













АНАЛИЗ ДАННЫХ
Чистота - залог+ или Мы - заложники+
Продолжение. Начало см. PC Week/RE, № 32/2002, с. 20, № /2002, с. 26.
В предыдущей статье мы остановились на оптимистической ноте: близок восход аналитических технологий реального времени, виртуальных и активных хранилищ данных. Интересно, что такие системы уже нашли практическое применение. Но у профессионала-практика сама мысль о доступе к хранилищу данных из оперативного приложения вызывает улыбку глубокого сочувствия.
Трехуровневая модель обработки информации
Действительно, на пути “реал-тайма” стоят редуты “клинсингов” и “стэйджингов” *1, где информация очищается, согласуется, приводится к необходимому виду. Это как путь по воде от Углича до Москвы - сплошные шлюзы.
_____
*1. Cleansing - процесс очистки данных перед загрузкой в хранилище данных. Staging area - место скопления сухопутных войск перед посадкой на суда или самолеты; в области информационных технологий означает промежуточный технологический буфер, в котором накапливаются данные из различных источников, ожидающие очистки и согласования. После выполнения этих процедур staging area, как правило, очищаются.
Существуют различные стратегии очистки. В одной из крупнейших американских клиринговых компаний правила контроля корректности данных различной степени сложности сгруппированы в несколько уровней. Прежде всего поступающая в систему информация о сделках с ценными бумагами подвергается проверкам, которые требуют минимальных вычислительных ресурсов, - например, проверяется наличие положительных числовых данных в поле “Сумма”. На очередном уровне проверяются права участников на совершение сделки. Каждый последующий уровень все более требователен к ресурсам, но все больше и вероятность того, что эти ресурсы не будут затрачены на обработку некорректных данных.
Для аудита, очистки и согласования данных часто применяются специальные программные средства (см: www.metagenix.com, www.evokesoft.com), позволяющие в автоматическом и полуавтоматическом режиме собирать метаданные из оперативных источников, согласовывать между собой их структуры, выявлять зависимости в “сырых” данных (raw data) *1, генерировать правила качества (quality rules) и контролировать их выполнение.
_____
*1. “Сырыми” принято называть данные на входе в технологический цикл пополнения хранилища данных.
Для обеспечения качества данных активно используется математический аппарат, в том числе статистика. Ральф Кимбелл [2] предлагает использовать нормальное распределение для оценки достоверности информации о продажах, ежедневно поступающей в центр из сотен небольших магазинов. Накапливая для каждого магазина информацию о продажах в различные моменты времени, можно оценить математическое ожидание объема продаж. Известно, что для нормального распределения 99% величин будет лежать в пределах трех средних квадратичных отклонений от математического ожидания. Используя это свойство, можно отбросить слабо изменяющиеся показатели, оставляя в области рассмотрения лишь те из них, которые меняются кардинально. Такие показатели должны дополнительно проверяться.
По мере накопления опыта обработки “сырых” данных и увеличения требований к качеству информации количество буферных зон и сложность алгоритмов проверки может возрастать. В некоторых случаях данные не просто исключаются из рассмотрения, а корректируются с помощью уже имеющейся информации. В компании, которая занимается страхованием коммерческих рисков, от клиентов поступает информация о ежегодных выплатах по страховкам. При контроле анализируются выплаты по годам, и в случае выявления отсутствующих или ошибочных данных они восполняются с помощью ранее полученных фрагментов. Так, если в 2000 г. клиент передал информацию о выплатах 1999-го, а в 2001-м этот блок оказался утраченным, система пытается отыскать в архиве 2000 г. и восполнить недостающие данные.
Среди калейдоскопа используемых технологий и принципов очистки данных, пожалуй, один можно считать универсальным: процессы очистки необходимо располагать как можно ближе к оперативному источнику. Настолько близко, что некоторые методики оценки отдачи от инвестиций (Return On Investment, ROI) рекомендуют относить работы по увеличению качества “сырых” данных на бюджеты оперативных источников.
