













УПРАВЛЕНИЕ ЗНАНИЯМИ
Изучая публикации, посвященные обработке документов, легко заметить, что популярный два-три года назад термин "управление знаниями" (knowledge management, KM) сегодня встречается гораздо реже. Тому видятся две основные причины. Первая из них - некоторый ажиотаж вокруг данной темы в те годы явно подогревался маркетинговой активностью поставщиков, которые методом регулярного обновления терминологии пытаются создать у клиентов иллюзию столь же быстрой смены технологий. Вторая носит совершенно объективный характер и имеет, в свою очередь, также два аспекта. С одной стороны, возможности технологий оказались не столь волшебными, как это рисовалось в рассказах их разработчиков, с другой - потребности заказчиков в применении этих средств оказались не очень высокими.
Сейчас не хотелось бы долго обсуждать, что же такое - управление знаниями. Отметим только, что одним из ключевых аспектов этого направления является аналитическая обработка в первую очередь неструктурированной информации (и прежде всего текстов, хотя в перспективе речь может идти также о графике, звуке и видео), в отличие от извлечения данных (data mining), которое традиционно подразумевает работу со структурированной, чаще всего числовой, информацией. Актуальность же данной проблемы определяется тем простым фактом, что сейчас соотношение между информацией, которую можно "читать", и той, что можно "считать", составляет порядка 80:20. Для реального прорыва в области обработки неструктурированных данных требуются инструменты примерно такого же класса, как электронные таблицы для числовой информации.
Одна из основных задач KM заключается в необходимости получения из массива исходной информации сведений, которые нужны для решения конкретной проблемы. Задача эта только в самом простейшем случае может быть сведена к прямому поиску нужных документов по ключевым словам или реквизитам. В качестве примера приведем такой вариант запроса: в каком-либо архиве документов (в частности, в Интернете) определить имя человека, о котором известно, что он в разные периоды времени работал в разных компаниях - N1, N2 и N3. Все выглядит довольно просто, если существует выписка из трудовой книжки, где эти сведения зафиксированы вместе. А если они разбросаны по разным документам? К тому же было бы очень хорошо, если бы аналитический механизм смог сделать качественное различие между содержимым таких фраз: "менеджер Петров уволился из компании N1" (Петров был сотрудником компании) и "жена господина Петрова загляделась на рекламу фирмы N1" (Петров не имеет никакого отношения к N1).
К сожалению, основным методом извлечения знаний сегодня по-прежнему является тот самый поиск, довольно редко с использованием учета морфологии и почти никогда - семантики. Происходит это в первую очередь из-за высокой сложности такой обработки, которая не может быть преодолена только за счет повышения вычислительной мощности компьютеров. Решение подобных задач возможно путем разработки новых математических и лингвистических подходов.
Одно из таких инновационных решений представляет собой набор продуктов Ontos Series, разработанных швейцарской компанией Ontos AG при активном участии росс
Основные идеи
Как и многие другие системы KM, продукты Ontos решают две основные задачи: получение информации из различных гетерогенных источников (базы данных, Internet, поисковые машины, файловые серверы и т. д.) и ее последующая обработка с использованием оригинальных лингвистических алгоритмов.
Продукты Ontos Series |
LightOntos - облегченный вариант, предназначенный для пользователей, которые хотят структурировать информацию на своем индивидуальном ПК и выполнять быстрый поиск нужных данных. Tais (Telecommunication and Automated Information System) Ontos - основной интергрированный продукт для корпоративных клиентов, имеющих дело с информацией, хранимой в разнородных источниках данных, и нуждающихся для анализа в разнообразных средствах визуализации. OntosMiner - собственно инструмент для сбора, классификации и анализа информации, получаемой из различных источников, включая Web-сайты, порталы, базы данных, файловые системы и т. д. |
Отметим, что при всей кажущейся рутинности задачи сбора информации ее решение - дело отнюдь не тривиальное. Осуществить взаимодействие с файлами и базами данных различных форматов как раз достаточно просто. Гораздо сложнее научиться обрабатывать содержимое документов с учетом их форматирования, в частности различая в нем основной текст, заголовки разделов, таблицы и т. д. Чтобы немного представить суть проблемы, можно, например, сохранить HTML-страницу, содержащую несколько фреймов, в виде .txt-файла: найти в нем нужную информацию будет уже совсем не так легко.
