













“Следующее поколение” против “будущего”, или Next Generation I/O vs. Future I/O
Обзор
Андрей Борзенко
Если для мэйнфреймов проблемы создания сбалансированных подсистем ввода-вывода были решены еще до того, как родились многие из читающих эти строки, то для компьютеров, имеющих интеловскую архитектуру, дело обстояло несколько иначе. С момента появления первых IBM PC производительность подобных компьютеров оценивалась исключительно по мощности установленных в них микропроцессоров. Ограничения, накладываемые подсистемами ввода-вывода и памяти, в расчет не принимались. Первое время это было действительно справедливо, однако по мере роста мощности микропроцессоров без учета указанных ограничений сконструировать хорошо сбалансированную систему стало практически невозможно. Особенно остро проблемы, связанные с узкими местами интеловской архитектуры, возникали при проектировании ПК-серверов. Следует также заметить, что для современных серверов не менее важными являются такие параметры, как надежность, возможность масштабирования, управляемость, отношение цена/производительность, включение технологических новшеств и т. п.
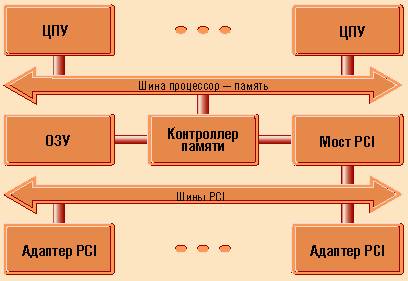
Архитектура подсистемы ввода-вывода с шиной PCI
Возвращаясь к проблеме ввода-вывода информации, напомним, что в отличие от микропроцессоров, производительность которых растет невиданными темпами, шины ввода-вывода эволюционируют достаточно медленно. За время, прошедшее с момента появления первого Pentium, быстродействие микропроцессоров увеличилось примерно в семь раз, а пропускная способность подсистем ввода-вывода, по различным оценкам, только в два - четыре раза. Да и не мудрено. Например, шина ISA используется в компьютерах уже 17 лет. Она “пережила” целый ряд микропроцессоров, начиная с i80286 и кончая Pentium II. По понятным причинам эта шина давно не применяется в ПК-серверах, в них ее заменила шина PCI. Впрочем, последняя с 1992 г. тоже изменилась довольно мало. В то время как тактовая частота микропроцессоров скоро превысит 600 МГц, 32-разрядная шина PCI работает с частотой 33 МГц, ее же 64-разрядные расширения практически не используются.
Новая жизнь PCI - PCI-X
В прошлом году три крупнейшие компьютерные компании - Compaq (www.compaq.com), Hewlett-Packard (www.hp.com) и IBM (www.ibm.com) - разработали новую спецификацию расширения шины PCI, названную PCI-X, которая работает на тактовой частоте 133 МГц. Осенью проект спецификации был предложен для рассмотрения организации PCI Special Interest Group. Надо отметить, что и до этого времени Compaq, Hewlett-Packard и ряд других производителей ПК-серверов выпускали продукцию с 64-разрядными разъемами PCI, рассчитанными на тактовую частоту 66 МГц, хотя в чипсетах Intel была обеспечена поддержка только 32-разрядных слотов и тактовой частоты 33 МГц (новые функции будут встроены только в наборе микросхем Intel 450NX, который появится в этом году).
Шина PCI-X обладает обратной совместимостью с PCI, кроме того, благодаря новой схеме обмена регистр - регистр достигается пропускная способность 1,06 Гб/с (8 Гбит/с), что обеспечивает почти шестикратный выигрыш в производительности. Новая спецификация позволяет увеличить число разъемов для подключения периферийных устройств. Если в настоящее время только один слот тактируется частотой 66 МГц, а остальные - 33 МГц, то в случае PCI-X одно устройство работает на частоте 133 МГц, а остальные - на 66 или 100 МГц. В первую очередь PCI-X предназначена для высокопроизводительных адаптеров типа Gigabit Ethernet, Ultra 3 SCSI и Fibre Channel (FC-AL).
Первые серверы, использующие данную шину, должны появиться уже к концу этого года. Заметим, что спецификация одобрена производителями сетевых и операционных систем - Microsoft, Novell, SCO. Кроме того, компании Adaptec, Mylex и 3Com уже выразили намерение выпускать периферийные адаптеры, соответствующие спецификации PCI-X.
Не поддержала спецификацию PCI-X, пожалуй, только корпорация Intel. Ее представители высказывали в прессе самые различные доводы против, но самым главным был, конечно, тот, что развитие PCI не имеет перспектив.
Проблемы шинной архитектуры
Современная подсистема ввода-вывода базируется на распределенной модели памяти с топологией “общая шина”, которая, впрочем, также уже не отвечает многим требованиям, предъявляемым при создании высокопроизводительных ПК-серверов. Если говорить о производительности, то при такой архитектуре шина не может поддержать скорость ввода-вывода информации, обеспечиваемую микропроцессором. Поэтому процессор вынужден ограничивать собственное быстродействие при общении с любым периферийным контроллером.
