













ПРОЕКТЫ
Решение современных аналитических задач все чаще связано с обработкой огромных объемов информации, извлекаемой из различных источников данных. И проблема заключается не только в обеспечении физического доступа к разным каналам получения информации или формирования единого хранилища, гораздо сложнее решить задачи нормализации содержимого баз данных и привести его к некоторому единому каноническому виду, без чего существенно затруднен анализ этих данных.
Суть вопроса можно проиллюстрировать на примере работы Федеральной службы по финансовому мониторингу (Росфинмониторинг), на которую возложена реализация положений российского законодательства о противодействии легализации доходов, полученных преступным путем, и финансированию терроризма. Для этой цели Росфинмониторинг постоянно ведет анализ информации о финансовых операциях юридических и физических лиц. Эти сведения поступают от подотчетных организаций (в частности, от банков) в электронном виде, причем, несмотря на использование унифицированных форм отчетности, нередко получаемая информация оказывается неполной и недостаточно структурированной. Понятно, что все это усложняет анализ, который должны выполнять специалисты Федеральной службы.
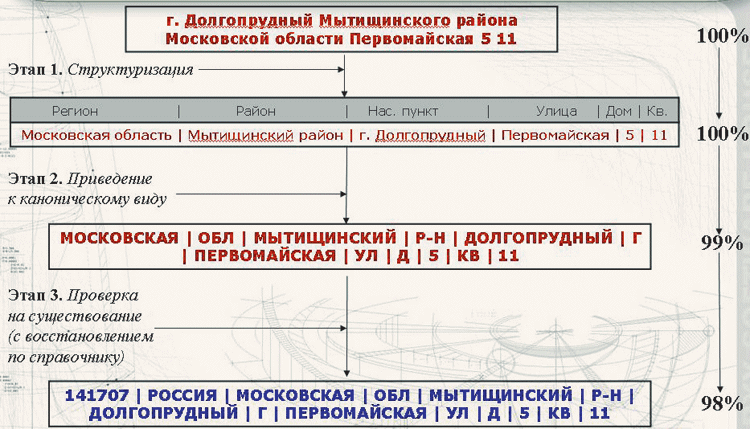
Процесс нормализации адреса (справа - процент достоверности выполняемых преобразований)
В качестве самой простой иллюстрации можно привести пример заполнения поля адреса физического или юридического лица, который может выглядеть так:
М.О. Долгопрудный ул Первомайская 5 11
Или так:
г. Долгопрудный Мытищинского района Московской области Первомайская 5 11
Возможны и другие варианты.
Актуальность проблемы легко понять, если учесть, что это относится к десяткам полей в получаемых документах (названия организаций, описание операций, имена людей, дата их рождения и т. д.), а объем ежедневно поступающих в базу данных исчисляется миллионами полей. Очевидно, что решение подобных задач возможно только с помощью технологий автоматической нормализации и идентификации данных. Реализация проекта по подготовке и верификации данных для Росфинмониторинга была выполнена специалистами компании ABBYY, которая давно известна своими разработками в области интеллектуальной аналитики. И тем не менее для достижения поставленных целей разработчикам ABBYY пришлось решить целый ряд сложных исследовательских задач.
В результате были созданы три набора API-интерфейсов, обеспечивающие нормализацию исходных данных, идентификацию их с уже имеющимися в БД записями, а также поиск по базе данных. Кроме того, был создан "Автономный инструмент аналитика" (АИА), предназначенный для иллюстрации функций разработанных модулей. Для повышения качества нормализации данных задействовано более 60 словарей и справочников.
Каждый набор API представляет собой гибкий инструментарий с различными возможностями настройки, что достигается благодаря применению двухкомпонентной структуры: программный модуль состоит из технологического ядра ("движка") и блока структурных описаний в формате XML. Соответствующим образом изменяя структурные описания, можно детально настроить библиотеки на сколь угодно сложную процедуру обработки данных.
Применение этих средств позволяет автоматизировать процесс нормализации, состоящий из следующих взаимосвязанных этапов (см. рисунок):
- структуризация данных: разбиение входных данных на независимые составляющие путем выявления сокращений, вводных слов, разделителей и пр., а также посредством проверки слов исходной строки по справочникам;
- приведение всех составляющих входной структурированной строки к нормальному виду, заданному в справочниках;
- проверка полученного нормализованного значения на существование по заданному справочнику;
- проведение вероятностной оценки качества выполненной нормализации при осуществлении всех этапов данной процедуры.
По словам Юрия Гребенщикова, начальника информационно-технологического управления Росфинмониторинга, внедрение созданных ABBYY инструментов обработки данных позволит добиться серьезной экономии времени и ресурсов и значительно снизить трудозатраты. Согласно результатам полномасштабного тестирования, проведенного на финальной стадии проекта, время обработки массива данных объемом свыше 1 млн. информационных полей не превышает 6 ч.













