













КЛАССИФИКАТОРЫ
Количество информационных ресурсов (ИР) и связанных с ними сервисов стремительно умножается. Все труднее разложить ИР по полочкам и пригвоздить к какой-то определенной рубрике выбранного классификатора - ведь и сами классификаторы быстро устаревают и нуждаются в постоянном расширении и непрерывной модификации. Работа по классификации и систематизации информационных ресурсов невероятно сложна и требует усилий со стороны высокоэрудированных специалистов в самых разных предметных областях. Особенно это касается революционно развивающихся дисциплин и технологий - информатики, энергетики, биологии. В традиционных мегахранилищах типа поисковых машин Yandex, Google, Rambler специалисту все труднее отыскать что-либо представляющее собой безусловную ценность. На поисковые процедуры и фильтрацию информации уходит огромное количество времени высокооплачиваемых специалистов.
Нельзя сказать, чтобы в России эти задачи никак не решались. Существует ряд федеральных целевых программ, где данные проблемы поставлены и частично решены. Но всегда ли удачно? Правильно ли выбрана стратегия? Ясно, что основной упор делается не на традиционные библиотечные системы классификации и накопления информации, которые ныне далеко позади прогресса, а на современные электронные хранилища данных, доступные в Интернет-среде. Так, в Министерстве образования и науки РФ принята и реализуется программа ФЦП РЕОИС (Российская единая образовательная информационная среда) на 2002-2005 гг. В ее рамках создана система федеральных образовательных порталов (www.edu.ru), охватывающих все сферы образования, которые предполагается увязать в систему на основе единого рубрикатора информационных ресурсов и сети независимых каталогизаторов информации. По этой сети в порталы будут поступать сведения об образовательных ИР в формате XML-карточек, сформированных по известной метамодели Dubline Core. Казалось бы, прогрессивный подход и стратегически верное решение, но так ли это? Дело в том, что никакая сеть физических каталогизаторов, а тем более автоматических поисковых роботов (краулеров) не способна охватить безграничные Интернет-просторы и собрать все постоянно возникающие и умирающие в этом живом океане ссылки на полезные информационные ресурсы, не говоря уже о том, чтобы подробно описать их и уложить в прокрустово ложе скудного по своему тематическому охвату единого рубрикатора. Кроме того, как ни странно, и сама идея порталов в виде универсального Интернет-интерфейса для доступа к ИР, увы, уже принадлежит прошлому. Почему? Ответ прост: в современном мире постоянно рождающихся и умирающих информационных ресурсов нет никакой пользы предоставлять доступ к ним через HTML. Ссылка на ресурс и связанный с ним сервис может быть представлена в виде URL, однако это вовсе не означает, что доступ по этой ссылке должен обязательно осуществляться через портал. Важно найти, получить ссылку и связанные с ней описания. Но для этого существуют современные перспективные технологии и прежде всего XML-хранилища, IMS/ LOM-описания и UDDI-реестры. Думается, что в будущем все сведения о ресурсах будут представлены именно в сети UDDI-реестров - корпоративных, отраслевых, федеральных, региональных, специализированных, тематических, да каких угодно! Вопрос не в том, существуют ли необходимые для этого технологии, - вопрос в том, кто, как и в каких целях сумеет их применить.
Преимущества UDDI для хранения сведений об информационных ресурсах совершенно очевидны:
- UDDI представляет собой Интернет-базу данных со структурой, строго определенной по стандарту UDDI;
- имеется стандартный API для доступа к UDDI-реестру из любого языка программирования в любой операционной среде;
- поддержка UDDI-серверов уже встраивается в операционные системы (например, в Windows 2003);
- почти в любой современной IDE (MS Visual Studio, Eclipse и т.д.) имеются встроенные средства для публикации сведений о программе, сервисе в публичном или приватном UDDI-реестре;
- UDDI может работать практически с любыми из имеющихся систем классификации информации и позволяет импортировать и экспортировать в свою базу имеющиеся тематические структуры;
- UDDI-серверы и базы данных, созданные в различных местах различными производителями, способны реплицировать между собой информацию;
- в UDDI-реестре можно накапливать не только сведения и ссылки об имеющихся информационных ресурсах, но и обо всех связанных с ними сервисах;
- UDDI включает средства поддержки таксономии и статистики об использовании информационных ресурсов, и поэтому на данной основе легко реализовать платежные системы для особо ценных ресурсов;
- любая UDDI-реализация (MS UDDI SDK, IBM WebSphere UDDI, Systinet WASP UDDI Server) включает удобные средства Интернет-навигации по своему хранилищу информации в соответствии с выбранной системой классификации и полнотекстовый поиск.
