













Долгие годы эта категория программных систем находилась в тени, считаясь уделом немногих компьютерных “гуру”. Было известно, что наиболее крупные промышленные фирмы, финансовые компании и банки имеют собственные, сделанные на заказ интеллектуальные аналитические системы. Однако системы эти столь сложны, уникальны и дороги, что выход их на массовый рынок сродни появлению “Шаттла” в сельском автомагазине. Фирмы, специализирующиеся на крупных проектах в области искусственного интеллекта, можно было пересчитать по пальцам - HNC, Nestor, Neuron Data, и еще полдюжины мэтров создавали программные комплексы стоимостью от сотен тысяч до миллионов долларов для элиты большого бизнеса.

Однако настоящий прорыв в области высокоскоростных коммуникаций, появление “всемирной паутины” и коммерциализация сети Internet сформировали новый социальный заказ для творцов интеллектуальных систем. Объем данных, требующих осмысленной обработки, возрос настолько, что появилась реальная потребность в аналитических инструментах нового поколения - недорогих, простых в обращении, достаточно гибких, а главное, позволяющих справиться с лавиной “сырой” информации, хлынувшей на головы бедных бизнесменов.
И возник новый рынок. Одна за другой стали появляться программы, способные извлекать жемчужные зерна знаний из баз данных большого объема и глобальных информационных сетей. Их еще нельзя назвать массовыми - число продаж измеряется десятками. Их нельзя отнести к числу дешевых - цены стартуют с 2 - 3 тысяч долларов. Многие из этих программ откровенно сыроваты, в погоне за местом под солнцем авторы не утруждали себя “вылизыванием” интерфейсов. Однако темпы роста нового рынка и интерес, проявляемый к нему со стороны бизнесменов, политиков и военных, позволяют предсказать новорожденному большое будущее. Что же касается названия для нового класса систем (и соответствующей области науки), то оно еще не придумано. С легкой руки журнала Byte чаще всего используется словосочетание “data mining” (что-то наподобие “заготовки данных”), в ходу также более поэтичное “information discovery” и некоторые другие.
“Технология разума”
“Наиболее стабильным источником привлечения средств для John Doe’s Bank сегодня являются индивидуальные накопительные вклады. Основную группу клиентов (38%) составляют пожилые люди, живущие в радиусе 2 миль от городских отделений банка”. Вице-президент банка отложил аналитический отчет. Теперь он знал не только, как поправить дела банка, но и как строить рекламную кампанию на следующий квартал. Программа Dblearn (отрывок из отчета которой был приведен выше) еще раз продемонстрировала свою “профпригодность” в реальных условиях большого бизнеса.
Несмотря на то что программа Dblearn является экспериментальной и еще не представлена на рынке, на ее примере можно пояснить, какой смысл вкладывается в понятие “data mining” (DM). Прежде всего заказчики ждут от DM-систем выявления корреляций между различными атрибутами элементов данных в реляционных БД. Какие факторы способствуют увеличению числа продаж того или иного товара? Какие события влияют на изменения фьючерсных котировок? Какова общая картина политических настроений избирателей по регионам? Часто в качестве одного из контролируемых параметров выступает шкала времени - и система отображает динамику валютных торгов, прогнозы пополнения сырьевых запасов и эволюцию взглядов сторонников президента. Современные DM-системы способны не только находить корреляционные зависимости, но и оценивать вероятность каждой гипотезы. А наиболее мощные системы, использующие аппарат нечеткой логики, способны оперировать не только количественными, но и качественными параметрами - “популярный”, “прибыльный”, “стабильный” и др.
Второй важной функцией DM-систем является автоматическая кластеризация и классификация данных. На какие группы делятся клиенты страховой компании? Какая группа наиболее представительна? Какая наиболее доходна? Обычно пользователей интересует не только количество и размер кластеров, но и расположение их центров (характеризующее “портрет” типичного представителя данного класса объектов), четкость границ и многие другие параметры.
Существенным атрибутом больших DM-систем является возможность автоматизированной обработки неструктурированной текстовой информации (это, кстати, одна из причин интереса российских аналитиков к довольно сложной системе Excalibur). Более простые и дешевые системы требуют некоторой предобработки данных и сведеўния их в реляционные таблицы.
И, разумеется, каждая DM-система в той или иной степени обладает способностью генерировать итоговые отчеты в форме, максимально приближенной к тексту на естественном языке. Немаловажным критерием при выборе системы являются также ее графический интерфейс и широта возможностей визуализации результатов. У хороших систем возможности вывода намного шире, чем привычный для нас набор диаграммок Excel.
