предоставления пользователю среды визуального проектирования мультимедийных приложений и обеспечения доступа к ним через Web. В отличие от CronosPlus, предлагающей в основном инструментарий информационно-логической обработки строковых и числовых данных, Jasmine имеет широкий выбор средств обработки мультимедийных и графических данных.
Неоспоримое преимущество Jasmine перед CronosPlus - наличие возможности написания Internet-приложений и обеспечение тем самым доступа к банку данных через Web (в CronosPlus таких возможностей в настоящее время не имеется). Кроме того, Jasmine располагает и более богатыми средствами создания запросов и методов обработки данных на собственном языке программирования ODQL (Object Database Query Language), а также на так называемых “гостевых” языках - Cи, Cи++, Java и Visual Basic.
Существенным преимуществом CronosPlus перед Jasmine является устойчивость структуры данных. Система не разграничивает этапы проектирования банка данных и наполнения его информацией. Практически, создав лишь один класс и описав в нем единственный параметр (свойство класса), пользователь может приступать к формированию объектов. Впоследствии в течение жизненного цикла банка данных возможна многократная коррекция структуры и взаимосвязей классов при сохранении уже накопленных сведений и сформированных объектов.
Такой устойчивости структуры данных лишена СУБД Jasmine. В ней четко различаются этап проектирования банка данных и этап его эксплуатации, наступающий после построения классов (вызова команды Build опции Tools браузера классов). Дальнейшая модификация структуры созданных классов возможна только с помощью специальных утилит, входящих в комплект поставки Jasmine, и доступна администратору системы или пользователям высокой квалификации. Использование стандартных средств для внесения изменений в структуру данных (команды Unbuild опции Tools) ведет к разрушению установленных после построения классов перекрестных ссылок между ними и вызывает необходимость перепроектирования структуры классов.
Подобный недостаток Jasmine, вероятно, связан с попыткой разработчиков системы упростить проектирование банков данных за счет применения в качестве идентификаторов имен классов и их свойств. В СУБД CronosPlus в качестве идентификаторов классов и свойств используются дополнительные служебные параметры: неизменяемые мнемонические и числовые значения, которыми оперирует программное обеспечение. Имена классов и свойств CronosPlus воспринимает как комментарии, и пользователь может их произвольно изменять.
Вторая причина повышенной устойчивости структуры данных в CronosPlus обусловлена тем, что в логической модели данных связи между классами описываются на уровне “свойство - свойство”, т.е. сам пользователь задает взаимно однозначное соответствие между свойствами различных классов. В СУБД Jasmine связи определяются пользователем на уровне “свойство - класс”, устанавливаются по внутреннему алгоритму системы с помощью команды Build и разрушаются при вызове команды Unbuild.
В СУБД CronosPlus изначально заложены типовые команды и блоки, реализующие специальные функции, которые обеспечивают информационно-логическую обработку трудноформализуемых данных и генерацию новой информации в автоматизированном режиме. Например, с их помощью можно:
- искать цепочки опосредованных связей;
- сравнивать объекты банка данных между собой;
- сравнивать вновь поступающие данные с имеющимися в банке, при необходимости дополняя существующие объекты недостающими данными.
Интерфейс системы позволяет формировать запросы либо в терминах языка запросов, либо в графической форме путем выбора необходимых свойств и наложения на них ограничений. При этом для настройки системы и разработки собственных уникальных методов от пользователя требуются минимальные усилия.
Благодаря простоте описания классов и свойств в СУБД CronosPlus существенно упрощен сложный процесс проектирования банков данных, создавать которые смогут пользователи, не обладающие специальными знаниями. Система же Jasmine требует от программистов опыта работы с языком построения запросов к объектной базе данных ODQL (Object Database Query Language) и, возможно, с Cи, Cи++, Java, Visual Basic.
Логическая модель данных, реализуемая средствами Jasmine, не обладает той степенью гибкости, которую обеспечивает CronosPlus. В частности, Jasmine не позволяет создавать многовариантные перекрестные ссылки из одного свойства на различные классы данных, что естественным образом реализуется в CronosPlus.
Например, класс объектов “Организация” может группироваться с классом “Лицо” (как это имеет место для свойства “Субъекты события” класса “Событие”) и одновременно в рамках одной и той же имитационной модели - с классом “Географический адрес” (для свойства “Представительства и филиалы организации” класса “Организация”).