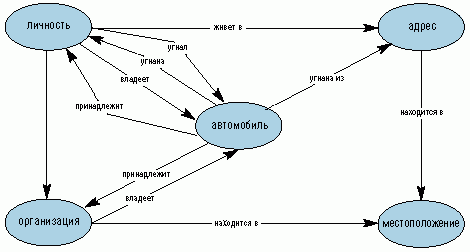
Рис. 1. Доменная модель "Угон автомобиля"
Однако главной изюминкой продуктов Ontos является инновационный механизм OntosMiner*1 аналитической обработки текстов, основу которого составляет патентованная технология, относящаяся к классу NLP (Natural Language Processing - обработка естественного языка).
_____
*1 Сам OntosMiner разработан на основе продукта GATE (General Architecture for Text Engineering, http://gate.ac.uk), который представляет собой SDK, распространяемый бесплатно по лицензии GNU (Open Source) Шеффилдским университетом (Великобритания).
Классическая схема обработки текстов подразумевает несколько последовательных этапов. На первом происходит нормализация слов с учетом морфологии языка. На втором - семантический анализ текста, когда уточняется конкретный смысл слова в зависимости от контекста (в частности, слово "коса" имеет три разных значения, смысл которых можно понять с учетом используемых прилагательных, например "русая", "песчаная" или "острая"). Далее может выполняться семантическая интерпретация с помощью тематических тезаурусов, определяющих сетевые взаимосвязи различных слов (например, "город - столица - Москва - мэр - Лужков - пчеловод - мед - ..."). Затем строится семантический образ исходного документа, на основе которого делаются интеллектуальные запросы на анализ текстов.
В отличие от такой классической схемы обработка документов в OntosMiner изначально осуществляется с учетом конкретной предметной области и возможных вариантов анализа исходных материалов, что приводит к резкому сокращению анализируемых комбинаций слов. Да, при этом теряется универсальность, однако опыт практического применения полнотекстовых баз данных показывает, что основной объем информационных задач связан с выполнением запросов вполне конкретного вида (в конце концов, режимы полнотекстового поиска всегда можно применить к любым документам). Второе важное новшество заключается в том, что между различными словами-существительными выявляются взаимосвязи качественно более высокого уровня, которые обычно описываются глагольными формами (мы это покажем на примере ниже).
Как известно, при решении нечетких математических задач встречаются ошибки 1-го (обнаружение ложной цели) и 2-го (пропуск реальной цели) рода. Подобные ситуации возникают и при обработке текстов, простейший случай - выборка документов, не относящихся к теме запроса, или пропуск нужных документов. При решении этой проблемы в NPL-технологии используется известный медицинский принцип "не навреди". В данном случае ошибки 1-го рода исключаются за счет того, что фрагменты текстов, не поддающиеся смысловой обработке, просто игнорируются. Конечно, такой подход резко повышает вероятность появления ошибки 2-го рода. Но тут следует учесть, что автоматическая обработка подразумевает анализ не одного, а сотен и тысяч документов! Теория вероятности убедительно показывает, что если в одном документе вероятность пропуска цели составляет 50%, то при комплексной обработке уже 10 документов она снижается до 0,1% (т. е. в каждой из 10 попыток проверки гипотезы будет допущена ошибка. - Прим. ред.).
Пример реализации
Привязка технологии к конкретному национальному языку и предметной области осуществляется с применением специальных словарей, построенных на базе модели предметной области, называемой Ontology ("Онтология").
С их помощью выполняется обработка текстов, в результате которой производится формирование образа документов в виде структурированной формы, содержащей объекты и взаимосвязи между ними.
