













КОНТАКТ-ЦЕНТРЫ
Распознавание речи как бизнес-решение
В состав практически любого ПО для работы контакт-центра, представленного на рынке, сегодня входит инструментарий для создания IVR-меню. В свое время подобный софт, который позволял снять с операторов часть нагрузки, введя режим голосового "самообслуживания" за счет последовательного нажатия телефонных клавиш, казался крайне удачной интерактивной технологией. После того как IVR получила широкое распространение и стала встречаться в контакт-центрах большинства мало-мальски крупных компаний, оказалось, что, несмотря на сокращение времени ожидания звонящим, это решение нельзя назвать панацеей.
Внимая собеседнику
Практика использования IVR-решения выявила целый ряд проблем. Клиент отказывался слушать фоновую мелодию больше минуты-другой в ожидании ответа системы, не хотел тратить время и на прослушивание автоответчика, добираясь до нужной функции (например, перехода на другой тариф или пополнения баланса) через многоуровневое разветвленное меню. Довольно часто звонящий в таких случаях выбирает из двух зол меньшее и сразу переводит вызов на оператора. Как следствие, IVR становится неэффективным, а средняя стоимость обработки вызова возрастает. Так что вполне можно было ожидать, что технологический прогресс в этой сфере на IVR не остановится и в скором времени вендоры контакт-центров предложат более совершенные решения по обработке вызовов.
Наиболее вероятные преемники IVR - средства распознавания речи, которые позволяют системе вычленить в репликах дозвонившегося ключевые фразы и в соответствии с настроенными алгоритмами предпринять необходимые действия. Разумеется, подобные решения не могут на начальном этапе своего развития полностью заменить оператора (да и не факт, что такая интеллектуальность будет когда-либо достигнута), но возможность распознавания типичных запросов, составляющих львиную долю обращений в контакт-центр, позволяет резко сократить нагрузку на сотрудников. Распознавание речи и преобразование текста в речь (TTS, text-to-speech) является одной из ключевых составляющих концепции универсальной обработки сообщений (Unifies Messaging, UM), которую сейчас рассматривают в качестве стратегического вектора развития практически все ведущие поставщики оборудования и ПО контакт-центров.
Работу над программным инструментарием распознавания речи ведут несколько компаний, но до технологического уровня, достаточного для коммерческой эксплуатации (т. е. около 2% ложных срабатываний, которые можно нивелировать конфигурированием системы), пока доведено не так много решений. В частности, среди преуспевших в деле распознавания и синтезе человеческой речи можно отметить компании Nuance (использует наработки купленной ScanSoft) и IBM (WebSphere Voice Server), чьи технологии уже начали лицензировать вендоры контакт-центров. Разработки IBM позволяют проводить распознавание и синтез речи, а решение ScanSoft, кроме того, также поддерживает идентификацию голоса и диалоговые элементы Open Speech. Конечные решения на базе подобных технологий уже являются флагманами новых продуктовых линеек у лидеров рынка - Avaya, Cisco, Nortel, Siemens и др.
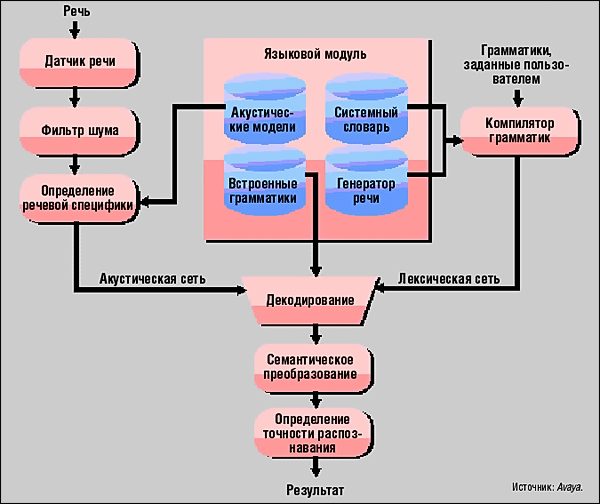
Рис. 1. Архитектура OSR
Несмотря на все преимущества систем речевого самообслуживания, очевидно, что многие потенциальные заказчики не готовы кардинально менять уже имеющуюся инфраструктуру в силу финансовых затрат и потенциальных технических проблем при развертывании новых решений. Поэтому вендорам приходится обеспечивать совместимость со своими ранними линейками продукции и разрабатывать механизмы внедрения новых сервисов на основе уже существующей технологической базы. В результате такого технологического симбиоза появляются новые возможности как на этапе обслуживания вызовов, так и при их маршрутизации. Наиболее часто приводимый пример - оценка целесообразности перевода клиента из системы самообслуживания на оператора. Определение происходит в результате анализа клиентского набора параметров: категории клиента, данных по его транзакциям и ценности для компании, персональных предпочтений, истории предыдущих обращений и т. д.
