













РЕШЕТОЧНЫЕ ВЫЧИСЛЕНИЯ
Часть 1. Психологический фактор сегодня едва ли не важнее технического
Успех к grid-вычислениям пришел чуть ли не мгновенно, но ему предшествовало почти 40 лет подготовительной работы.
Январское представление инфраструктуры WS-Resource, позволяющей управлять grid-ресурсами посредством стандартных протоколов Web-сервисов, стало логическим завершением процесса конвергенции, который начался еще в 1965 г., с появлением первого многопроцессорного компьютера. Путь от него к "решеткам" проложен множеством исследований, посвященных параллельным способам решения экзотических и особо важных задач.

Заключительными же штрихами в общей картине стали сегодняшнее обилие выпускаемых для массового рынка компонентов, постоянно растущая пропускная способность и распространение систем с открытым кодом. Все это вместе взятое обострило вопрос использования grid-вычислений в корпоративной среде, где необходимо связать разнородные компьютерные узлы между собой и с программными средствами самоадминистрирования, причем сделать это так, чтобы превратить их в единую виртуальную систему.
Вот уже несколько лет в обзорах eWeek Labs четко прослеживается тенденция развития ключевых компонентов, приведшая в конце концов к тому, что они вышли на первый план. Решетки уже сейчас считаются одним из самых привлекательных и рентабельных путей построения практически любых комбинаций вычислительных систем с массовым параллелизмом, дискретной прикладной масштабируемостью и отказоусточивостью корпоративного уровня.
Но сегодня на пути grid-вычислений вырастает психологический барьер, преодолеть который гораздо сложнее, чем барьеры технические. Дело в том, что многие ведущие специалисты на предприятиях не считают нужным включать эту технологию в круг своих повседневных задач.
"Конечно, порой приходится решать особые задачи, скажем, рассчитывать специальные эффекты, проводить сложный финансовый анализ рынка, прогнозировать погоду - словом, выполнять то, что раньше было уделом суперкомпьютеров, а теперь стало сферой grid-вычислений. Если же этим заниматься не приходится, кому охота взваливать на себя всю их сложность?" - считает корпоративный партнер eWeek Джордж Абеллас-Мартин, возглавляющий рекламное агентство Arnold Worldwide.
Потребительские вычисления как основа решеточных вычислений
Цены на многопроцессорные серверы сейчас стремительно падают, поэтому Абеллас-Мартин, как и другие администраторы, не торопится тратить деньги на то, чтобы связывать между собой отдельные машины и обеспечивать их скоординированную работу. У менеджеров ИТ возникает резонный вопрос: не лучше ли повысить коэффициент использования вычислительных ресурсов за счет адаптивного распределения рабочей нагрузки между уже развернутыми системами? И расходов меньше, и результат обещает быть более реалистичным.
Тем не менее у grid-вычислений есть одно важное достоинство, на которое просто не могут не обращать внимания даже самые скептически настроенные корпоративные пользователи. Такая технология намного упрощает доставку вычислительных ресурсов в любую точку, где они требуются в данный момент. В результате вычислительный центр предприятия перестает быть лишь хранителем аппаратных средств и начинает выступать в роли поставщика услуг. Ключом же к практической реализации подобных возможностей являются вычислительные решетки. Им и посвящена настоящая статья.
Абеллас-Мартин и его коллеги совершенно правы, говоря, что при решении определенных типов задач просто не обойтись без машин с массовым параллелизмом. А вице-президент фирмы Sun Microsystems по высокопроизводительным и техническим вычислениям Шахин Хан даже назвал такие аспекты изначально предназначенными для распараллеливания. Параллельной он считает саму природу ряда задач, которые "кажутся просто неразрешимыми, пока не сумеешь разложить процесс на одновременно выполняемые потоки".
Наиболее ресурсоемкими сегодня являются проблемы биологии, например свертывание протеинов. Для их решения используются многопроцессорные системы, а их работу, в свою очередь, координируют саморазвертываемые многопроцессные программные средства наподобие созданного в центре суперкомпьютеров г. Сан-Диего пакета Rocks на базе Linux.
В прошлом году специалисты eWeek Labs стали свидетелем того, как группа инженеров прямо в павильоне выставки за считанные часы построила суперкомпьютер мирового класса, работающий под управлением Rocks (статья об этом опубликована по адресу: www.eweek.com/labslink). А это значит, что для создания вычислительной решетки больше не нужно нанимать толпу несчастных старшекурсников и месяцами ждать, когда те наконец-то справятся с заданием. По наблюдениям нашего Тестового центра, теперь не составляет особого труда реализовать подобный проект в разумный срок и с минимальным привлечением людских ресурсов.
Суперкомпьютеры по дешевке
В предыдущие десятилетия для решения сложных задач, требующих распараллеливания, имело полный смысл обзавестись специализированным оборудованием, например суперкомпьютером с векторной обработкой данных. Высокая стоимость разработки, создания и программирования таких систем вполне оправдывалась скоростью, которая давала существенную экономию при эксплуатации.