На каких же научных дисциплинах базируется все великолепие интеллектуальных возможностей новых аналитических систем?
О, здесь наблюдается чудовищное смешение различных научных школ, подходов и алгоритмов. Ревнивые борцы за чистоту фундаментальной науки могут быть огорчены - в основе многих систем лежат слегка подновленные алгоритмы классического искусственного интеллекта, известные с 40-х годов, но подаваемые под новыми названиями. Однако известная эклектичность нового поколения DM-систем компенсируется широтой их возможностей - многие из решаемых ими задач считались недоступными еще пять лет назад.
Для решения основной задачи DM-систем - выделения корреляционных зависимостей между данными чаще всего используются три подхода: многомерный корреляционный анализ, обработка гипотез по принципу “запрос-отчет” (query-and-reporting tools) и т. н. “интеллектуальные агенты”. Каждый из этих подходов заслуживает отдельной серьезной статьи, поэтому интересующихся научными основами отсылаем к монографии Advances in Knowledge Discovery & Data Mining/U. Fayyad, MIT Press. 1995.
Классификация и кластеризация данных выполняются с помощью нового класса алгоритмов, являющихся развитием нейронных сетей Кохонена и Гроссберга. Сеть Кохонена до недавнего времени считалась единственным примером алгоритма автоматической классификации без обучения и предобработки данных (кроме вырожденных случаев). Сейчас стали появляться более мощные и быстрые комбинированные алгоритмы. Так, авторы классификатора Rule Maker для пакета CubiCalc утверждают, что в основе их пакета лежит некий секретный алгоритм, превосходящий по мощности все известные (может быть, вследствие этого RuleMaker был запрещен к экспорту уже после снятия ограничений на сам CubiCalc). Однако дешевые DM-системы (типа уже упомянутой Dblearn) возлагают груз первичной кластеризации данных на плечи пользователя.
Самые же дорогие и сложные системы, например Prism фирмы Nestor (стоимость от $400 000), включают все известные виды интеллектуальных программ: экспертные системы, нечеткую логику, нейронные сети, генетические алгоритмы и даже теорию хаоса, благодаря чему с успехом применяются в условиях неполноты, зашумленности и противоречивости информационных потоков реального мира.
Кто же использует сегодня DM-системы? Основными “потребителями интеллекта” по-прежнему являются банкиры и финансисты. Наиболее известен, пожалуй, пример успешной адаптации системы Falcon для проверки кредитных карточек American Express, на многие миллионы долларов сократившей ущерб от махинаций с ними. Менее крупные банки и финансовые компании ставят “на боевое дежурство” несколько более дешевые системы - NExpert Object и NEXTRA фирмы Neuron Data (от 8 до 20 тыс. долл.), PC MARS фирмы Data Patterns и др.
Индустриальные компании, обладающие исследовательским потенциалом, обычно идут по пути создания собственных систем для обработки технической, управленческой и маркетинговой информации. Наиболее успешные системы впоследствии попадают на рынок, как это произошло, например, с пакетом RECON фирмы Locheed, используемым сегодня как для отбора перспективных новых технологий, так и для проведения маркетинговых исследований.
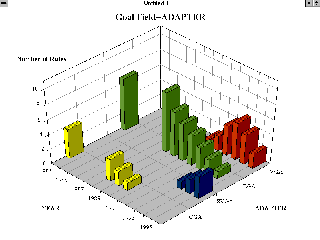
Ответ на запрос пользователя представлен визуально. Показана динамика продаж компьютерных игр с использованием различных видеоадаптеров за последние годы
Чтобы увидеть картинку в натуральном размере дважды щелкните мышкой по этой строке
Есть и множество других примеров. Например, Федерация атлетов США использует пакет IDIS для выявления долгосрочных факторов, влияющих на спортивные результаты легкоатлетов.
Свою лепту внесли и оборонные ведомства. Так, агентство NASA разработало сразу две DM-системы. Первая из них, AutoClass III, предназначенная для широкого распространения, представляет собой написанный на языке Common Lisp специализированный классификатор (т. н. Bayesian). Вторая, система SKICAT, является специализированной системой для обработки изображений и предназначена для внутреннего использования. С помощью системы SKICAT сейчас полным ходом идет подготовка нового издания звездного атласа Паломара. В уникальный каталог войдут изображения и информационные материалы о 50 млн. известных галактик, содержащих около 2 млрд. звезд. Впечатляет.
