













ОБЗОР
На сегодняшний день наше общение с компьютером сводится к использованию клавиатуры, мыши, монитора и других устройств ввода-вывода. Это стало так естественно, что редко кто задумывается об их альтернативах. Но если вернуться во времена создания первых ЭВМ, то уже тогда разработчики думали о компьютерах, которые могли бы общаться с человеком на его языке.
Человеческий язык при кажущейся простоте и доступности плохо изучен. Еще не создано достаточно хорошей модели его построения, хотя работы в этой области напряженно ведутся. А без построения алгоритма синтеза речи невозможно создание речевых программ. Поэтому “читающие” программы до сих пор не реализованы в полной мере. Для нормального синтеза недостаточно простого чтения слов в предложении, необходим глубокий анализ смысла читаемого текста и, как следствие, правильная расстановка ударений, нужные интонации и темп генерируемой речи. И это лишь видимая часть айсберга.
За долгую историю создания “говорящих” программ было пройдено несколько этапов решения этой задачи.
Первыми появились озвученные словари (самые старые и ограниченные в применении). Такой подход годится только для областей, где достаточно небольшого озвученного набора слов. Примером являются электронные справочные системы, зачитывающие по телефону железнодорожное расписание, а также всем известная служба точного московского времени “100”.
Позже стали появляться программы моделирования работы голосовых связок и ротовой полости человека, использующие хорошо изученные сведения из области физиологии.
И наконец, самая перспективная технология - TTS (Text to Speech), получившая в последнее время широкое распространение.
Реализация этой технологии стимулировала создание новых компактных голосовых продуктов с ранее немыслимыми возможностями.
Технология TTS
Технология TTS, известная на компьютерном рынке уже более 15 лет, обычно используется в приложениях, где необходимо речевое воспроизведение большого числа различных текстов. Основной чертой, выделяющей TTS из голосовых программ, разработанных ранее, является способность произносить слова на основе фонетических правил и заранее озвученного или синтезированного машиной набора звуков. Приближенно процесс синтеза речи можно представить как склеивание по правилам фонетики заранее озвученных фрагментов языка (дифтонгов или более длинных фрагментов) в слова и затем - в предложения. Из этого вытекают достоинства технологии TTS:
- возможность озвучивания любых слов данного языка, как только появившихся в обиходе, так и никогда не существовавших;
- низкие требования к оперативной памяти компьютера, в которой находятся только озвученные фонемы, а не целые словари, как это реализовано в других технологиях синтеза речи;
- более быстрый процесс, поскольку синтез речи проходит скорее, чем поиск в громадной базе заранее озвученных слов (особенно это преимущество проявляется, когда необходимо воспроизвести большое число разнообразных слов);
- простота выделения ударений и интонаций в синтезированных словах;
- возможность изменить темп чтения, не нарушая тембра голоса.
Конечно, это не означает, что технология TTS является окончательным этапом. Например, в автоматизированных системах синтеза речи с использованием ограниченного набора слов более дешевым и качественным (на сегодняшний день!) будет решение, основанное на небольшом озвученном словаре. Но это лишь тенденция ближайшего времени, а позже непременно получат распространение программы, построенные по технологии TTS с внедренными средствами искусственного интеллекта для “понимания” смысла произносимой речи.
Следует учесть, что синтез речи основан на знании многих научных дисциплин: лингвистики, психологии, физиологии человека, компьютерных технологий. Необходим анализ структуры предложения, в результате которого определяется произношение отдельных слов, интонация и оптимальный ритм синтезированной речи (с учетом синтаксиса и семантики). Должны правильно произноситься имена собственные, телефоны, почтовые адреса и другие специфические элементы генерируемого текста, без которых немыслим современный Интернет. Недавно появилась новая разработка - Visual TTS (см. www. research.att.com/projects/tts), заключающаяся в синхронизации генерируемой речи с моделируемой мимикой лица говорящего человека. Реалистичное движение губ позволяет улучшить не только восприятие синтезированной речи, но и разборчивость произносимого.
