













BI
Сегодня вопросы анализа структурированной информации в различных прикладных областях в зависимости от специфики задач решены на 90-100%. С точки зрения технологий это объясняется очень просто: современные инструменты анализа позволяют "видеть" данные, хранящиеся в БД. На рынке широко представлены такие привычные пользователям технологии, как OLAP, BI и Data Mining, основанные на популярных методах статистической обработки, прогнозирования и визуализации.
Совершенно противоположная ситуация сложилась с анализом неструктурированных данных, проще говоря - текста, написанного естественным человеческим языком. Проблемы, связанные с автоматизацией этой области, для большинства пользователей пока не решены. Сразу отметим, что, говоря об анализе, всегда имеем в виду поиск ответа на конкретный вопрос того или иного человека.
Например, аналитик из службы надзора спрашивает: "Какие российские банки являются наиболее рискованными?" В упрощенном виде результат должен представлять собой отсортированный по надежности список банков, содержащий оценки рисков. В случае, когда информация находится в базе данных, все понятно: настроили инструмент анализа на запрос к базе, ввели формулу и "попросили" вывести таблицу с сортировкой по степени риска. Но в том-то и сложность, что, как правило, этой информации в базе данных нет. В той или иной форме она присутствует в Интернете и других источниках. Но как добыть ее из неструктурированных данных, например из отчетов банков и других документов, опубликованных в Сети?
Практически все пользователи делают следующее: заходят в поисковик, например Yandex, вводят запрос - и... Получают тысячи и тысячи ссылок... А теперь самое интересное: закатываем рукава и щелкаем на ссылках, просматриваем текст, выделяем нужные фрагменты с названием банка, сведениями о его услугах, уставном капитале, доходности, расходах и прочих показателях, необходимых, cогласно методике или нашему пониманию, для оценки рисков. Полученные данные загружаем в MS Excel, применяем формулы, рисуем графики и наконец любуемся на полученный честным и тяжким трудом результат.
| Популярные мифы о поисковых системах 1. Система дает ответы на вопросы. Не дает - попробуйте спросить. Она лишь помогает сориентироваться в наборах документов. 2. С системой просто работать. Не так уж просто. Составить правильный запрос к поисковику, чтобы получить релевантные ссылки, - целое искусство. Сюда входит и подбор ключевых слов, и составление собственно запроса. 3. Система выдает нужные документы. Это не так. Поисковик выдает только ссылки. А документы мы получаем либо вручную через браузер, либо при помощи специальных инструментов - веб-краулеров и веб-спайдеров. |
Подобных примеров как в быту, так и в бизнесе встречается очень много. Объединяет их одно - рутина, связанная с ручным поиском и добычей данных. Очень это все напоминает картину средневековых рудников: тысячи людей кирками и лопатами вгрызаются в неподатливую породу, добывая крупицы полезных минералов. Получается, что по способу работы с неструктурированной информацией мы находимся в Средних веках. Есть ли сегодня возможность автоматизировать тяжкий труд этих "рудокопов"?
Как показывает анализ российской и зарубежной практики, такие технологии имеются. Попробуем понять, чем могут они быть полезны пользователям, и отделить мифы от реальности.
Наш путь: поиск, извлечение, анализ
Из приведенного выше упрощенного примера видно, что процесс получения конечного результата (ответа на вопрос) можно условно разделить на три фазы. Сначала ищем релевантные документы, потом из того, что найдено, извлекаем данные и в завершение анализируем их. Соответственно современные подходы можно разделить на три группы по степени автоматизации различных фаз указанного процесса: поиска документов, извлечения информации, анализа.
При этом подход, основанный только на автоматизации поиска, практикуется в 90% случаев, извлечение информации автоматизировано приблизительно в 10% решений, и только в редких случаях подобные системы берут на себя аналитическую работу. Хотя именно инструменты анализа наиболее понятны конечному пользователю. Причины такого расклада будут рассмотрены далее.
Применение поисковых систем
Этот подход подразумевает наличие на предприятии поисковой системы, используемой как основное средство в работе с неструктурированными текстами.
Менеджер или аналитик вводит ключевые слова, обрабатывает ссылки, получает документ, просматривает содержание, выбирает нужную информацию, загружает ее в программу анализа или базу данных и генерирует отчет. Известно, что производительность такой работы составляет от 400 до 1000 статей в сутки в зависимости от опытности аналитика. Это тяжкий труд, сравнимый с упомянутой выше работой на рудниках. Человек здесь занят в основном рутинными операциями, а потому не может много внимания уделить действительно интеллектуальной работе.