А семейству пакетов “первого легкого веса” (стоимостью от 2 до 10 тыс. долл.), видимо, предстоит совершить прорыв на массовый рынок и положить начало широкому использованию интеллектуальных систем в малом и среднем бизнесе. Об одном из наиболее многообещающих (и скандальных) пакетов этого класса - пакете IDIS, волею судеб открывшем этот рынок России, расскажем подробнее.
Пакет IDIS - первый блин или первая ласточка ?
Первым DM-пакетом, появившимся на рынке России, стал пакет IDIS фирмы Intelligence Ware. Основное назначение пакета IDIS - построение корреляционных зависимостей между элементами данных при отсутствии первоначальных гипотез. Используя оригинальный алгоритм многомерного анализа, пакет строит наборы правил типа “Если a принадлежит А, b принадлежит B и c принадлежит C, то с вероятностью p переменная x будет принадлежать X”. Пусть вас не пугает сухость и невнятность приведенного правила - пакет способен формулировать найденные гипотезы на естественном языке. Например: “Подавляющее большинство такси (94%) в Нью-Йорке желтого цвета” или “Принадлежность к той или иной политической партии президентов США в наибольшей степени (65%) определяется их местом проживания. При этом в южных штатах преобладают республиканцы, в северных - демократы”. Пользователь может задавать ожидаемое число гипотез, требуемую степень достоверности, а также время, которое он готов ждать до получения результата. Пакет проводит предобработку данных, построение, проверку и “доводку” гипотез, после чего автоматически генерирует итоговый отчет и визуализирует полученные результаты.
Одно из главных достоинств пакета - демократичное ценообразование. Вы можете выбрать вариант системы по своему вкусу - от “университетской” за 1900 долларов до сетевой версии, способной обрабатывать базы данных в несколько миллионов записей (сетевая версия для БД с 1 млн. записей стоит $25 000). В России прижилась т. н. РС-версия пакета стоимостью $3500, способная (согласно рекламе) обрабатывать до 100 000 записей на ПК Pentium с оперативной памятью 16 Мб. Входные данные для IDIS могут быть представлены в форматах dBASE и Paradox, в виде текстовой таблицы, а также в формате любой СУБД, способной обрабатывать SQL-запросы.
Изюминкой пакета является наличие блока обработки исключений - весьма мощной и довольно редкой для аналитических систем функции. Обработчик исключений выполняет задачу, обратную построению и проверке гипотез. Пользователь задает некоторый набор правил, а система автоматически фиксирует все появляющиеся в базе данных отклонения от этих правил. Несмотря на внешнюю простоту алгоритмов обработки исключений, трудно переоценить полезность системы, способной самостоятельно генерировать сообщения типа : “По Ленинградскому шоссе из города выехала автомашина без номеров” или “На личный счет безработного Н. ежедневно поступает от 5 до 8 тыс. долларов”. А если серьезно, программы выделения исключений составляют основу систем первичной обработки информационных потоков в информационно-аналитических службах многих федеральных структур западных стран.
Автору довелось принять участие в испытаниях пакета IDIS при обработке баз данных двух типов. В первом случае предметом исследования являлась база данных о продажах компьютерных игр, накопленная одним из пиратов. Для обеспечения чистоты эксперимента база данных была мультиплицирована до размера 40 000 записей. Потратив некоторые усилия на освоение управляющих параметров пакета, участники эксперимента смогли получить развернутый отчет, анализирующий динамику продаж компьютерных игр. Наряду с тривиальными выводами типа хронологии эволюции EGA-VGA-SVGA пакет построил ряд осмысленных выводов о тенденциях изменения объемов продаж различных игр в зависимости от их типов и характеристик. Второй пример был еще более интересен. В качестве “подопытного кролика” выступала база данных о серверах BBS на территории бывшего СССР (около 3 тысяч записей). Пакет IDIS легко построил довольно наглядную картину технического оснащения различных регионов - как по плотности распределения узлов, так и по качеству телефонных линий (и соответственно скорости используемых модемов). “Выловить” подобные закономерности вручную (даже с использованием сколь угодно мощных статистических пакетов) было бы весьма проблематично. Результатом исследования стал отчет о реальных возможностях пакета IDIS (желающие могут получить его, обратившись к автору по e-mail).