Кроме того, не секрет, что сервер обычно приобретают в расчете на дальнейшее расширение его возможностей - масштабирование. Однако при использовании современной архитектуры проблемы возникают и в этом случае. Так, количество подключаемых периферийных устройств ограничено небольшим числом разъемов шины.
При распределенной архитектуре памяти ошибка, связанная с контроллером или драйвером устройства, может привести к изменению содержимого другой области памяти, что обычно ведет к краху всей системы. Причем локализовать место возникновения подобной ошибки достаточно сложно.
Топология “общая шина” подразумевает, что параллельные линии совместно используются всеми устройствами для передачи управляющих сигналов и данных. Хотя этот подход хорошо изучен и неплохо себя зарекомендовал, он имеет ряд ограничений и недостатков. Так, доступ к шине всех подключенных устройств должен контролировать некий арбитр. Борьба между устройствами за захват шины может отрицательно сказаться на общей производительности. Проблемы возникают и при организации “горячей” замены устройств. Тем более что установить источник ошибки и изолировать его довольно непросто.
Конфигурация подключенных устройств выглядит скорее как искусство, нежели как наука. Часто в серверах для повышения производительности используются выделенные разъемы для специальных устройств (так называемая многоярусная топология). На практике же в ряде случаев получить ответ на вопрос, что с чем работает, удается только экспериментально.
Высокие тактовые частоты накладывают ограничения на удаленность шины (как группы параллельных проводников) от контроллера памяти. В зависимости от конструктивных особенностей это расстояние не превышает обычно 45 - 75 см.
Как правило, требования по электропитанию и охлаждению должны учитываться и для обеспечения возможности дальнейшего расширения системы. Все это неблагоприятно сказывается на начальной стоимости компьютера.
Подсистема следующего поколения
Учитывая дальнейший рост производительности микропроцессоров, а также недостатки и ограничения топологии “общая шина”, осенью 1998 г. корпорация Intel обнародовала принципиально иную архитектуру, которую скромно адресовала следующему поколению подсистем ввода-вывода - Next Generation I/O (NGI/O). Собственно, это и было ответом на спецификацию PCI-X.
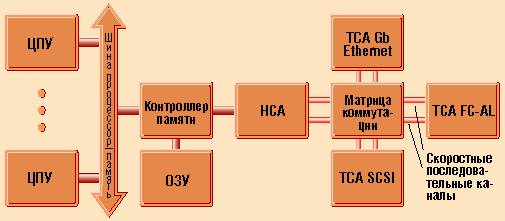
Архитектура подсистемы ввода-вывода NGI/O
“Тремя китами” новой архитектуры можно назвать последовательный обмен данными, канальную технологию ввода-вывода и матричную топологию.
Итак, в интеловской архитектуре компьютеров появятся наконец-то каналы ввода-вывода, которые были на время забыты (хотя до сих пор используются на мэйнфреймах). Контроллер канала будет работать по так называемой схеме передачи сообщений. Иными словами, базовый микропроцессор теперь не будет сам заниматься рутинной работой по обмену данными с периферийным устройством, а станет только инициировать прием или передачу, давая соответствующие указания процессору (контроллеру) канала. Немаловажно и то, что периферийные устройства будут иметь доступ к основной памяти исключительно через контроллер канала. По всей видимости, прототипом канальных процессоров станут известные микросхемы Intel i960.
Топология матричной коммутации (fabric), заложенная в NGI/O, позволяет взаимодействовать всем устройствам, входящим в матрицу, по принципу “каждый с каждым”. Ее задачей является распределение данных по каналам. Ключи матрицы временно образуют коммуникационный канал между компьютером и периферийным устройством, организуя обмен “точка - точка”. Подобная технология находит применение, например, в сетевых коммутаторах и маршрутизаторах. Ее часто сравнивают с телефонной сетью, поскольку она обеспечивает избыточность из-за возможности повторного выбора маршрута.
Благодаря этой топологии исключается проблема арбитража и конфликтов, “горячая” замена устройств становится действительно автоматической, существенно облегчается конфигурирование контроллеров (причем общая производительность не ухудшается из-за неправильного конфигурирования одного из них), расстояние между периферийным контроллером и контроллером памяти может быть увеличено до 30 м. Стоит также отметить, что трудностей с расширением при использовании этой топологии практически не существует. По некоторым данным, с помощью NGI/O к системе можно подключить до 64 тыс. устройств.
Строительным “кирпичиком” NGI/O является архитектура виртуального интерфейса VIA (Virtual Interface Architecture). В качестве интерфейса контроллера памяти сервера служит главный канальный адаптер HCA (Host Channel Adapter). Он содержит процессор прямого доступа к памяти (DMA). Для связи между матрицей коммутации и контроллерами ввода-вывода периферийных устройств предназначены объектные канальные адаптеры TCA (Target Channel Architecture). Канальный адаптер может подключаться к другому адаптеру или ключу. Эти ключи и образуют матрицу коммутации.