Основные преимущества такого подхода вполне очевидны: распространенность и общедоступность поисковых технологий. Это так называемое one-click-решение, когда вы набрали ключевое слово, нажали на одну кнопку и.... Добавьте к этому привычку думать, что с дальнейшей обработкой информации, кроме человека, никто справиться не может.
Поскольку инструменты поиска развиваются уже давно и достигли высокой стадии зрелости, они вполне успешно отвечают на вопрос, где находится информация. Их можно сравнить с компасом, который позволяет ориентироваться в мире неструктурированных данных. Пользователи уже успели настолько привыкнуть к поисковикам, что нет необходимости проводить какое-то специальное обучение.
Однако если речь идет об обработке больших массивов данных, применение одних только поисковых систем становится малоэффективным, так как требует значительных человеческих ресурсов на этапах "добычи" фактов и их анализа.
Автоматизация извлечения информации
Этот подход предполагает наличие технологически "продвинутого" инструмента, способного выделять из текста нужные элементы (Text Mining). Его работа заключается в том, что на вход подается текст, написанный на естественном языке, а на выходе пользователь получает запрошенную информацию в структурированном виде. Структуры могут представлять собой как простые сущности (персоны, организации, географические названия), так и сложные (факты, содержащие некое событие, его участников, дату, финансовые параметры и пр.). События бывают самые разные: происшествия, сделки, суды и т. п. Указанный инструмент позволяет автоматически собирать результаты своей работы в коллекции данных, которые уже пригодны для проведения анализа.
Анализировать подобные наборы данных, безусловно, проще и быстрее, чем результаты работы поисковика. Однако и здесь требуются усилия по интеграции средств Text Mining с источниками документов, поисковиком и аналитическими инструментами. Сегодня поставщики инструментов Text Mining снабжают свои продукты возможностями интеграции с источниками документов (в основном с Web-ресурсами) и с базами данных через файлы в формате XML. Предоставляется также набор SDK, применение которого подразумевает довольно дорогую дальнейшую разработку. Но основной проблемой использования этих технологий является сложность настройки и поддержки таких инструментов. Это обусловлено спецификой компьютерной лингвистики, оперирующей терминами синтаксиса, и семантики. Как правило, конечные пользователи и разработчики далеки от этих материй, а в итоге возможности таких инструментов используются лишь на 5-10%.
Тем не менее пользователь уже избавлен от необходимости вручную просматривать тысячи документов и подбирать ключевые слова. За него это делает система. Появляются дополнительные возможности автоматической классификации и сопоставления подобных документов. Кроме того, программа способна сама распознавать смысловые элементы текста, например факты, события, и передавать их на последующую обработку.
Автоматизация аналитических процедур
В простейшем случае в руках конечного пользователя есть такие аналитические инструменты, как MS Excel и MS Access, в усовершенствованном - BI и Data Mining. В отдельных заказных разработках реализуются те или иные ноу-хау. Как бы там ни было, напрашивается очевидное решение: сформировать технологическую цепочку поисковик - Text Mining - инструмент анализа. Интегрировать элементы указанной цепочки можно через базу данных. Для автоматизации процесса в идеале нужен некий механизм, который запросит информацию у поисковика, сам просканирует документы, обнаружит искомые факты, структурирует их, сохранит в базе и сообщит о выполненном задании. Тогда аналитик должен будет только открыть отчеты и проанализировать результаты.