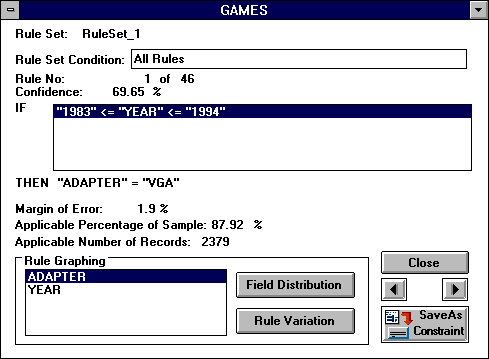
Начало работы с программой IDIS. Пользователь задает вопрос, как менялись видеоадаптеры для компьютерных игрс 1983 г. по 1994 г.
Несмотря на некоторую “сырость” интерфейса пакета IDIS, пакет получает все более широкое распространение. Известны случаи успешного использования IDIS для анализа краткосрочных займов, в промышленном менеджменте и в медицинской диагностике.
Пакет IDIS успел проявить себя и в госучреждениях США. По заказу политиков в университете Wisconsin-Milwaukee на основе пакета IDIS была разработана система, которая строит своеобразные “психологические портреты” политических течений и блоков, представленных в парламенте, анализируя результаты голосования по различным вопросам.
Что касается перспектив использования IDIS в российских условиях, то интерес к нему проявляют представители различных государственных аналитических служб, информационные агентства и финансовые структуры. И, поскольку ближайшие конкуренты IDIS стоят как минимум вдвое дороже, можно предсказать пакету хорошее будущее на отечественном рынке. Между прочим, сейчас обсуждается проект использования пакета IDIS для обработки результатов анкетирования подписчиков PC Week/RE. Так что не исключено, что в ближайших номерах читатели смогут увидеть свой обобщенный “портрет”, составленный программой IDIS - первой DM-программой, прижившейся в России.
Быстрее тысячи Pentium’ ов
Новое поколение DM-систем несет в себе мощь самых современных алгоритмов. Однако чудес не бывает, и ваш любимый Pentium начинает “захлебываться” уже при объемах данных около 50000 записей, не говоря об обработке по-настоящему больших объемов данных. Что делать в таком случае? На Западе проблема решается распараллеливанием обработки баз данных на многопроцессорных серверах. Не случайно все большую популярность обретают многопроцессорные рабочие станции - от двухпроцессорных серверов фирмы ALR до суперкомпьютеров Challenger фирмы Silicon Graphics. В этих системах ускорение достигается за счет распараллеливания обработки SQL-запросов.
Другим подходом является использование аппаратных акселераторов, ориентированных на максимально быстрое выполнение специфических функций интеллектуальной обработки. Так, фирма HNC специализируется на выпуске рабочих станций со встроенными DM-системами “среднего класса” - от 50 тыс. долл. и выше. Различаются два семейства подобных систем. Т. н. Data Mining Workstation представляет собой обычный ПК с нейроплатой Balboa. Система Marksman - это более мощный комплекс, базирующийся на многопроцессорном нейрокомпьютере SNAP.
Однако наибольший интерес для российского рынка, вероятно, представит новое поколение недорогих плат-акселераторов, основанных на серийных нейроБИС. Благодаря “зашитым” в нейроБИС параллельным алгоритмам обучения нейросетей эти платы способны решать задачи распознавания и прогнозирования в сотни (не преувеличение!) раз быстрее ПК на базе Pentium. Неожиданные возможности новых плат уже смогли оценить первые российские пользователи. Несколько недель назад в Россию была ввезена первая нейроплата CNAPS/PC-128 фирмы Adaptive Solutions (анонсированная лишь два месяца назад!). Плата выполняет функции ускорителя нейропакета BrainMaker (об этом пакете PC Week/RE писал уже не раз - № 1, 5, 9 за 1995 г.), достигая увеличения быстродействия на реальных примерах в несколько сот раз. Задачи финансового анализа, требовавшие многих часов работы сервера, плата “щелкала” в считанные минуты. Повинуясь порыву загадочной русской души, испытывавшие плату программисты предложили ей заведомо “гиблую” задачу - построение сети, способной с высокой вероятностью прогнозировать исходы футбольных матчей (задача была реальной, выполняемой по заказу крупной букмекерской конторы). Накануне 100 МГц Pentium потратил почти сутки непрерывного счета, чтобы выйти на требуемый уровень качества прогнозирования (около 55% угадываний). Нейроплате понадобилось 8 минут, чтобы научиться точно предсказывать исходы 5200 матчей из 6000, представленных в базе данных. Не верите? Автор сначала тоже был настроен скептически, пока не увидел своими глазами, как плата с легкостью распознает произвольные геометрические фигуры, обучаясь с точностью до 99,99%.
Андрей Масалович