В качестве еще одной особенности новых продуктов можно отметить их частую интеграцию в составе единого решения с приложениями IP-инфраструктуры - другого приоритетного направления разработок вендоров. Использование открытых промышленных стандартов, лежащих в основе построения IP-сетей, таких как VoiceXML или MRCP, делает системы речевого самообслуживания более гибкими и масштабируемыми за счет отделения прикладной части от аппаратной платформы. Кроме того, этот подход дает ряд других преимуществ. Так, стандарт VoiceXML позволяет осуществлять доступ к одним и тем же сервисам и БД и по голосовой связи, и через Интернет, что резко упрощает базовую ИТ-инфраструктуру контакт-центра, параллельно расширяя потенциал развития сервисов. В качестве еще одного достоинства открытых стандартов следует отметить возможность интеграции систем с платформами от других разработчиков, т. е. отсутствие привязки к конкретному вендору.
| Стандарты систем распознавания речи VoiceXML Язык VoiceXML предназначен для разработки Web-ориентированных голосовых сервисов, прежде всего для контакт-центров на базе IP. Стандарт был разработан семь лет назад специалистами группы VoiceXML Forum, включавшей 44 корпорации из телеком-отрасли. В настоящее время совершенствованием технологии занимается консорциум W3C. Для сертифицирования продуктов на соответствие стандарту вендоры привлекают независимых аудиторов. Главным достоинством языка является независимость сервисных приложений от платформ в IP-телефонии. Область применения языка очень широка. В частности, ряд интернет-компаний даже использует сервисы на базе VoiceXML для подтверждения заказов и идентификации клиентов по голосу. В декабре 2005 г. W3C объявил о завершении работ над третьей версией VoiceXML. В ней предусматривается расширение функциональных возможностей языка Speech Synthesis Markup Language (SSML), позволяющего управлять синтезированной речью с помощью множества параметров (от высоты звука до произношения), на ряд новых языков, в том числе китайский, японский и корейский. В OSR пока применяется VoiceXML 2.0, который позволяет упростить развертывание дополнительных приложений на базе стандарта. Однако продукт также может быть использован на платформах, не поддерживающих язык, поскольку решение непосредственно не интерпретирует VoiceXML и содержит в своем составе VoiceXML-браузер. MRCP Универсальный прикладной протокол для управления медиаресурсами - MRCP (Media Resource Control Protocol) был разработан для предоставления голосовым приложениям в VoIP-сетях доступа к службам медиасерверов через интерфейс API. В ноябре 2005 г. появилась вторая версия протокола, которая обеспечивала доступ службам распознавания голоса, синтеза речи и проверки подлинности голоса. MRCP базируется на Web-технологиях и может комбинироваться с другими медиапротоколами, например RTSP, для передачи аудио- и видеопотоков в реальном времени. MRCP, так же как и VoiceXML, направлен на сокращение издержек и временных затрат при модернизации систем или развертывании новых приложений, а также независимость сервисов от выбранной платформы и ее производителя. Кроме того, медиасервер на MRCP позволяет параллельно эксплуатировать и по выбору использовать продукты разных производителей. SRGC Наряду с VoiceXML, W3C три года назад присвоил статус "рекомендуемой" спецификации SRGC (Speech Recognition Grammar Specification). Если VoiceXML представляет собой язык описания интерактивных голосовых Web-служб для синтеза, записи и распознавания речи, а также голосовых и DTMF-команд, то SRGS стандартизирует способы указания слов и шаблонов, на которые ориентируются системы распознавания. В настоящее время VoiceXML и SRGC подразумевают совместное использование и являются компонентами Speech Interface Framework, универсального набора языков разметки для интерактивных речевых приложений. SRGS позволяет описывать сопоставления результатов распознавания речи или тонового сигнала телефона действиям пользователя. |