Для обмена информацией между сервером и периферийным устройством предлагаются два метода передачи данных: с использованием программных средств (Send/Receive) и без таковых (RDMA Read/Write). Последний предназначен для передачи больших блоков информации и потоковых данных.
Скорость передачи для одного канала NGI/O оценивается на уровне 1,25 - 2,5 Гбит/с, однако при увеличении числа каналов до четырех она соответственно возрастает до 10 Гбит/с, что значительно превышает существующие возможности шины PCI и даже PCI-X. Большинство реальных PCI-устройств достигают скорости 132, реже 268 Мб/с (1,03 и 2,09 Гбит/с соответственно).
Для развития и внедрения новой технологии корпорация Intel возглавила группу компаний, включающую Dell Computer, Hitachi, Siemens Information Communication Network, NEC и Sun Microsystems, которая получила название NGIO Industry Forum.
Около четырех десятков крупнейших производителей компьютеров и программ, собравшихся на конференцию разработчиков (Intel Developer’s Forum) 23 февраля, поддержали архитектуру NGI/O. Стоит отметить, что NGI/O одобрили и “программные гиганты” - Microsoft и Novell. Большой интерес к NGI/O проявили также разработчики Linux-приложений. Судя по результатам прошедшего форума, продукцию, использующую NGI/O-архитектуру, можно ожидать на рынке уже в следующем году.
Собственное мнение
Предложение участвовать в NGIO Industry Forum получили и крупнейшие производители серверов. Но они, видимо, обиделись на Intel за отвергнутую PCI-X. Сразу после объявления NGI/O корпорация IBM сообщила, что в своих серверах следующего тысячелетия она будет использовать так называемую X-архитектуру, которая сочетается со всеми технологиями Wintel и наследует лучшее из подсистем ввода-вывода машин S/390, AS/400 и RS/6000. А чтобы слова не расходились с делом, прошлой же осенью по инициативе IBM был создан альянс для разработки открытого стандарта на архитектуру под названием Future I/O. Первоначально в него вошли создатели PCI-X - Compaq, IBM и Hewlett-Packard, к которым присоединилась компания Adaptec, а позднее и 3Com.
Окончательно альянс был оформлен 12 января, а уже месяц спустя на конференцию разработчиков стандарта Future I/O собрались представители 60 компаний. Специалисты еще от 90 фирм выступили как наблюдатели. Спецификацию поддержали такие фирмы, как AMD, Amdahl Associates, Digi International, Dolphin Interconnect, DPT, EMC, GigaNet, LSI Logic, Molex, Mylex, Novell, Poseidon, Qlogic, SCO, SGI и др.
Уже известно, что для данной архитектуры, как и для NGI/O, планируется использовать матричную топологию, позволяющую получить соединения типа “точка - точка”. Правда, в отличие от NGI/O в спецификации Future I/O допускается применение PCI-адаптеров. Сделано это для того, чтобы продлить жизнь своему детищу - PCI-X. Другим отличием Future I/O стал интерфейс связного уровня HiPPI 64000. А вот программная архитектура обеих спецификаций основана на виртуальном интерфейсе VIA.
Среди других известных деталей новой спецификации интерес представляет следующая: максимальная производительность одного соединения в режиме полного дуплекса может достигать 2 Гб/с по медному кабелю на расстоянии 5 - 10 м, а по оптоволоконному - до 300 м.
В начале 2000 г. спецификация должна быть утверждена, а первые результаты применения новой технологии могут быть получены не ранее 2001 г.
Худой мир лучше доброй ссоры
Переговоры, которые проходили в конце прошлого года между двумя альянсами, были прерваны, так как компромиссного решения найти не удалось. Сторонники NGI/O и Future I/O обвиняли друг друга в непомерной лицензионной плате за использование новых технологий, хотя обе стороны по сей день утверждают, что ежегодные отчисления будут чисто номинальными.
Ряд аналитиков, в частности из Dataquest, предсказывают новую “войну шин”. По этому поводу хотелось бы напомнить печальную участь шины MCA (Micro Channel Architecture), разработанной в свое время компанией IBM взамен шины ISA. Однако группа фирм, в число которых входила, кстати, и Compaq, не желая платить лицензионные отчисления, предложили тогда собственную спецификацию - EISA. Результат той “войны” хорошо известен.
Но существуют и более оптимистичные точки зрения. Так, многие эксперты полагают, что в будущих серверах смогут ужиться подсистемы ввода-вывода, объединяющие в себе PCI-X, NGI/O и Future I/O, как в некоторых компьютерах часто сосуществуют шины ISA/EISA с PCI. Уже сейчас ряд компаний поддерживает обе новые технологии.