Сегодня же стимулом для перехода на решеточные вычисления служит не столько стремление любой ценой решить ту или иную проблему, сколько широкое распространение необходимых технологий при одновременном снижении их стоимости.
Отличного соотношения затрат и производительности можно достичь, например, построив решетку на базе серверов-лезвий с несколькими процессорами х86 и дополнив их какой-нибудь операционной системой из семейства Linux. Когда дело касается вычислительных ресурсов, потенциальная экономия вполне может оправдать расходы на упрощение вычислительных платформ за счет создания подходящего корпоративного инструментария. В последнее время на рынке появляется ПО совершенно нового класса, реализованное в виде готовых решений. Одним из примеров такого подхода может служить разработанная корпорацией Oracle технология Real Application Clusters с ее архитектурой Cache Fusion. Другой хороший пример - Global Toolkit. Эта инфраструктура с открытыми кодами сочетает в себе средства отслеживания состояния и инструментарий обнаружения ресурсов.
"За последние три-четыре года произошло слияние целого ряда технологий, - отмечает вице-президент по маркетингу технологий Oracle Боб Шимп. - Широкое распространение серверов-лезвий х86 и богатый выбор рентабельных средств взаимоподключения сейчас очень удачно сопровождается бурным развитием Linux. За два прошедших года данная операционная система стала вполне зрелой. Причем это - не просто недорогая серверная ОС. Она с самого начала не предназначалась специально ни для массовых настольных систем, ни для серверов, поэтому в ней не так уж много слоев. Она очень компактная и быстрая".
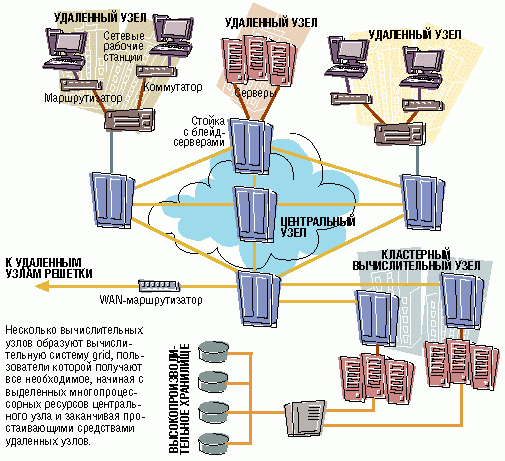
| Из чего состоит grid? |
От суперкомпьютеров, серверных ферм, кластеров и одноранговых систем вычислительные решетки отличаются разнородностью, гибкостью и надежностью. - Распределенное управление. Не столь централизовано, как в кластере, но и не отсутствует полностью, как в одноранговой системе. - Динамичная конфигурация. Машины могут подключаться и отключаться совершенно произвольно. - Адаптивное обнаружение. При решении задач система самостоятельно отыскивает необходимые для этого ресурсы, а не замыкается на жестко заданной конфигурации. - Обеспечение качества обслуживания. Рабочая нагрузка балансируется с учетом приоритетов, а не только по правилам. - Различные требования к пропускной способности. Приложения, которые выполняют интенсивную обработку информации, предъявляют не слишком высокие требования к скорости передачи данных. - Широкий выбор процессоров. Решение различных задач может осуществляться в наиболее пригодных для этого архитектурах, включая векторные процессоры. |
Проникновению вычислительных решеток в корпоративную среду в определенной степени способствуют и их возможности по конвергенции бизнес-данных. Такой потенциал у них весьма высок, ведь эта технология уходит корнями в мир обработки научной информации.
"Ценность данных состоит в содержащейся в них информации, - уверен Хан из Sun Microsystems. - Сотню строк человек еще может просмотреть, две сотни уже нужно представлять в виде графика. Когда же строки исчисляются миллионами, просто невозможно обойтись без средств извлечения из данных информации или их визуализации. А для этого нужны высокопроизводительные вычислительные методы, которые раньше считались чуть ли не экзотикой".
Но ведь именно такие объемы данных сопровождают работу Web-сайтов электронного бизнеса, систем управления отношениями с клиентами и финансовых сервисов высшего звена. И для их обработки волей-неволей приходится прибегать к grid-архитектурам.
Наглядным примером успешного применения компонентов на базе ПК, распараллеленных посредством ПО с открытым кодом, может служить популярный поисковый механизм Google, основу которого составляет более 15 тыс. обычных персональных компьютеров. Об этом говорится в документе IEEE, опубликованном в прошлом году; ознакомиться с ним можно по адресу: www.computer.org/micro/mi2003/m2022.pdf. Программные же компоненты Google рассчитаны на эффективное использование этих вполне доступных "строительных блоков", причем различные запросы здесь обрабатываются на разных процессорах. Более того, благодаря разделению индекса даже один запрос может обслуживаться сразу несколькими процессорами.
Как следует из того же материала IEEE, на средний запрос в Google расходуются десятки миллиардов циклов ЦПУ, необходимых для обработки сотен мегабайт данных. В этих условиях "решеточный" подход дает неоспоримые преимущества. Именно благодаря ему создателям поискового механизма удалось обеспечить наилучшее соотношение цены и производительности. Они не стали копировать былые суперкомпьютеры, которые должны были справляться с максимальной нагрузкой, чего бы это им ни стоило.
