Автоматизация общих задач по устранению последствий инцидентов позволяет ускорить реагирование, сократить количество ошибок и повысить производительность, пишет на портале The New Stack Грег Чейз, директор по маркетингу продуктов PagerDuty Automation и Rundeck.
Для современных организаций, ориентированных на цифровые технологии, проблемы с ПО часто становятся проблемами бизнеса. По мере того как доходы компаний и работа с клиентами все больше перемещаются в Интернет, инциденты и сбои, а также связанные с ними простои будут оказывать все большее влияние на доходы, удовлетворенность клиентов и продуктивность сотрудников.
Факт заключается в том, что многие нарушения работы ИТ-систем достаточно хорошо изучены как с точки зрения диагностики, так и с точки зрения устранения последствий — даже если вы устраняете проблему лишь на время. Диагностика предупреждений от «шумных» сервисов обычно начинается с тех же шагов. Шаги по устранению неполадок «прямо сейчас» также часто одинаковы и включают в себя простую перезагрузку и восстановление работоспособности служб.
Эти повторяющиеся действия — хорошие кандидаты на автоматизацию, позволяющую ускорить реагирование, избежать отвлечения профильных экспертов, уменьшить количество ошибок и повысить производительность.
Недостатки отказа от автоматизации реагирования на инциденты
ИТ-операторы должны устранять серьезные сбои как можно быстрее, поэтому они отслеживают такие показатели, как среднее время решения проблемы (MTTR) и допустимое количество ошибок. В этих случаях восстановление сервиса является наивысшим приоритетом, независимо от того, чья работа нарушена.
После достижения целевого уровня обслуживания (SLO) актуальной становится задача повышения эффективности ИТ-поддержки. Все менее серьезные инциденты, ИТ-события и оповещения мониторинга могут приводить к росту затрат на поддержку и отвлекать старших инженеров от основной работы, снижая скорость создания новых функций. К сожалению, ситуация во многих организациях далека от идеальной. Исследование показало, что пятая часть организаций испытывает «сильное воздействие» (снижение производительности на 25% и более) от отвлечения на незапланированные работы из-за ИТ-инцидентов и сбоев. Для 47% организаций это воздействие является «значительным», что означает снижение производительности на
Во многом это связано с тем, что операторы, не имеющие знаний или прав доступа для самостоятельного устранения проблем, вынуждены обращаться к старшим инженерам для их решения. Многие сотрудники операционных центров не обладают знаниями о множестве систем, которыми управляет предприятие, и, скорее всего, не имеют навыков диагностики и устранения проблем, если на то нет четких инструкций, например, в руководстве по эксплуатации. Они также могут не иметь необходимых привилегий доступа для запуска тестов или внесения изменений в производственную среду, что может быть обусловлено как низким уровнем квалификации, так и тем, что компаниям необходимо держать свои среды закрытыми по соображениям соответствия нормативным требованиям.
Зачастую такие специалисты тонут в сигналах и оповещениях, не могут отфильтровать шум от огромных объемов данных и не способны сделать ничего, кроме как эскалировать запрос о помощи. В результате старшие инженеры вызываются на помощь даже для решения базовых задач просто потому, что у них есть права доступа к затронутым системам. Такие перебои могут занимать несколько часов в неделю, отвлекая инженеров от проектов разработки. В итоге в инцидентах участвует слишком много инженеров, которые занимаются такими элементарными вещами, как выполнение тестов, чтобы показать, что их код не является причиной проблемы.
Автоматизация реагирования на инциденты с помощью AIOps
Автоматизация предсказуемых, повторяющихся шагов в реагировании на инциденты позволяет сократить количество ненужных эскалаций к экспертам, расширить возможности служб экстренного реагирования и (в идеале) вообще отказаться от привлечения людей. Рассмотрим типичный рабочий процесс реагирования на инциденты:
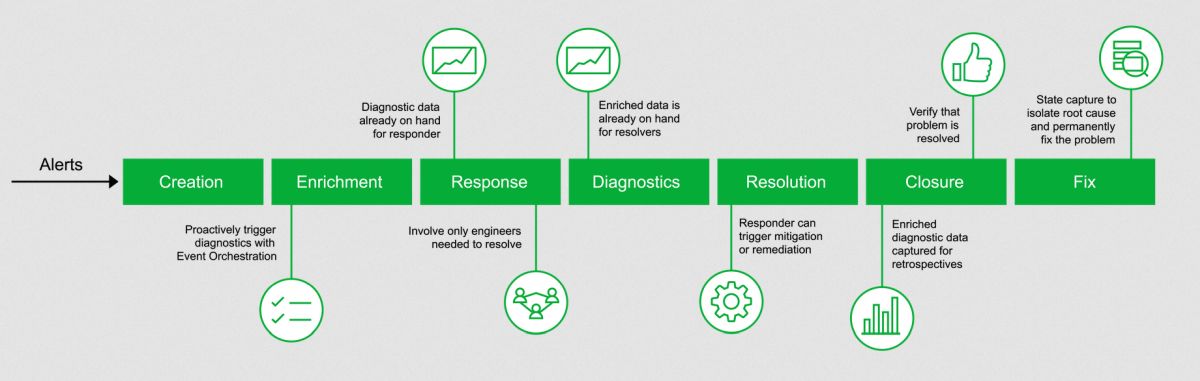
Использование искусственного интеллекта в ИТ-операциях (AIOps) для обнаружения проблем из потока оповещений и маркировки инцидентов — это один из основных способов повышения скорости и эффективности. Вам не нужно будет смотреть на панель управления, чтобы найти проблему; AIOps может отфильтровать множество повторяющихся шумов и ложных оповещений, чтобы найти реальные проблемы, требующие принятия мер. Благодаря AIOps, отвечающему за запуск рабочих процессов реагирования на инциденты, можно автоматизировать задачи вплоть до их разрешения, закрытия и даже внесения разработчиками окончательного исправления.