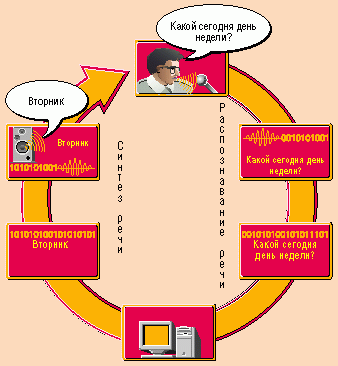
Голосовой интерфейс между человеком и компьютером можно представить в виде замкнутого круга. Процесс начинается с регистрации микрофоном аналоговой звуковой волны, возникающей при звучании человеческой речи. Далее звуковая плата конвертирует ее в цифровой сигнал, который программа распознавания речи преобразует сначала в набор фонем, а затем в слова. Программное приложение анализирует этот текст и вырабатывает на него ответ в виде нового набора слов для синтеза. Теперь программа TTS переводит эти слова в фонемы, а затем, например, методом склеивания звуков и используя другие особенности технологии - в цифровой сигнал. И наконец на последнем этапе круг замыкается: звуковая плата через акустические колонки воспроизводит компьютерную речь, предназначенную для человека.
Готовые решения
По технологии TTS построено уже довольно много приложений. Речевые технологии используются в широком спектре задач: чтение электронной почты, веб-страничек, баз данных, в интеллектуальных бортовых системах или, в идеальном случае, при обучении произношению слов иностранного языка. Но большинство этих приложений строится на основе готовых речевых “движков” таких фирм, как Microsoft, Lucent, Lernout & Hauspie, Unisys, Elan и др. Последовательно расмотрим технологии TTS этих фирм.
Microsoft Corporation (www.microsoft.com/IIT/): Microsoft Text-to-Speech engine. Технология Microsoft Text-to-Speech предназначена для синтеза речи из компьютерных текстовых файлов, возможно, содержащих информацию, полученную механизмами распознавания человеческой речи. Выходной сигнал может быть сгенерирован для двух различных случаев - чтения по телефону (частота дискретизации 8 кГц) или воспроизведения через звуковую плату ПК с частотой дискретизации около
22 кГц. Предусмотрена также возможность сохранения сгенерированной речи в разнообразных звуковых форматах.
Корпорация создала программный интерфейс для работы со звуком - SAPI 4.0 (Speech Application Programming Interface) и дополняет его набором инструментов и утилит для быстрого построения речевых приложений. В него входят функции распознавания речи ASR (Automated Speech Recognition) и технология TTS. В настоящее время идет разработка нового интерфейса SAPI 5.0, являющегося, по заявлениям компании, полностью обновленной версией.
Для разработчиков речевых приложений предложено несколько вариантов SAPI SDK. Наиболее полный из них - SAPI Speech SDK 4.0a Suit - включает подробное описание интерфейсных библиотек SAPI, документацию, примеры исходного кода и приложений, утилиты для тестирования, а также речевой инструментарий Microsoft Speech engines. В архиве этот набор занимает более 39 Мб. Но если отказаться от Microsoft Speech engines, то получится набор SAPI Speech SDK 4.0a, занимающий всего 7,9 Мб и свободно доступный на сайте компании. Этот пакет лишает возможности использовать речь в приложениях, а позволяет только создать программную оболочку управления ею.
В речевой технологии TTS от Microsoft можно выбрать три различных типа голосов: “Майк”, “Мэри” и “Сэм”. Речевой инструментарий поддерживает операционные системы Windows 95, 98, NT 4.0 или 2000, требует наличия звуковой платы, процессора не ниже Pentium, ОЗУ от 16 Мб.
Unisys Corporation (www.unisys.com): Natural Language Speech Assistant. Пакет корпорации Unisys построен по технологии NLU (natural language understanding), позволяющей распознавать и “понимать” человеческую речь, а также вести полноценный диалог с компьютером. Разработан полный набор утилит и тестов для создания речевых приложений. NLSA на ежегодной конференции AVIOS (American Voice Input/Output Society) назван лучшим продуктом 1999 года в номинации Best Industrial/Professional Application.
Очень интересна совместная инициатива Unisys и Microsoft по созданию нового сайта www.speechdepot.com, предназначенного для обеспечения программистов полной информацией, экспертизой и всеми необходимыми средствами для создания речевых программ от самых простых до более сложных. Естественно, сайт предоставляет информацию только по продуктам и новациям этих компаний.
