













Эта статья завершает осеннюю серию публикаций о хранилищах данных (см. PC Week/RE, 2002, № , , ). Вместе с автором этого сериала мы побывали на корпоративной фабрике информации, бросили беглый взгляд на системы очистки данных и контроля их корректности, познакомились с уровнями моделирования деятельности предприятия в продуктах SAP BW и Oracle OFSA. А также рассмотрели подход к построению моделей, реализованный в системе “Алеф” компании “Алеф Консалтинг & Софт”. Он интересен тем, что в рамках хранилища данных, как и в OFSA, строятся балансовые модели, которые обеспечивают дополнительный уровень контроля корректности и согласованности данных в хранилищах на уровне модели предприятия (см. PC Week/RE/, 2002, № , ). Это особенно важно в тех случаях, когда накапливаемая информация не согласована в оперативных источниках.

Евгений Аксенов
В последней публикации нынешнего года автор затрагивает вопрос согласования моделей внешнего (по отношению к предприятию) и внутреннего мира. Опять же посредством хранилищ данных.
Внутренний взгляд на внешний мир
Ранее мы рассматривали предприятие как систему сенсоров, непосредственно воспринимающих события во внешней среде. На корпоративной “фабрике” информации сигналы сенсоров считываются, интерпретируются и собираются воедино в хранилище данных. Построенные таким образом модели служат для отражения состояния предприятия во времени. Эксперт в области хранилищ данных Дуглас Хэкни говорил, что в моделях предприятия необходимо обеспечить “одну версию правды”. То есть значение параметров модели предприятия не должно зависеть от того, из какой подсистемы информационной инфраструктуры оно получено.
Кроме того, мы упоминали некоторые модели управления, такие, как EVA и SVA, которые используются для оценки состояния и выработки управляющих воздействий. В [1] эти виды моделей дополняются еще одной - моделью внешней среды. Ведь недостаточно изучать себя и свое мнение о мире. Необходимо пытаться синтезировать взгляд мира на себя и анализировать иные взгляды на мир. Без внешней информации предприятие, как корабль без приборов, без карты и звезд на небе, не может безбоязненно перемещаться в пространстве спроса и предложения. Ведь необходимо обрабатывать информацию о предприятии, публикуемую в СМИ, оценивать емкость новых рынков, прогнозировать последствия смены ассортимента предлагаемой продукции и оказываемых услуг, оценивать эффективность конкурентов и строить профили потенциального клиента.
Но выходя за пределы детерминированных внутренних моделей, мы сразу попадаем во внешний мир, с его стохастичностью и неопределенностью. Специалисты в области информационных технологий высаживаются на берега, где обитают математики и психологи, где у правды много версий и где многое определяется распределениями, мотивами и предпочтениями. Структура моделей, технология обработки информации, подходы к оценке ее качества и требования к хранилищу и презентационному уровню резко изменяются.
Данные о внешнем мире редко бывают согласованны и точны, потому что представляют собой результат статистической обработки больших объемов первичных данных различного качества (информация о владельцах автотранспорта, анкеты опросов и пр.).
Во время моей недавней командировки в США я встретился с Олегом Марголиным, техническим директором компании Global IDs (www.globalids.com), которая помогает клиентам интегрировать глобальные данные с помощью уникальной технологии программ-агентов, собирающих и консолидирующих данные, распределенные по сети.

Олег Марголин, технический
директор компании Global IDs
Вот что он рассказал: “В США есть три бюро, занимающихся накоплением информации о кредитной истории граждан. Эта информация крайне важна для любого американца, так как используется многими структурами, принимающими решение об открытии банковского счета, о выдаче кредита или пластиковой карты. Но когда я заглянул в свое досье, я пришел в ужас: там у меня был неправильный адрес, невозвращенные кредиты, которые на самом деле я вернул пять лет назад, и кредитные карты, давно мною закрытые. Из 100 транзакций 40 были неверны. И чем глубже в историю, тем процент ошибок больше...
Компании, специализирующиеся на поставке информации, не могут передавать детализированные данные о гражданах в силу законодательных ограничений. Они агрегируют их по многим аналитическим признакам - возрасту, маркам автомобилей, месту проживания, среднему доходу. Насколько же точны будут агрегаты, если детализированные данные верны не более чем на 60%?
Различная степень детализации и точности внешней и внутренней информации определяет их различную роль в процессе поддержки принятия решений. Чаще решения строятся на достоверных и детализированных внутренних данных. Внешние же позволяют проверить соответствие гипотез глобальным тенденциям. Их можно также использовать и для формирования гипотез, относящихся к вопросам, не отраженным во внутренней информации (выходы на новые рынки, смена ассортимента)”.