Как начать работать с AIOps
Приведенная выше диаграмма показывает, что существует множество возможностей для повышения эффективности реагирования на инциденты с помощью автоматизации. Но с чего следует начать?
Необходимо найти баланс между вашей уверенностью в автоматизации, стоимостью инцидента и частотой выполнения задачи. Распространенные инциденты с отработанными автоматизированными шагами по диагностике и устранению последствий являются хорошими возможностями для запуска AIOps. Далее приоритизируйте реагирование на инциденты и действуйте аналогично.
Автоматизируйте диагностику и шаги по устранению последствий серьезных сбоев, чтобы ускорить их разрешение. Затем сосредоточьтесь на повышении эффективности за счет автоматизации повторяющихся действий по диагностике и устранению последствий, которые встречаются во многих видах инцидентов. С помощью AIOps можно безопасно автоматизировать и запускать действия с низким уровнем риска, такие как диагностические запросы «только для чтения», предоставляя нижестоящему персоналу необходимую информацию.
Можно автоматизировать общие действия по устранению последствий и сделать их доступными для использования специалистами по реагированию. Для такой автоматизации можно использовать средства управления секретами, например Vault, чтобы разрешить привилегированные действия в производственных средах без предоставления учетных данных, что делает более безопасным делегирование полномочий специалистам. Если вероятная причина инцидента очевидна, а автоматизация устранения последствий является проверенной процедурой, можно задействовать AIOps, чтобы обеспечить самовосстановление без необходимости вызова специалистов.
Решение о том, что автоматизировать в первую очередь, может повлечь за собой альтернативные издержки. Поэтому поиск задач, которые могут принести наибольший финансовый эффект, — это ваш путь к успеху.
Пять принципов проектирования автоматизации устранения инцидентов
Вот пять ключевых принципов, которые помогут организациям автоматизировать процесс устранения инцидентов, значительно сократить трудозатраты сотрудников, высвободить таланты для инноваций и оптимизировать процесс устранения инцидентов.
- Начните с простого. Не стоит создавать слишком сложные автоматизированные системы для каждого вида инцидентов. Создавайте примитивные задачи и действия и используйте их в качестве строительных блоков для более сложных потоков. Начните с действий, не связанных с риском, например, не изменяющих производство или выполняемых с меньшими привилегиями доступа. Сокращайте время выполнения. Избегайте слишком большого количества технологических доменов.
- Создайте защитные ограждения. При запуске или остановке автоматической задачи необходимо отправлять уведомления — по электронной почте, через панель управления реагированием на инциденты, мессенджер или другим способом. Избегайте циклов, по крайней мере, в рамках автоматизации компонентов. Возможно, ваш рабочий процесс управления инцидентами запускает несколько повторных попыток, но эти правила должны были видны, а не спрятаны в другой автоматизации. То же самое относится и к условным выражениям типа if/then/else. Оставьте их видимыми в рабочем процессе реагирования на инциденты. Всегда сообщайте о статусе выполнения: успех, неудача, ошибка.
- Предоставьте значимые результаты. Автоматизация должна иметь смысл для конечных пользователей, чтобы они могли извлечь максимальную и немедленную пользу из результатов. Учитывайте, кто являются вашими пользователями, какими навыками и знаниями они обладают. Помните, что многие специалисты по оказанию первой помощи могут не обладать глубокими техническими системными знаниями, которыми обладают предметные специалисты. Так, вам может понадобиться упростить диагностическую информацию, чтобы улучшить и ускорить процесс принятия решений по маршрутизации заявок на поддержку. Речь идет о получении исходных данных и их преобразовании в ту информацию, которая действительно нужна конечному пользователю.
- Обеспечьте согласованность. В развитие предыдущего пункта: ключевым моментом в организации поддержки большего числа операций широким кругом специалистов является обеспечение последовательного и упрощенного опыта конечных пользователей. Это может включать стандартизацию стилей кода, входных параметров и представления каталогов. Ваша организация может использовать Ansible для среды Azure, CloudFormation и Terraform для AWS или даже смесь скриптов BASH и Python. Главное — обеспечить единообразие работы конечного пользователя во всех средах и инструментах, чтобы не требовать от сотрудников специализации в различных инструментах. Сколько приложений могут реально поддерживать ваши специалисты?
- Документируйте процесс. Всегда документируйте автоматизацию в точке вызова. Некоторые процессы, вероятно, будут выполняться нечасто, поэтому не стоит ожидать, что сотрудник, отвечающий на запросы, будет помнить, чему учился несколько месяцев назад. Аналогичным образом, в некоторых организациях наблюдается высокая текучесть кадров, поэтому документирование помогает исправить ситуацию, когда обучение может быть неполным. Эта документация должна направлять пользователя стандартным образом, чтобы повысить уровень понимания и обслуживания.
Где в игру вступает человек
Автоматизация не является панацеей для реагирования на инциденты. Идея состоит в том, чтобы позволить машинам выполнять ручные и повторяющиеся задачи там, где это возможно. Когда инциденты сложны или новы, необходимо привлекать людей. Но даже в тех случаях, когда требуется вмешательство профильных специалистов, автоматизированные процессы могут ускорить их работу за счет упреждающего сбора подробных диагностических данных, необходимых для определения основных причин и правильных действий по устранению последствий.
В цифровом мире автоматизация должна быть на первом месте в списке задач каждого ИТ-подразделения.