Таким образом, в современных условиях нет никакой необходимости создавать специализированные и тематически организованные порталы только для того, чтобы хранить и накапливать в одном месте сведения о вновь возникающих и постоянно умирающих ИР. Справиться с этой задачей в одиночку не сможет никакая организация, сколь бы мощной она ни была. В настоящее время представляется безрассудной идея тотальной централизации и обязательной регистрации информационных ресурсов, какие бы директивы при этом ни издавались. Только децентрализация и сквозные взаимодействия на основе общепринятых мировых стандартов (XML, SOAP, Web-Services, WSDL, UDDI) способны привести к успеху при создании удобных и повсеместно доступных систем хранения каталогизированной информации.
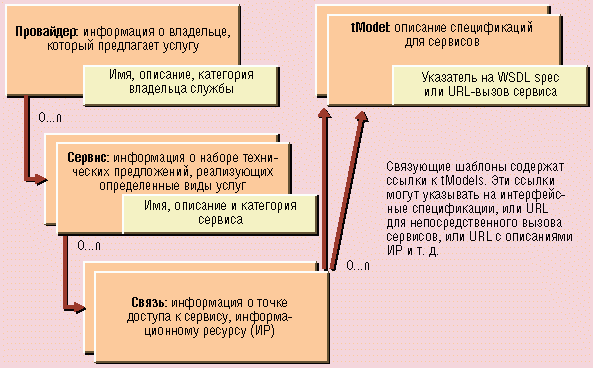
При этом хотелось бы сказать еще несколько слов о способах подготовки и хранения информации. Ясно, что главным действующим лицом в мире информации является создатель текста. Под текстом понимается любая интеллектуальная продукция, имеющая свою форму выражения и способная быть зафиксированной в компьютерном мире. После того как информация зафиксирована (файл), она должна быть опубликована (URL), зарегистрирована (библиографическая XML-карточка), каталогизирована (один из публичных UDDI-реестров). Иными словами, чтобы стать видимой для мира и обрести свою родовую принадлежность, информация проходит четыре стадии обработки:
- фиксация и сохранение (файл);
- публикация (Web-сайт);
- регистрация (XML-описание в XML-репозитории);
- каталогизация (набор записей в UDDI-реестре).
Ясно, что на каждой стадии используются различные рабочие инструменты. На первой стадии это могут быть, например, сканер, Web-камера, персональный компьютер; на второй - браузер, доступ к Web-сайту и средства создания HTML-странички, на третьей и четвертой - некие программные процедуры. Если относительно первых двух стадий не возникает вопросов, то третья и четвертая обычно воспринимаются как лишние, факультативные, к тому же связанные с некоторой дополнительной нагрузкой, однако это не так. Если бы после соответствующего оформления информации создатель воспринимал ее как некий отчуждаемый продукт, имеющий свою товарную стоимость, то две последние стадии в его представлении были бы совершенно неизбежными. В будущем к этому все, вероятно, и придет. Процедура регистрации просто маркирует продукт в соответствии с принятой системой описания и обозначения (Dublin Core, IMS/LOM): автор, дата создания, краткое описание, цена и т.д. Процедура каталогизации вводит продукт в действующую систему пользования, т.е. на полку библиотеки или в каталог магазина - это и есть по сути глобальное назначение UDDI. При этом автоматически разрешаются все проблемы авторских прав. В настоящее время ощущается недостаток именно таких систем, особенно создания систем хранилищ XML-карточек ИР, ориентированных на определенные стандарты метаописаний, такие, как IMS, GILS, MARC, Dublin Core. Немаловажно также создание сети государственных и негосударственных, частных, общественных, корпоративных и иных UDDI-реестров различной тематической направленности. Ясно, что в дальнейшем при неизбежном лавинообразном росте информационных ресурсов хранить всю информацию, все ссылки, все описания, а тем более систематизировать и классифицировать их в одной-двух мегамашинах поиска станет попросту невозможно.