И все же основной побудительный мотив для развертывания систем речевого самообслуживания состоит в том, что они не требуют расширения штата операторов при наращивании объема услуг. Да и при сохранении текущего объема работы ROI получается весьма внушительным. Например, стоимость обработки оператором одного обращения в службу технической поддержки составляет от 3 до 7 долл. При обслуживании соответствующей системы сумма сокращается до 1-2 долл. без снижения качества обслуживания и лояльности клиентов. При этом функциональность решений постоянно растет, и современные приложения на базе распознавания речи позволяют в автоматическом режиме ответить не только на сравнительно простые клиентские запросы, например о проверке состояния заказов или местонахождении компании, но и более сложные, такие как смена адреса клиента или изменение пользовательского пароля.
Функциональность
Первые образцы систем уже доступны отечественным заказчикам. В частности, недавно компания Avaya объявила о локализации своего решения Open Speech Recognizer (OSR) и начале его продвижения в России. В основе продукта лежат технологии распознавания ScanSoft, которые уже применяются более чем тысячей компаний по всему миру. Ниже на примере этого решения будут рассмотрены принципы работы, а также техническая и бизнес-функциональность подобных систем. Заявленная разработчиками точность распознавания речи в OSR составляет 98% правильных ответов для англоязычных запросов (понятно, что по русскоязычным пока статистики нет). Помимо этого показателя системы также характеризуются величиной относительного сокращения ошибок (Relative Error Rate Reduction, RERR) в результате самообучения, которая у данного продукта достигает 15-20% ежегодно.
Среди основных свойств OSR (см. рис.1) можно отметить определение начала и конца реплики собеседника, умение отличать паузы от завершения фразы, реакцию на перебивание собеседником голосового сообщения системы, отсеивание посторонних шумов, своевременную подачу ответной реплики (так называемый живой отклик, responsiveness) и анализ речи произвольного содержания (естественный язык, natural language). Кроме того, в OSR поддерживается распознавание многоязычной речи, что разработчики считают существенным достоинством, утверждая, что, например, в Северной Америке клиенты зачастую перемежают свою английскую речь французскими или испанскими словами.
Распознавание перебивания (barge-in) на практике обычно необходимо для того, чтобы звонящий мог остановить перечисление системой возможных действий, услышав то, что ему необходимо. Выглядит это примерно следующим образом.
Система: Вас приветствует справочная служба авиакомпании Х. Вы можете узнать расписание рейсов, заказать билет, изменить...
Клиент: Заказать билет.
Получив команду, система сразу переходит к меню резервирования, прервав свою реплику. В рассматриваемом продукте поддерживаются и такие возможности, как распознавание реплик, обращенных к службе при параллельном разговоре собеседника по телефону и еще с кем-либо лично. То есть система прервет свой разговор и примет команду только в том случае, если по результатам анализа ключевых слов в брошенной клиентом фразе выяснит, что данный речевой фрагмент предназначался ей. Разумеется, точность оценки и соответственно уровень удовлетворения звонящего во многом зависит не только от технологических возможностей продукта, но и от качества составленного специалистами компании тезауруса нужных фраз.
