 | Стивен Эллиот, вице-президент группы IDC по инфраструктуре и операциям, облачным операциям и DevOps, рассказывает … |
 | В классической ИТ-архитектуре понятие Disaster Recovery (DR), как правило, является синонимом «запасного плана». Это … |
 | Рассмотрим, почему поддержка корпоративных систем больше не может ограничиваться «закрытием заявок» и как выбрать … |
 | 2026-й уже близок к середине, но впереди нас ждет еще много интересного — и, к счастью, не все … |
 | Согласно Gartner «1H26 CIO Report», 77% CIO называют безопасность и риски главными препятствиями для масштабирования … |
 | На рынке труда в ИТ сложилась странная ситуация: резюме много, подходящих людей — по-прежнему мало. Повышать … |
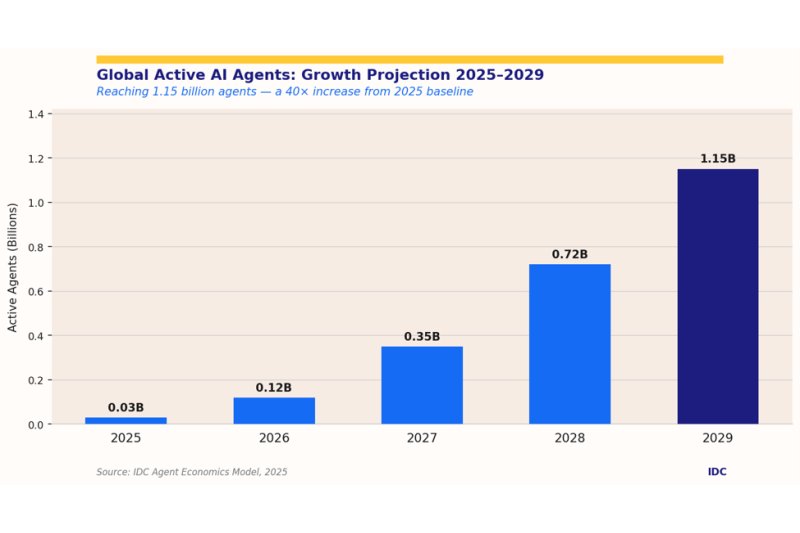
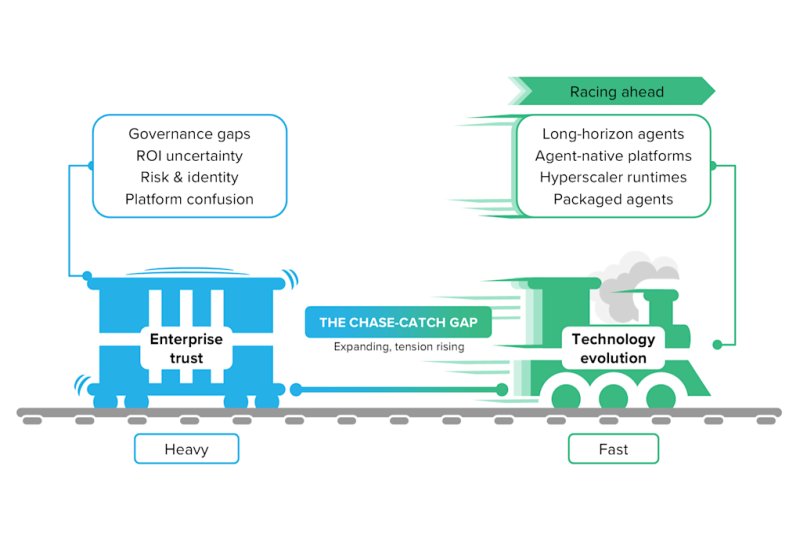 | Три четверти руководителей предприятий сообщают, что они внедряют агентный искусственный интеллект. Но лишь небольшое … |
 | Федеративная архитектура (Federation Architecture, FA) обеспечивает баланс преимуществ конвергенции ИТ-ОТ с мерами … |
 | Отслеживание производительности искусственного интеллекта имеет решающее значение. Однако традиционные ИТ-инструменты … |
 | Практически каждая компания, которая развивает цифровой продукт, рано или поздно сталкивается с одним и тем же … |





