| Text Mining - как это работает? Text Mining - это набор технологий и методов, предназначенных для извлечения информации из текстов. Основная цель - дать аналитику возможность работать с большими объемами исходных данных за счет автоматизации процесса извлечения нужной информации. Назовем основные технологии Text Mining. 1. Information Extraction (извлечение информации): а) Feature (Entity) Extraction - извлечение слов или групп слов, которые, с точки зрения пользователя, важны для описания содержания документа. Это могут быть упоминания персон, организаций, географических мест, терминов предметной области и других слов или словосочетаний. Извлекаемые сущности также могут быть наиболее значимыми словосочетаниями, характеризующими документ по его основной теме; б) Feature (Entity) Association Extraction - более сложные с технологической точки зрения. Прослеживаются различного рода связи между извлеченными сущностями. Например, даже если выбранные субъекты упомянуты в разных документах, но имеют какую-то общую характеристику (время, место и т. д.), можно с большой степенью определенности сказать, есть ли между ними какая-то связь или нет; в) Relationship, Event and Fact Extraction - самый сложный вариант извлечения информации (Information Extraction), включающий в себя извлечение сущностей, распознавание фактов и событий, а также извлечение информации из этих фактов. Например, система может сделать заключение, что Иван Петров купил компанию "Пупкин и Ко", даже если в тексте содержатся только косвенные указания на это событие. Поисковая система здесь беспомощна, так как обычная человеческая речь подразумевает очень много вариантов изложения. Пользуясь лишь поисковиком, мы должны были бы идентифицировать этот факт по всем ключевым словам, которые его характеризуют. А технология Text Mining делает это сама, причем в соответствии с заданными ограничениями отличает относящиеся к делу факты от тех, что никак с ними не связаны. Например, если мы проводим анализ сделок купли-продажи компаний, система способна отнести к разным категориям факты "Мужик купил бутылку водки" и "Иван Петров купил компанию "Пупкин и Ко"". 2. Summarization (автоматическое реферирование, аннотирование) - построение краткого содержания документа по его полному тексту. 3. Categorization (категоризация, классификация) - отнесение документа или его части к одной или нескольким категориям. Категории могут определять "направленность" текста - тематическую, жанровую, эмоциональную, оценочную. 4. Clusterization - объединение документов в группы по принципу их схожести. |
Проблемы такого подхода очевидны и связаны с многокомпонентностью решения. Нужно инсталлировать поисковик, инструмент извлечения данных из текста, средства анализа, а кроме того, произвести всю сопутствующую интеграцию. Тем не менее представляется, что именно этим путем будут двигаться поставщики решений для конечных пользователей. Оснований для этого несколько.
1. Инструменты анализа, в частности BI и Data Mining, во всем мире становятся стандартом де-факто, и все больше специалистов опирается на них как на основные средства создания аналитической среды. Наряду с коммерческими продуктами такого рода развивается мир открытых ресурсов (проекты Pentaho и Eclipse), доступных широкой аудитории пользователей.
2. Технологии Text Mining, включая средства интеграции с источниками информации и аналитическими инструментами, также коммерциализируются (их предлагают такие фирмы, как Clarabridge, Nstein Technologies, Attensity).
3. Развиваются и сами научные области - компьютерная лингвистика, методы анализа текстов. Появились консультанты, в основную сферу деятельности которых входит решение подобных задач. Привлечение этих экспертов делает проекты такого рода исключительно эффективными.
Чтобы не ходить далеко за примерами...
Приведем несколько примеров работы технологической связки поиска - добычи - анализа неструктурированной информации, реализованных нашей компанией на базе платформы Clarabridge. Отметим, что они иллюстрируют лишь часть возможностей такого рода инструментов. Функционал решения может быть гораздо шире.
Система, построенная по принципу технологической связки, позволяет составлять различного рода рейтинги и прогнозы на основе информации, содержащейся в открытых и корпоративных источниках. Так, при расчете рейтинга упоминаемости автомобильных брендов в новостях, публикуемых на сайте Yandex, система нашла ссылки, извлекла факты, выявила связи между ними, структурировала полученную информацию и провела ее анализ (см. рис. 1). Поскольку процесс автоматизирован, пользователь сразу получает готовый информационный продукт, позволяющий судить о том, какие позитивные (негативные) качества ассоциируются с каждым из представленных брендов и как со временем меняются мнения покупателей. Если кнопкой мыши щелкнуть на той или иной части графика - например демонстрирующей падение рейтинга BMW, - система подскажет причины этого падения (в данном случае причиной стал отзыв автомобилей с рынка).
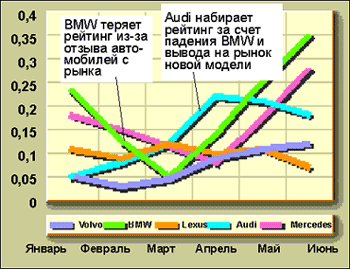
Рис. 1. Рейтинг популярности автомобильных
брендов в онлайновых новостных источниках
Кроме того, технологические комплексы, подобные Clarabridge, могут использоваться для выявления "голоса клиента" или "дыхания рынка" - анализа переписки, заметок call-центров, новостных статей в СМИ и Интернете, мнений покупателей на онлайновых форумах и в блогах. При этом информация из неструктурированных документов интегрируется с данными из CRM-систем и других источников.