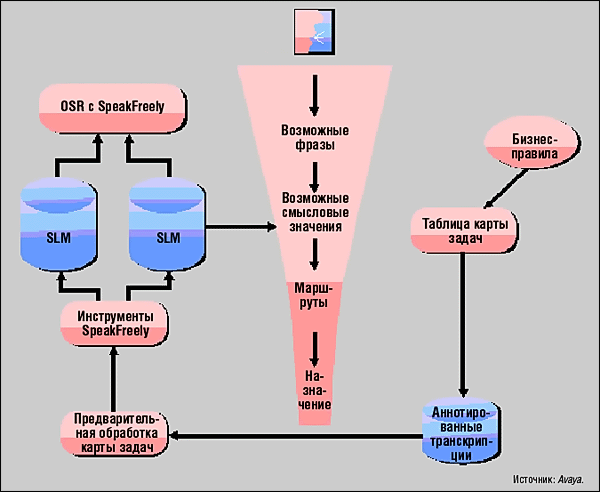
Рис. 2. Схема работы SpeakFreely
Умение отличать речь от посторонних звуков также немаловажно для эффективной работы системы, причем с каждым годом этот фактор становится все более и более актуальным по мере увеличения количества вызовов с беспроводных телефонов и, как правило, из более шумных мест, например с улицы. Помимо программных алгоритмов отсева не относящихся к беседе звуков в OSR используются фильтры, основанные на спектральном вычитании. Данные устройства определяют общий уровень шума (в частности, создаваемого проезжающими машинами) "в трубке" и вычитают его из общего сигнала, оставляя сравнительно чистую речь.
Качество реализации "живого отклика" - следующий по значимости параметр после точности распознавания, так как удовлетворенность клиента во многом зависит именно от него. По окончании фразы собеседника система выжидает около двух секунд (CPL, caller perceived latency), чтобы убедиться, что тот действительно прекратил речь, распознать и проанализировать поступившие данные, после чего исполняет команду и сообщает подходящий ответ. Как утверждают в Avaya, и большая задержка (более двух секунд), и слишком быстрая реакция вызывают психологический дискомфорт у клиента.
Лингвистические технологии
Поддержка естественного языка позволяет существенно расширить функциональность системы, так как дает возможность внедрять более сложные сервисы. К таковым, например, относится обращение пользователя в службу технической поддержки с описанием возникшей проблемы. Без естественного языка для реализации этого функционала необходимо создать крайне разветвленное голосовое меню, через которое система будет пошагово сужать круг предполагаемых неполадок. В силу корпоративной специфики пользовательские проблемы могут быть самыми разнообразными, и зачастую сделать соответствующее меню просто не удается. В то же время с использованием естественного языка система может анализировать описание клиента, сделанное в произвольной форме, вычленяя ключевые слова и задавая наводящие вопросы по возникающим предположениям. Таким образом, вместо многочисленных уточнений в меню пользователь ведет менее утомительные разветвленные диалоги.
В OSR эта функциональность реализована в модуле SpeakFreely с задействованием статистических моделей - лингвистических и семантических (SLM и SSM соответственно). Система определяет вероятность той или иной проблемы у звонящего в ходе диалога с постепенным повышением точности прогноза по мере приобретения опыта. Процесс обработки данных отображен на рис. 2.
Кроме того, в OSR можно задать правила для выделения семантически значимых фраз при распознавании, которые позволяют улавливать смысл речи, не прописывая в словаре все возможные словесные формы. Например, система поймет просьбу клиента об изменении своего адреса в базе, озвученную произвольными словами, а не четкой формулировкой.
Говоря об обучаемости OSR, необходимо отметить также реализованную в продукте запатентованную технологию LEARN, позволяющую приспособить акустические модели к типичным рабочим условиям: стандартный уровень шума, диалект большинства клиентов и т. д. - без вмешательства операторов. В частности, в Avaya утверждают, что использование LEARN в работе одного из австралийских телекомов позволило довести RERR до 24,7%.