История появления Ontos Series |
История продуктов Ontos Series представляет особый интерес как пример реализации российского научного потенциала в международных start-up проектах. В конце 90-х годов группа швейцарских бизнесменов решила инвестировать средства в перспективную программную разработку. В результате анализа рынка было выбрано направление "управление знаниями" в виде сложной аналитической обработки текстов. Для его реализации и создана компания Ontos AG (www.ontosearch.com). На следующем этапе нужно было определить, что взять в качестве научно-методической основы и кто сможет довести имеющиеся наработки подо реального программного продукта. В ходе изучения предложений зарубежные инвесторы установили контакты с российской компанией Avicomp Services (www.avicomp.ru), уже имевшей опыт создания аналитических систем и десятилетний стаж разработчика ПО и системного интегратора с ориентацией на крупных корпоративных заказчиков. Вскоре после этого было заключено соглашение, по которому Avicomp, с одной стороны, приобрела права на использование технологии Ontos в своих решениях, получив тем самым возможность "интеллектуализировать" собственные продукты и решения, а с другой - передала часть своих разработок для включения в ядро Ontos. Именно Avicomp первой выполнила внедрение технологий Ontos в известном Лётном испытательном институте им. М. М. Громова в подмосковном Жуковском еще в 2001 г. На следующем этапе сотрудничества российская компания предложила швейцарскому партнеру развивать функциональность продуктов в сторону аналитической обработки текстовой информации с использованием технологии NLP. После получения согласия швейцарских партнеров к проекту были привлечены группы ученых-лингвистов из Вычислительного центра Российской Академии наук и DFKI (www.dfki.de). В результате в начале 2003 г. на рынок были выпущены первые продукты Ontos Series, о которых идет речь в этой статье, а Avicomp получила право распространения продукта на территории России и стран СНГ. Летом был реализован первый проект на их основе в МВД Киргизии. |
Наверное, тут стоит подвести черту под изложением общих принципов и показать ее возможности на конкретном примере системы обработки данных по угонам автомобилей, реализованной в МВД Киргизии. Основным и самым массовым документом здесь является рапорт, имеющий примерно такой вид: УГОН Юго-Восточное ОУВД ОВД "Лефортово" 09.10.98 в 17.00 с заявлением обратился Тонких Николай Васильевич, 16.03.80 г/р, не работающий, прож. ул. ш.Энтузиастов, 20"А"-16, о том, что 09.10.98 в 16:45 от д. 20 по ул. ш. Энтузиастов неизвестный совершил угон принадлежащего ему мини-мопеда "Хонда", N рамы 1-1548A-AF18.
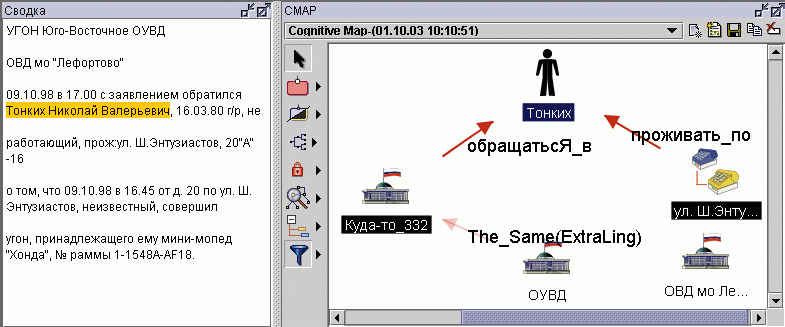
Рис. 2. Исходный текст рапорта и построенная на его основе когнитивная карта
Для анализа рапортов используется модель предметной области "Угон автомобиля" (рис. 1), отражающая основные группы объектов, набор их атрибутов и возможные взаимосвязи между ними. В результате обработки формируется структурированный XML-образ документа, который может отображаться в виде сетевой диаграммы Cognitive Map (когнитивные карты), представленной на рис. 2.
Понятно, что, имея такие формализованные модели, можно достаточно просто выполнять самые различные запросы, определяя, например, наиболее криминальные районы, самые любимые преступниками модели машин или выявляя сложные взаимосвязи между разными персонами (для формирования подобных запросов используются специальные графические инструменты).
Для иллюстрации последнего варианта лучше привести пример обработки документов по купле-продаже, с помощью которых можно выявить, в частности, цепочки сделок, а следовательно, и истинных владельцев тех или иных объектов.
Формирование словарей Ontology
В приведенном примере, использовались документы определенного вида, хотя и заполненные в довольно произвольной форме. На самом же деле в качестве исходных могут выступать самые различные материалы. Но состав и структура извлекаемых данных все равно определяются конкретными словарями типа Ontology, которые являются специфическими для каждой предметной области (точнее, класса решаемых аналитических задач) и сильно зависят от национальных особенностей языка. Откуда же их взять потребителю?
Здесь есть три основных варианта. Первый - использовать готовые "вертикальные" решения. Они формируются разработчиками (специалистами компании Ontos и ее партнеров) для наиболее широких сегментов рынка - на сайте www.ontosearch.com уже есть целый набор словарей для различных сфер деятельности - политика, медицина, финансы, правда, в большинстве своем для английского и немецкого языков (словари поставляются в виде платного сервиса). Второй вариант - заказать создание таких словарей для конкретных целей (именно так был реализован проект в МВД Киргизии). Третий - формировать их собственными силами.
В составе продуктов Ontos Series имеется также набор инструментов для создания и редактирования Ontology-словарей, в том числе с использованием простейших методов самообучения. В ближайших планах Ontos AG - пополнение OntosMiner словарями и правилами французского и испанского языков. Кроме того, ведутся работы по интеграции продуктов Ontos с технологиями ряда ведущих поставщиков порталов.