Один из алгоритмов использования внешних данных в маркетинговых целях при прямой рассылке (direct mail) таков: из различных источников приходит информация о населении, производится случайная рассылка корреспонденции по адресам, равномерно распределенным по категориям полученных внешних данных. По результатам рассылки строится модель отклика (response model), определяющая профиль заинтересованного в продукции клиента. Как правило, одновременно строится несколько моделей с использованием различных методов - регрессии, нейронной сети, дерева решений и др. На их основании население делится на несколько групп, наиболее активно реагирующих на первичную рассылку. Эта операция называется скорингом (scoring), так как каждой группе присваивается свой балл: чем активнее группа отреагировала на рассылку, тем он выше. В зависимости от балла определяется и бюджет рекламной кампании по данной группе. После этого проводится сама рекламная кампания и определяется фактическая эффективность рассылки.
“Вы не представляете, сколько почты я выгребаю, - продолжил Олег Марголин. - Это почта от тех компаний, с которыми я уже давно дружу и которые пытаются мне продать то, что я уже давно у них купил. Ясно, что рассылка у них идет по внешней информации - в ней нет меня, а есть демографическая группа, куда меня причислили: в соответствии с их расчетами эта группа должна покупать данный товар. Кроме того, информация может быть годичной давности, когда у меня был другой доход. Сегодня меня уже нет в прежней группе и товар мне нужен другой. В результате информация, некогда представлявшая для меня интерес, сейчас меня только раздражает.
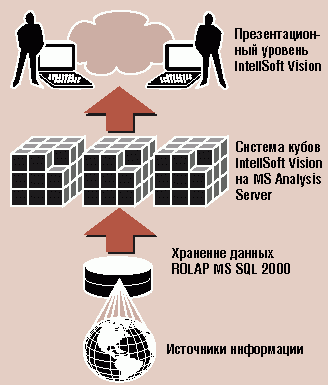
Архитектура платформы IntellSoft Vision
Таким образом, использование внешней информации связано с некоторыми ограничениями.
Во-первых, ограничен уровень достоверности. В отличие от внутренних динамических моделей внешняя информация не может быть согласована в деталях для приложений оперативного уровня.
Во-вторых, распространять информацию в детализированном виде не позволяет законодательство. Поставляются “агрегаты” с выделением различной аналитики, которая может не соответствовать принятой в компании классификации. Потребуется новая интерпретация, как правило, усугубляющая ошибку внешних данных.
В-третьих, необходимым условием получения внешней информации об отраслях и рынках часто является предоставление внутренней информации компании. А это не всегда возможно.
В-четвертых, получаемые данные отражают ситуацию с некоторой задержкой. Ведь информацию мало собрать, ее надо еще обработать и распространить потребителям, у которых могут быть различные требования к ее содержанию и формату представления”.
Прогноз и гнозис
Ожидание может стать активным процессом формирования образа вероятного будущего. Но еще более активно его может формировать позиционная борьба первых лиц компаний отрасли или министров различных министерств. Информация будет вполне соответствовать их требованиям, если их персональные цели и мотивы будут определять выборку данных о внешнем мире, а способ восприятия - влиять на индивидуальный подход к их интерпретации и представлению.

Владимир Розин, глава
компании “Интеллсофт”
По мере увеличения объема внешней информации “правда” - корректность данных в хранилище - становится все более стохастическим понятием. Если же сюда добавить анализ технологии управления крупных компаний и “человеческий фактор”, то она становится, по выражению Владимира Розина, главы компании “Интеллсофт” (www.intellsoft.ru), категорией “интимной”. И дело здесь не в способе представления, а в принципиальном подходе к тому, какими моделями связана разносторонняя и многомерная информация и чем определяется ее согласованность и достоверность.
Стивен Хокинг в замечательной книге “Краткая история времени” [2] приводит световые конусы (light cone), ограниченные скоростью света, как предельные поверхности распространения информации в “пространстве - времени”. О событии, которое произошло на некотором расстоянии от места наблюдения, мы узнаем не ранее чем через время t = S/C, где S - расстояние от места наблюдения до места события, а C - скорость света.
У любого руководителя также существует область предельной информированности, подобная световому конусу Хокинга, являющаяся предметом особой озабоченности и внимания ближайшего окружения. То, что попадает в нее, может оказывать влияние на принимаемые решения. Эта область может быть условно представлена в виде геометрической фигуры, которая определяется характеристиками источников информации, контентом и различными глобальными зависимостями.