Такое отличие является очень важной характеристикой кластерной конфигурации; это особенно стало очевидно после создания кластеров Beowulf на основе ПК, работающих под управлением бесплатного ПО в средах Linux и FreeBSD (www.beowulf.org).
Технология Beowulf, прошедшая тестирование в eWeek Labs несколько лет назад, сегодня получает все большую поддержку. Для нее разрабатывается инструментарий, открываются курсы подготовки, накапливается опыт работы. В целом же все это готовит базу для более амбициозных проектов на основе решеточных вычислений.
Не стоит, впрочем, недооценивать ключевые различия между кластером (наподобие Google или Beowulf) и решеткой. Хотя в обоих случаях и используются доступные "строительные блоки", кластеры имеют четко определенную и обычно однородную конфигурацию, состоящую из идентичных или по крайней мере сходных устройств, работающих под управлением единой системы. У решеток же конфигурация более динамичная и чаще всего разнородная. Используемые здесь ресурсы могут не только очень сильно различаться по характеру и возможностям, но и совершенно неожиданно, безо всякого предупреждения, подключаться и отключаться.
В монографии IBM под названием "Фундаментальные основы grid-вычислений", опубликованной в ноябре 2002 г. по адресу: www.redbooks.ibm.com/redpapers/pdfs/redp3613.pdf , говорится: "Главная цель состоит в том, чтобы создать иллюзию простого и вместе с тем большого, мощного и самоуправляемого виртуального компьютера, который состоит из взаимосвязанных разнородных систем, совместно использующих различные комбинации ресурсов". И дальше: "Стандартизация взаимосвязей между разнородными системами вызвала взрывоподобный рост Интернета. Разработка стандартов по совместному использованию ресурсов в сочетании с расширением пропускной способности сетей обещает столь же крупный эволюционный скачок в решеточных вычислениях".
Чтобы, однако, преодолеть эту ступень, в системе необходимо свести к минимуму централизованное администрирование. Этим решетки в корне отличаются от кластеров и серверных ферм, где нормой является управление из единого центра. Кроме того, применение решетки имеет смысл, если она поддерживает протоколы общего назначения, а не специфичные для конкретной системы, наподобие SETI@home. И наконец, по качеству обслуживания она не должна уступать корпоративным приложениям, обеспечивая, в частности, автоматическую балансировку нагрузки по мере подключения и отключения ресурсов. Системы другого типа, в том числе большинство одноранговых, напротив, стараются заполучить всю доступную производительность, но им все равно не хватает протоколов высокого уровня, чтобы распределять ее между приложениями.
В отношении вычислительных решеток вопрос, отвечает ли эта модель той или иной задаче, выглядит просто некорректным. "Все дело в том, - говорит Хан из Sun Microsystems, - как рассматривать упаковку вычислительных ресурсов с точки зрения ее соответствия задержке и пропускной способности, которые необходимы в каждом конкретном случае". Для решения одних задач, по его словам, важен большой объем разделенной памяти, а это лучше всего обеспечит многопроцессорный сервер с предельно быстрыми взаимосоединениями. В других же случаях, особенно когда на первый план выходит не перемещение данных, а их обработка, лучше подойдет кластер или решетка из недорогих вычислительных узлов, связанных между собой доступными каналами Ethernet.
Современная вычислительная система, как подчеркивает Хан, представляет собой компромисс между двумя требованиями. С одной стороны, она должна обеспечивать оптимальное решение конкретной задачи, а с другой - обладать достаточной гибкостью, чтобы справляться с широким кругом разных задач. Взаимоисключающий подход здесь никого не устроит.
Именно на это сделал акцент председатель совета директоров и исполнительный директор Sun Скотт Мак-Нили, когда мы попросили его дать свои комментарии: "Во главу угла самой идеи сетевых вычислительных систем сейчас ставится их соответствие отраслевым стандартам и открытость интерфейсов. В результате продвижение решеточных вычислений идет семимильными шагами, так как профессионалы ИТ всеми силами стремятся обеспечить серьезную вычислительную мощь путем комбинации недорогих компонентов".
Web-сервисы, как известно, привлекли внимание корпораций тем, что позволяют предоставлять приложения по требованию. Все более стандартизированные способы такой доставки вычислительных ресурсов предлагают и grid-системы. Развиваясь по тому же пути, что и Интернет, который уже стал излюбленной платформой связи между разнородными поставщиками и потребителями данных, основанные на стандартах решетки должны обеспечить систематизированную и отказоустойчивую обработку данных.
Учитывая подобную направленность независимых исследований и стремление корпораций к обеспечению максимальной рентабельности, eWeek Labs берет на себя смелость предсказать: барьеры на пути использования grid для решения различных задач будут постепенно исчезать, а экономические показатели этой модели - становиться привлекательнее.
С редактором Питером Коффи можно связаться по адресу: peter_coffee@ziffdavis.com.
(Окончание следует)