На практике это не всегда соблюдается. Внесение изменений в оперативные источники в интересах интеллектуальной инфраструктуры (ИИ) является серьезной проблемой для архитекторов хранилищ данных. Если сталкиваются интересы разработчиков оперативной системы и хранилища данных, как правило, приоритет отдается первым. Особенно часто подобная ситуация встречается в банковском секторе, где цена любого сбоя в работе может во много раз превысить стоимость проекта по созданию самой изысканной ИИ. Поэтому там широко распространен язык программирования Кобол.
Но за возможность внесения изменений в оперативные источники приходится платить. Необходимость настройки, выполнения и сопровождения сложных операций очистки и согласования данных значительно повышает стоимость проекта. Эти процедуры снижают оперативность пополнения хранилища данных информацией. Кроме того, если данные корректируются на этапе транспортировки в хранилище, в компании будут сосуществовать, как точно заметили специалисты Teradata, “две версии правды”: одна - в оперативном источнике, другая - в хранилище данных. Такое раздвоение может стать постоянным источником конфликтов и негативно повлиять на культуру компании.
“Чистилище” данных
После прохождения тестов данные попадают в оперативное хранилище (Operation Data Store, ODS) или непосредственно в хранилище данных. Часто ODS используется для построения витрин данных и предоставления информации для оперативного анализа. Но основная его задача - накапливание данных, выстроенных в виде временны/х срезов. Дело в том, что оперативные источники описывают последовательность происходящего. Причем плотность описания во времени крайне неравномерна и зависит от степени важности процесса или его этапов с точки зрения оперативного управления. Кроме того, и детализация отражения процессов во времени в различных оперативных источниках может различаться.
В хранилище же данных деятельность отражена в виде последовательности “мгновенных” снимков, сделанных в различные моменты времени. Такое представление информации отвечает интересам стратегического управления и анализа данных. Поэтому данные при перегрузке в хранилище представляются в виде временны/х срезов.
Формирование “мгновенного” снимка может занимать довольно длительное время. Бил Инмон писал, что в тот момент, когда данные станут полностью согласованными и абсолютно качественными, они уже никому не будут нужны. Выявив данные на этапе проверки, мы тем самым нарушили целостность временно/го слоя. Для его восстановления необходимо ожидать исправления данных в источниках и повторной загрузки. На это порой уходят недели и месяцы. Ведь первичные данные могут собираться по удаленным филиалам, с которыми связь не столь оперативна, и неважно, являются ли средством доставки лошади в степях Калмыкии или вездеходы в Уренгое, главное - мы не получим исправлений в 24 часа, а тем более в реальном времени. Поэтому нужно искать компромисс между оперативностью представления данных и их качеством.
Другая задача, для решения которой используется ODS, - формирование “дельты обновления”. В ODS накапливаются изменения, составляющие разницу между актуальным состоянием хозяйственной системы и тем, которое отражено в хранилище данных. Данные “дельты обновления” лишь дополняют историческую картину хозяйственной деятельности новым “мгновенным” снимком. Такой подход позволяет максимально актуализировать информацию в хранилище данных с минимальными затратами. Однако он требует введения дополнительных идентификаторов слоев в структуры таблиц ODS и оперативных источников, что не всегда возможно.
В заключение разговора об ODS отметим, что оно играет важнейшую роль в приведении данных к единой семантической структуре репозитория и структуре параметров модели предприятия. ODS, как и “чистилище”, открывает данным новые пути применения.
Модель - не имитация, а средство управления
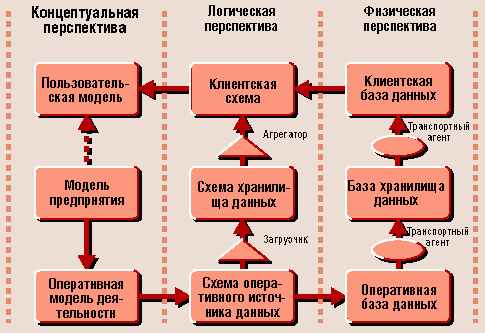
Мы уже вскользь упоминали понятие “модель предприятия”, но не уделяли ему должного внимания. Что же это такое? В работе [3] предлагается рассматривать три перспективы ИИ: концептуальную, логическую и физическую. Концептуальная перспектива наиболее абстрактна и описывается в терминах предметной области. Логическая перспектива отображает концептуальную в терминах реляционной многомерной или какой-либо иной методологии проектирования. Физическая перспектива описывает реализацию соответствующей логической модели в контексте конкретных инструментальных средств.