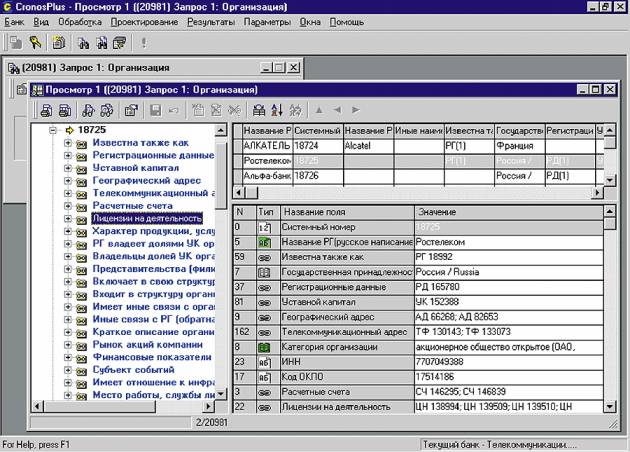
Экранный интерфейc СУБД Cronos Plus, объект “Ростелеком” класса “Организация”
При необходимости ссылки из одного свойства на различные классы данных Jasmine предлагает создавать абстрактный суперкласс для группируемых подклассов и делать ссылки из свойства на этот класс. Однако это не всегда возможно, так как в различных ситуациях один и тот же класс может группироваться с разными классами. В подобном случае пользователь Jasmine должен задать несколько одинаковых по смыслу свойств, но с различными именами, каждое из которых будет ссылаться на один-единственный класс.
Механизм взаимосвязей классов в СУБД CronosPlus позволяет учитывать не только многовариантность, но и направленность ссылок между объектами банка данных: ссылки могут быть равноправными или иерархическими. Навигация по ссылкам между объектами может осуществляться в прямом и в обратном направлениях, так как на этапе загрузки информации в банк данных при задании прямой ссылки на объект, связанный с исходным объектом, обратная отсылка устанавливается автоматически.
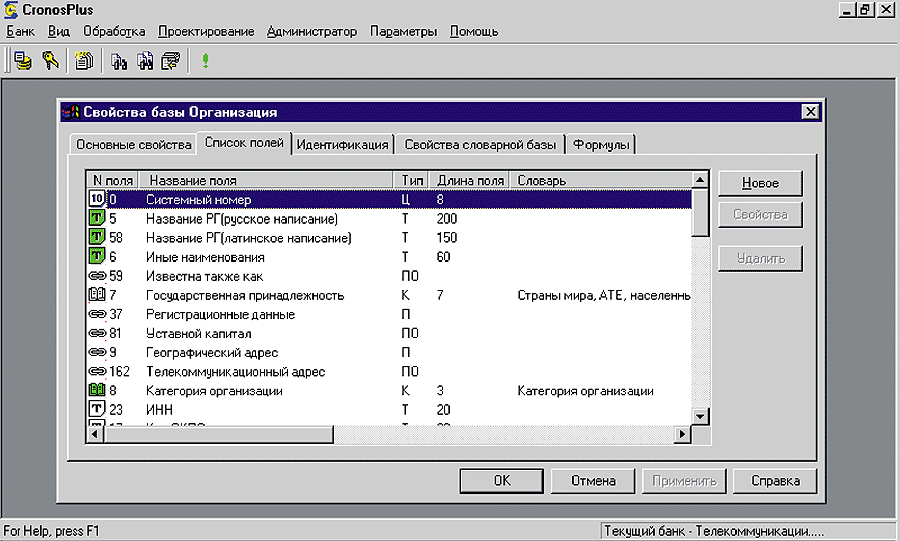
Экранный интерфейс СУБД Cronos Plus, фрагмент описания класса “Организация”
В СУБД Jasmine понятие равноправной отсылки отсутствует, а решение проблемы “уравнивания в правах” связей между объектами ложится на пользователя.
Ограничения модели и алгоритмов обработки данных в Jasmine проявляются также в том, что при удалении объектов БД имевшиеся в них перекрестные ссылки на другие объекты остаются, что может привести к ошибкам при обработке данных. В CronosPlus эта ситуация разрешается на уровне управляющей программы, в СУБД Jasmine переложена на уровень пользователя, который должен при удалении объектов, связанных с исходными объектами перекрестными ссылками, удалять и эти ссылки путем переопределения метода delete().
Подытоживая сказанное, можно сделать вывод о том, что СУБД CronosPlus наиболее эффективна в качестве средства сбора, обработки, хранения и анализа трудноформализуемых данных, а также инструмента имитационного моделирования. Это подтверждается почти десятилетним опытом ее сопровождения и развития разработчиками, широким использованием для обработки гуманитарной информации многими государственными организациями и коммерческими структурами в ряде стран СНГ.
Jasmine целесообразно применять для накопления и хранения больших объемов мультимедийных данных, манипулирования ими и передачи удаленным пользователям через Internet. Использовать данную СУБД для решения логических задач, связанных со сложными структурами данных, имеющими множество перекрестных ссылок, вряд ли возможно.
О специфике систем управления имитационными моделями
Построение имитационных моделей целесообразно для организации хранилищ данных в составе экспертных систем и систем поддержки принятия решений, так как позволяет наиболее адекватно описать окружающую действительность. Это объясняется тем, что имитационное моделирование - универсальная технология изучения трудноформализуемых данных, позволяющая подвергнуть их автоматизированной обработке и анализу.
Ниже перечислены некоторые специфические черты, которыми, как показывает опыт, должны обладать системы управления имитационными моделями (СУИМ).