Lucent Technologies (www.lucent.com/speech) представила новую версию LTTS3.1 (Lucent TTS 3.1) многоязычного синтезатора речи по технологии Text to Speech. Разработанный в лаборатории Bell Labs (являющейся собственностью Lucent Technologies), новый многоязычный синтезатор речи поддерживает множество разнообразных языков, в том числе и русский, но особенно хорошо “разговаривает” на английском, испанском, французском и немецком языках. Небольшой размер, и высокое качество синтезатора не могли остаться незамеченными на рынке, и уже несколько компаний, в том числе Intellivoice Communications и Pronexus, объявили о его интеграции в свои продукты. Использовать этот синтезатор можно на любом компьютере, оснащенном процессором Pentium 133 и выше, с операционными системами Windows 9x и NT, Solaris, UnixWare; больших вычислительных мощностей не требуется. А можно приобрести пакет разработчика за $595 и писать свои собственные речевые программы. На сайте Bell Labs есть множество синтезированных примеров, включая песни. При желании можно с заранее выбранным голосом (мужской, женский, детский, или писк комара, если хотите) воспроизвести любой английский текст или получить звуковой файл (реализована поддержка форматов aiff, au и wav) и прослушать его у себя на компьютере в автономном режиме.
Elan Informatique (www.elantts.com/speech/). В отличие от других эта компания предлагает широкий спектр продуктов, использующих технологию TTS: Speech cube, Speech platform, Speech unit, Speech engine, Speech engine for Windows CE, Elan talk embedded. В совокупности они могут читать электронную почту, факсы, веб-страницы, применяются в качестве электронного ассистента в автомобилях, конвертируют текстовые базы данных в голосовые. Поражает количество партнеров Elan Corporation, использующих ее технологию TTS: это такие громкие имена, как Dialogic, Novavox, France Telecom, Dragon System (уже подразделение L&H), BMW, Bosch, OKI и множество других.
Речевой синтезатор Elan поддерживает SAPI 4.0; позволяет воспроизводить синтезированную речь и записывать ее в различных звуковых форматах; включает библиотеку препроцессора e-mail (MIME), примеры кода на Си и Visual C++; осуществляет поддержку всех популярных операционных систем: Windows 9x, 2000, NT, UNIX SCO, UNIX Solaris, Linux; работает с английским, француским, испанским, немецким, русским и португальским языками.
Lernout & Hauspie (L&H, www.lhs.com или www.lhsl.com): RealSpeak. По мнению компании, этот продукт представляет собой “квантовый скачок” в улучшении технологии TTS: речь робота заменяется на речь вполне конкретного человека. Алгоритм конкатенации позволяет компьютеру запоминать человеческую речь и использовать ее для синтеза. Для генерации речи служат не только озвученные человеком слоги, но и его же длинные фонемные предложения. Набор этих голосовых сегментов и применение лингвистических знаний обеспечили интеллектуальность компьютерной речи.
RealSpeak поддерживает американскую версию английского, французский и корейский языки. В ближайшее время планируется добавить поддержку немецкого, испанского, итальянского, голландского, шведского и классического английского языков. А к началу 2001 года этот список пополнят японский и китайский.
Продукт широко используется в приложениях, предназначенных для автомобилей, телевидения, телефонных сетей, бытовой электроники и Интернета.
Алгоритм конкатенации обеспечивает интеллектуальное произношение, основанное на реальных образцах человеческой речи. Создана модель для обеспечения натуральной интонации в предложениях и фразах.
Компания L&H предлагает два функционально различных пакета разработчика для создания голосовых программ под Windows 95 и NT. Это пакет для чтения текстов TTS 3000/M SDK и специальный препроцессор e-mail.
С помощью первого пакета приложения можно создавать на Си/Си++, Visual Basic или в других средах разработки, позволяющих обращаться к функциям TTS3000/M, установленных над Windows 95 и NT. Пакет дает также возможность изменять громкость и ритм речи и тембр голоса говорящего.
Препроцессор e-mail позволяет корректно читать почту в голосовых приложениях, работающих под Windows. Он конвертирует почтовые заголовки, сокращения и аббревиатуры в обыкновенный текст, читаемый описанным выше основным модулем синтеза речи. Например, чтобы прочитать почтовый адрес Erict@lhs.be, распознается имя человека (Eric) и дальнейшие сокращения (lhs и be), и на вход модуля TTS V5 поступает сообщение: Erict at Lernout & Hauspie Speech Products Belgium).