Среди используемых в OSR лингвистических решений можно выделить несколько перспективных технологий, позволяющих ускорить процессы преобразования текста в речь и обратно, а также их анализа. Прежде всего это относится к FST (Finite State Transducer) - конечному преобразователю текста. После того как речь переводится в текст, написанный на естественном языке, нужно построить над ним соответствующую структуру, создать семантическую сеть, отражающую смысл текста. Выглядит это следующим образом. По ключевым словам формируется определенная первичная структура с кусками текста в качестве базовых элементов. Если для понимания смысла ее на этом уровне недостаточно, над начальной структурой "возводится" следующая и т. д. - пока не будет достигнут необходимый порог.
| Оптимизация и оценка эффективности Главную сложность при настройке систем распознавания речи представляет разработка мер по предупреждению возможных ошибок и адекватная установка порогов "неправильности". Каким бы совершенным ни был речевой движок, программа может не понять (или понять неправильно) какие-то слова, а также пропустить значимое слово в фразе. Наиболее результативным способом профилактики можно назвать изменение произносимого системой текста при переспросе. То есть если приложение не смогло с первого раза понять ответ клиента, например из-за сильных помех по линии, то она должна задать тот же вопрос, но другими словами. Это существенно способствует сокращению переводов звонков на "живых" операторов по инициативе клиента. Можно привести два примера диалогов для стандартной и оптимизированной настройки соответственно. Система: Назовите ваш адрес. Клиент: Рязанский проспект, дом 8. Система (не распознав ответ): Назовите ваш адрес. В этом случае клиент может посчитать, что система не работает, и перейти на оператора, а то и вообще бросить трубку. Однако ситуация меняется, если построить диалог другим образом. Система: Назовите ваш адрес. Клиент: Рязанский проспект, дом 8. Система (не распознав ответ): Простите, вас плохо слышно. Пожалуйста, говорите громче. Назовите ваш адрес. Теперь клиент понимает, что его вызов принят, и к тому же он получил рекомендации для более корректной работы с системой. При этом ПО для распознавания речи работает не по бинарному принципу понятно/непонятно. Вместо этого используется процентная шкала, характеризующая степень распознавания на каждом этапе диалога. И каждый последующий шаг системы зависит от полученного на предыдущем этапе значения. От пользователя требуется установить значения нескольких порогов. То есть если уровень "понимания" собеседника близок к 100%, то система продолжает вести диалог, а на каких-то промежуточных уровнях просит подтвердить или уточнить тот или иной момент в разговоре. В качестве количественных показателей эффективности системы рассматривают помимо количества обработанных звонков уровня распознаваемости и упомянутого в основном тексте RERR (для обучаемых систем) ряд других параметров. Во-первых, это степень риска - отношение количества клиентов, выбравших разговор с системой вместо оператора, к общему числу позвонивших в компанию. Во-вторых, это уровень отказа от общения - количество прерванных звонков. В-третьих, это средняя продолжительность звонка, которая после внедрения системы должна сократиться. |
При этом для построения структуры текста необходимо выбрать какой-нибудь способ ее описания. Для этого используются так называемые формализмы, задающие соответствие между отрезками текста и смысловыми объектами. В компьютерной лингвистике существует целая классификация формализмов, в том числе порождающие грамматики, расширенные сети переходов (ATN, Augmented Transition Networks), формализмы, основанные на шаблонах, и, наконец, FST. За счет конечных преобразователей OSR может работать с очень большими грамматиками (набором допустимых словоформ), включающими более 1 млн. слов, так как формализмы позволяют оптимизировать работу с памятью, снижают количество вычислений, одновременно улучшая компиляцию грамматики и время загрузки. Задача FST - удаление избыточности из грамматик с сохранением начального смысла в меньшем объеме памяти. По данным разработчика, за счет преобразователей грамматика в 40 тыс. слов может быть сокращена со 170 до 15 Мб.
Также для оптимизации производительности в OSR используют динамическое связывание грамматик, которое позволяет комбинировать различные куски текста во время интерпретации. Алгоритм работы аналогичен тому, как ОС использует отдельные DLL-библиотеки для быстрой загрузки и обновления части программы. Через динамическую связку также по мере необходимости добавляются словари к уже собранной грамматике.