1. Единство опорной информационной структуры модели и встроенных методов логической обработки данных, реализуемых на уровне управляющей программы. Под опорной структурой имитационной модели мы понимаем некоторую минимальную совокупность определенным образом взаимосвязанных классов данных, включающих обязательный перечень параметров, с привязкой к которым функционирует СУИМ. Опорные классы имитируют всеобщие категории, такие, как “пространство”, “время”, “событие”, “понятие”, а также различные виды источников информации.
Основу этих классов пользователь менять не может, однако ему разрешено добавлять в них новые параметры, расширять модель собственными классами данных и связывать их с опорными (или системными) классами перекрестными ссылками. СУИМ использует опорные классы, генерируя в каждом создаваемом пользователем классе некоторый набор обязательных параметров (“системный номер”, “дата актуализации объекта”) и ссылок (скажем, на источники информации). Кроме того, она может обращаться к значениям опорных классов для выполнения тех или иных действий пользователя (например, для навигации по банку данных в заданном “временном слое”, подробности см. ниже).
2. Сочетание встроенных универсальных методов обработки данных со специфическими пользовательскими. Это необходимо для распределенного многоступенчатого анализа информации. С одной стороны, наиболее общие, типовые методы анализа, применимые для обработки любых типов данных, должны быть встроены в систему и реализованы на уровне управляющей программы. С другой - система управления имитационной моделью должна иметь мощное инструментальное средство манипулирования данными, позволяющее пользователю создавать собственные методы обработки и анализа информации.
Имитационное моделирование, основанное на объектной технологии, предполагает применение трех больших групп методов структурно-содержательного анализа накапливаемых данных: методов формализации и структурирования исходных данных, идентификации объектов и синтеза данных, выборки и частные методы анализа информации.
Тот или иной метод активизируется на соответствующей стадии исследования либо управляющей программой (в соответствии с заданными настройками), либо по прямому указанию пользователя.
Ввод новых данных в имитационную модель - наиболее уязвимый процесс, так как он сопряжен со значительными временными затратами на формализацию и структурирование поступающих данных, а также требует высокой квалификации от оператора, вводящего данные, в частности знаний предметной области и структуры имитационной модели.
Методы формализации и структурирования данных, поступающих на вход системы, призваны уменьшить влияние указанных факторов. Они определяются пользователем на уровне имитационной модели и позволяют обрабатывать исходные данные с различным уровнем автоматизации: от простого перетаскивания мышкой фрагментов неформализованного текста в соответствующие структуры формируемого объекта до их автоматического распознавания в исходном тексте по заданным признакам. Если на входе такого распознавания используется уже накопленный и актуализируемый банк данных, то система приобретает черты обучаемости и ее идентифицирующие возможности напрямую будут зависеть от содержимого банка данных.
Формализованные данные затем обрабатываются методами распознавания объектов и синтеза информации. Это - методы уровня класса, содержащие наборы или правила выделения идентифицирующих признаков, по которым система делает вывод о тождественности объекта, загружаемого в банк данных, одному из объектов, уже хранящихся в нем. Результатом идентификации будет загрузка объекта в банк, отказ в такой загрузке, дополнение объекта с совпадающими идентифицирующими признаками недостающими данными из загружаемого объекта и блокирование загрузки других параметров или выполнение иных действий. Пользователь также должен иметь возможность вручную осуществить привязку загружаемого объекта к объекту, уже имеющемуся в банке данных.
Выборки могут формироваться в терминах языка запросов системы непосредственно либо в экранной форме. На основе выборок пользователь будет просматривать информацию в банке данных с помощью ГИП, создавать документальные отчеты в нужной ему форме или дополнительно обрабатывать данные при помощи одного из частных методов обработки и анализа.
3. Дополнительные возможности по управлению хранением и отображением информации. На этапах хранения информации в банке данных и ее визуализации к имитационной модели предъявляются специфические требования, например, должны быть обеспечены возможности:
- навигации по банку данных в необходимом пользователю временном интервале с визуальным разрывом связей между объектами, актуализированными вне пределов рассматриваемого интервала (при этом в самом банке данных все связи должны сохраняться). Это позволяет просматривать архивные данные с требуемой глубиной выборки;
- графического отображения динамики развития процессов и объектов имитационной модели через дискретные промежутки времени или по мере регистрации изменений;
- автоматического упорядочения в банке данных ссылочных объектов по датам их актуализации;
- администрирования банка данных с целью выявления цепочек разорванных связей (например, появившихся в результате изменения данных), проверки и при необходимости удаления объектов, не имеющих ссылок ни на один объект имитационной модели.
В данной статье приведены не все требования к системам управления имитационными моделями, а лишь наиболее общие из них, сформулированные на основе накопленного опыта разработки и эксплуатации реальной системы.
Телефоны и адреса: Computer Associates - www.cai.com; официальный дистрибьютор Computer Associates “ЦМД-Софт” - (095) 265-6827, http://soft.mcd.ru ; ЗАО Научно-производственная компания “Кронос Информ” - (095) 299-5275, www.cronos.ru.
С автором можно связаться: тел. (095)290-6812, E-malil : smen@mtk.comcor.ru.