Расположенный в научном парке МГУ Клуб голосовых технологий (web.science.park.ru/pcv/) предлагает “говорящую мышь” - конструктор мультимедийных спектаклей с использованием технологии синтеза речи. С ее помощью можно создавать и редактировать, а затем и проигрывать сценарии различных представлений, уроков, анекдоты или поздравления. Фактически этот продукт позволяет создать домашний компьютерный театр, который осуществляет соединение звуковых, музыкальных, графических и видеоформ. В его состав входят “прочитыватель” русских текстов (английские тексты также могут читаться - по правилам английской грамматики, но с “русским акцентом”), речевой драйвер для Windows 95 (озвучивает навигацию по меню, читает экранные сообщения и выделенные тексты в любых приложениях), интегратор основных мультимедийных файлов с универсальным средством просмотра, расширяемый словарь сокращений и иностранных слов, библиотека мультимедийных файлов и примеры готовых сценариев. “Говорящая мышь” может читать текстовые файлы вслух различными голосами с регулируемыми темпом и высотой, автоматически расставлять ударения, озвучивать клавиатурный ввод, осуществлять чтение двумя голосами в унисон или со сдвигом по частоте; кроме того, она имеет встроенную реверберацию, позволяет редактировать голоса, поет, в том числе под MIDI-аккомпанемент с настройкой голоса на музыкальный инструмент, читает вслух текущую дату и время.
Уже выпущен тираж с новой версией 5.0, в которую добавлены поддержка полноценного чтения на английском языке и возможность сохранять синтезированный голос в виде WAV-файла. Программа занимает весь CD-ROM (около 650 Мб) и требует процессора Pentium 75 и выше, Windows 95 и звуковой платы.
На официальном сайте клуба можно самим вводить любой текст и оценивать качество синтезируемой речи. Причем это доступно как для мужского, так и для недавно разработанного женского голоса.
Конференции по речевым технологиям
Речевым технологиям посвящены многие выставки и конференции.
AVIOS - старейшее общество, занимающееся сбором и распространением информации о речевых технологиях. Ежегодно оно проводит конференции, и со времени своего образования в 1981 году их проведено уже 18. В течение последних трех лет по результатам конференции происходит отбор лучших речевых решений и их публикация на сайте (www.avios.com). В этом году конференция открылась 22 мая и продлилась всего три дня.
Более популярна выставка и конференция SpeechTek (www.speechtek.com), посвященная голосовым технологиям. В последней выставке, проходившей в октябре прошлого года, приняли участие около 60 экспонентов, среди которых были почти все фирмы, рассмотренные нами. Они продемонстрировали достижения в области синтеза (TTS) и автоматического распознавания речи (ASR), связанные с ними проблемы сжатия речи, идентификации говорящего, машинного перевода, а также применение этих технологий в образовании, здравоохранении, банковской деятельности, производстве и т. п. (см. также PC Week/RE, № 43/99, с. 1).
Заключение
Из-за ограниченного объема в обзор не вошли многие интересные решения, в частности, таких известных фирм, как IBM, Philips, Panasonic, Motorola и многих других. Но и по рассмотренным реализациям технологии TTS можно сделать некоторые выводы. Во-первых, технологии фонетического синтеза речи TTS явно доминируют над теми, что использовались раньше, - озвученными словарями и моделями голосовых связок и ротовой полости человека. Во-вторых, бурно развивающийся рынок компьютерной телефонии и сотовой связи подталкивает исследователей к разработке конкурентоспособных речевых продуктов. В-третьих, четко видна тенденция к созданию многоязычных систем синтеза речи.
Конечно, в этой области еще остается множество нерешенных проблем. Очень часто в произносимом программой слове проглатываются буквы. Пока невозможно добиться произношения всех слов, имеющих одинаковое написание, но различающихся ударением: синтезаторы упорно читают только одно из них. Неестественно звучит интонация вопросительных предложений. Но несмотря на все эти недостатки, новые речевые синтезаторы уже можно с большим успехом использовать в различных областях.
В заключение приведу очень интересный ресурс в Интернете - сайт morph.ldc.upenn.edu/ltts/, посвященный сравнению различных систем синтеза речи как в оффлайновом, так и в онлайновом режиме. Он не только предоставляет доступ к десяткам TTS-систем, работающих с различными языками мира, но и позволяет самому пользователю сравнить их в действии.
С автором можно связаться по адресу: DmitriyU@mail.ru.