Современные системы хранения и представления информации, используемые первыми лицами для принятия решений, должны строиться с учетом структуры области предельной информированности относительно различных тематических разделов. Их задача - “линеаризовать” эту область, сведя к минимуму искажения, возникающие за счет различий в скорости поступления информации. Задача еще более усложнится и приблизится к технологиям нейролингвистического программирования (NLP), если мы будем рассматривать модель взаимодействия нескольких первых лиц.
“Много лет я работал рядом с высшими руководителями, - рассказывает Владимир Розин, - готовил коллегии, оперативки и совещания. Пытаясь формализовать процедуру принятия решений и исследовать поведение первых лиц на совещаниях, я хотел понять, почему на совещании так сложно получить достоверную информацию. Одной из причин оказалось то, что эти люди говорили не о фактическом положении вещей, а о зоне ближайшего развития ситуации, применяя сложные техники аргументирования в позиционной борьбе.
Компьютерные технологии, которые предлагались в то время, значительно отставали от уровня интеллекта первых лиц и не отвечали их потребностям. Я уверен, что ситуация такова и поныне. Научив машину обрабатывать и хранить огромные массивы данных, выдавать на экран тексты, таблицы и графику, мы не научились строить столь сложные модели и представлять информацию так, чтобы можно было “листать” события, мгновенно схватывая их суть. Так, как это происходит на телевизионном экране. Представьте себе, какова была бы аудитория телевидения, если бы вместо просмотра фильма зрителей заставляли передвигать курсором по строкам с описанием сюжетов, действий и изредка предлагали диаграммы и схемы.
Компьютер необходимо научить выделять опасные симптомы, быстро выявлять и привлекать внимание к новым тенденциям, чтобы первое лицо могло быть с ним один на один, задавать ему вопросы и получать разумные и исчерпывающие ответы. Система должна стать информационным произведением, предназначенным для конкретного человека, учитывающим его интеллектуальные особенности, интересы и задачи. Эти принципы мы положили в основу платформы IntellSoft Vision, которую разрабатывает компания «Интеллсофт»”.
Уже сегодня IntellSoft Vision позволяет быстро строить персональные хранилища данных для первых лиц и проблемно-ориентированные системы интерфейсов (в трактовке IntellSoft - “витражи данных”), лаконично представляющих информацию с помощью спектра визуальных техник (“метафор”) и мощных статистических алгоритмов. Концепция развития системы предполагает построение адаптивного интерфейса, нацеленного на интерактивную работу первого лица с компьютером.
Заключение
Мы рассмотрели лишь два случая использования внешних данных: с помощью профиля потенциального клиента и с системой поддержки аргументации высших руководителей. Первый относится скорее к области маркетинга, второй, хотя и условно, - к отношениям с общественностью. Но оба случая должны быть поддержаны соответствующими подсистемами корпоративной фабрики информации (Corporate Information Factory, CIF). В PC Week/RE, № 32/2002 приведена схема CIF, в которой для работы с внешними данными предназначены модули выявления знаний (knowledge discovery), нуждающиеся в собственных хранилищах данных. Билл Инмон, автор концепции CIF, предлагает называть их исследовательскими (exploration warehouse).
Исследовательские хранилища данных позволяют с помощью внешней информации обнаруживать на ранней стадии признаки структурных сдвигов, проводить сравнительный анализ в рамках отрасли и региона, поверять гипотезы и анализировать проекты решений.
Проблема очистки внешних данных исследовательских хранилищ, контроля их качества и достоверности, как видно, не менее актуальна и сложна, чем для хранилищ внутренних данных. Однако здесь необходимы иные методы и подходы, опирающиеся на известные статистические методы.
Но не стоит уповать на статистику там, где есть возможность построить полноценную модель предприятия, согласовав оперативные источники в рамках единой семантики и единых метамоделей процессов.
Статистика, конечно, помогает на основании большого количества данных с ограниченной достоверностью принимать адекватные решения. Но она же подтверждает слова Эрика Сперли [3], что решение не может быть более качественным, чем информация, на основании которой оно принимается. Хотя, к счастью, это и не всегда так.
Литература
1. Баронов В. В. Автоматизация управления предприятием. М., “Инфра”, 2000.
2. Hawking Stephen. A Brief History of Time, New York, “Bantam Books”, 1994.
3. Sperley E. The Enterprise Data Warehouse, Planning, Building and Emplementation. New Jersey, “Prentice Hall”, 1999.