| Историческая справка Началом развития технологии Text Mining можно считать эпоху правления президента США Ричарда Никсона (1969-1974 гг.). Тогда были выделены десятки миллионов долларов на развитие научных направлений, связанных с автоматизацией перевода. Это происходило в эпоху холодной войны, когда, в частности, очень актуальной была задача компьютерного перевода с русского языка на английский самых разнообразных документов, начиная с научных докладов и заканчивая технической документацией. Неудивительно, что проект этот носил закрытый характер. В то же самое время появилась новая область знаний - Natural Language Processing (NLP), называвшаяся в России компьютерной лингвистикой. В 90-х годах в открытых источниках стали появляться не только доклады с научных конференций, но и программные коды, что позволило привлечь к разработкам более широкое международное научное сообщество. Наиболее активны в этой области ученые США, Великобритании, Франции и Германии. В нашей стране развитие компьютерной лингвистики имело свою специфику. Она развивалась в основном в интересах оборонных предприятий и служб безопасности и не была ориентирована на решения конкретных бизнес-задач. Сказалось и отсутствие в последние годы целевого финансирования этой области. Тем не менее бурное развитие СМИ и Интернета порождает спрос как со стороны федеральных служб, так и со стороны коммерческих организаций (конкурентная разведка, например). |
Так, для сравнительного анализа популярности тарифов сотовых операторов, обсуждаемых на интернет-форумах, система проанализировала более 20 форумов и блогов, извлекла факты в соответствии с установленными классификаторами и ограничителями, провела сравнительный анализ и представила данные в удобном для принятия решений виде (см. рис. 2).
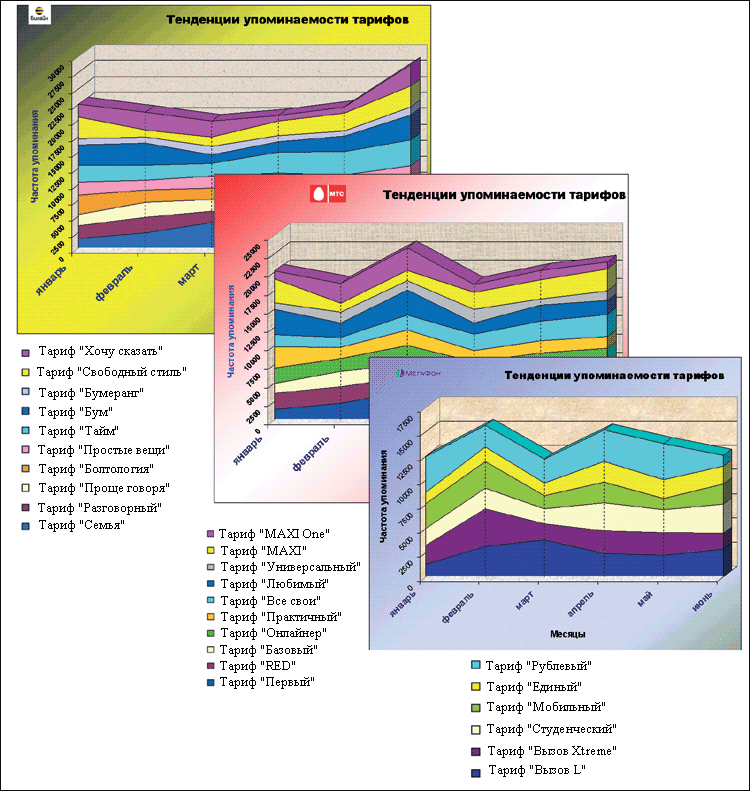
Рис. 2. Тенденции упоминаемости тарифов
Анализ тенденций обсуждаемости различных тарифов позволяет увидеть развитие их популярности и причины, стоящие за этим, а также смоделировать и спрогнозировать продвижение новых тарифов. При этом те или иные показатели можно детализировать до уровня исходного текста, что дает возможность проводить аудит информации с целью проверки достоверности данных и корректности настроек системы.
Выводы
В силу инерции мышления массовая аудитория с недоверием относится к тому,что машина может оперировать понятиями фактов, событий, персон, организаций и т. п. В основном именно это заставляет нас отказываться от технологий Text Mining и загружать себя ручной обработкой результатов поиска. Есть, конечно, и объективные трудности. Методы Text Mining должны быть адаптированы к предметной области, что нередко требует временных и прочих ресурсов. Некоторые типы текстов (например, художественная литература, профессиональный и иной сленг) плохо поддаются машинной обработке.
Между тем технологии добычи информации из неструктурированных текстов (Text Mining) используются на практике уже сегодня. Со временем их применение будет только расширяться, поскольку объемы доступной и полезной информации растут с каждым днем, а потребность в их анализе по-прежнему не удовлетворена.
С автором, руководителем программы по анализу неструктурированной информации компании EPAM Systems, можно связаться по адресу: Pavel_Linyuchev@epam.com