“Предположим, что аналитик или управляющий хочет иметь какую-то информацию о бизнесе. У него нет возможности получить ее непосредственно. Он должен опираться на собранную и агрегированную информацию. В этом случае мы не застрахованы от того, что информация даст картину, не адекватную происходящему. Компенсировать это можно лишь методически обоснованной системой обработки информации в соответствующих перспективах ИИ - от выборки, очистки и загрузки данных в хранилище вплоть до ее агрегации и доставки до пользователя”. Центром такой концептуально выдержанной ИИ является модель предприятия. “Все прочие модели определяются как ее проекции” [3].
Предлагаются различные методологии построения модели предприятия. В продукте Oracle Financial Services Application (OFSA) компании Oracle, предназначенном для автоматизации банковской деятельности, применяется подход, основанный на двойной записи и принципе сохранения баланса для отражения финансового состояния предприятия.Кубы OFSA соответствуют счетам бухгалтерской Главной книги. Но их многомерная аналитическая структура определяется потребностями пользователей и пополняется непосредственно из оперативных приложений. Таким образом, двойная запись обеспечивает согласованность кубов между собой, а многомерная аналитика отвечает потребностям пользователей. В своей практике наша компания также применяет балансовый подход и для ведения управленческого учета, и для автоматизированной поддержки процессов продаж и снабжения на предприятиях [4, 5].
Специалисты компании SAP при разработке кубов Business Warehouse (BW) в рамках инфраструктуры стратегического управления предприятием (Strategic Enterprise Management, SEM) опирались на структуру ключевых показателей (КП) хорошо знакомой уже многим системы сбалансированных показателей (Balanced Score Card, BSC). Совокупность КП - это также модель, отражающая хозяйственную деятельность предприятия и обеспечивающая управление им. Проектируя структуру кубов с учетом наилучшего способа формирования значения КП, можно добиться максимального качества информации в концептуальной, логической и физической перспективе ИИ.
В этом заключается активная роль модели предприятия, которая обеспечивает поддержку принятия решений и контроля за их исполнением. В заключение заметим, что активная функция модели предприятия ужесточает требования к оперативности информации в хранилищах данных. В работе [6] авторы отмечают, что оперативность сбора информации о значениях КП “играет решающую роль, когда организация пытается поощрить служащих и закрепить положительные тенденции в их поведении”. Медленная обратная связь, по их мнению, может стать причиной отказа от BSC.
С оптимизмом на ситуацию позволяет смотреть то, что, по утверждению Дугласа Хэкни, “уже сегодня мы имеем инструменты и технологии, которые позволяют получить возможности OLTP, ODS и хранилищ данных в единой базе данных” [7]. Но без решения вопросов качества данных, построения оптимальной модели предприятия и единой структуры бизнес-контента эти инструменты лишь утолят наше профессиональное любопытство, а для решения насущных проблем бизнеса окажутся бесполезны.
Литература
1. PC Week/RE, № 32/2002, 33/2002.
2. Ralph Kimball. Is Your Data Correct?. http://www.intelligententerprise.com/001205/webhouse1_1.shtml.
3.Matthias Jarke, Manfred A. Jeusfeld, Cristoph Quix, Panos Vassiliadis. Architecture and Quality in Data Warehouse. http://www.dbnet.ece.ntua.gr/~dwq/publications.html.
4. Аксенов Е. Плох тот менеджер// PC Week/RE, № 3/2001, с. 23.
5. Никитина Н., Гараева Ю., Юдкин Ю. Системы-трансформеры: в поисках оптимальной степени свободы// PC Week/RE, № 19/2002, с. 24.
6. Ши-Джен Кати Хо, Мак-Кей Рут. Два взгляда на сбалансированные показатели. http://www.consulting.ru/main/mgmt/texts/m14/183_cpa.shtml.
7. Hackney D. Data Warehouse Delivery: The Future is Now//DMReview, 2002, December.













