ПРОЕКТЫ
eWeek Labs гостит в Станфорде: у Intel-кластера есть потенциал для работы на бизнес
Десяток лет назад суперкомпьютеры представляли собой многомиллионнодолларовые системы, которые использовались для грандиозных проектов, таких, как моделирование климата Земли или ядерных реакций. Сегодня они обозначаются аббревиатурой HPCC (High Performance Computing Clusters - высокопроизводительные вычислительные кластеры) и могут быть - если их строить из простаивающих ПК - почти бесплатными. А что еще важнее, они быстро становятся пригодными для распространенных корпоративных вычислений.

Стив Джоунс (слева) и директор eWeek Labs Джон Ташек
запускают программу на суперкомпьютере в Стефорде.
Снизу - кластер Стэнфордского университета

HPCC выглядят совершенно иначе, чем традиционные суперкомпьютеры: они имеют воздушное, а не водяное охлаждение, размещаются в стойках и используют готовые, серийно выпускаемые компоненты. И если десять лет назад изобретателю суперкомпьютеров фирме Cray Research удавалось смастерить лишь две-три большие системы в год, то нынешние компании, например Dell Computer, Red Hat или Microsoft, выпускают сотни суперкомпьютеров новейшего типа.
Изменения суперкомпьютерных систем наиболее отчетливо видны в академической среде, где, как правило, и используются суперкомпьютеры новой эпохи.
Сотрудники eWeek Labs недавно побывали в Станфордском университете (США, шт. Калифорния), где устанавливается кластер из 300 узлов на базе систем Dell под управлением Red Hat Linux. Кластер предназначен для исследовательских программ Bio-X - огромного университетского центра, главным спонсором которого является Джим Кларк, известный как основатель фирмы Silicon Graphics. Роль Bio-X состоит в объединении различных наук, включая технические разработки, физику, медицину и биологию, чтобы исследователи могли более рационально использовать общие ресурсы, данные и координировать свои проекты.
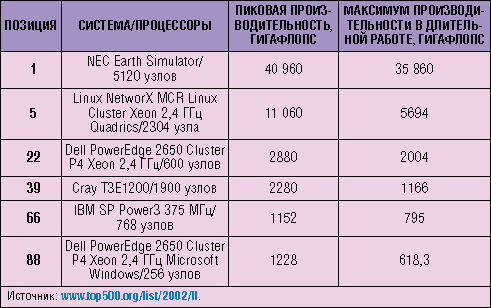
Университет приступил к строительству кластера в конце прошлого года при содействии корпораций Dell и Intel. К маю работа вышла на стадию наладки, и создатели системы рассчитывают, что она попадет в список Top 500 Supercomputers - каталог крупнейших в мире суперкомпьютеров, дважды в год совместно издаваемый Мангеймским университетом (Германия), Университетом штата Теннесси и Национальным научным вычислительным центром энергетических исследований США (ряд выдержек из этого списка приведен ниже).
Забавно, что всего несколько лет назад список Top 500 в основном составляли системы SGI на основе технологии Cray. Ныне Cray-системы выглядят в нем лишь как отдельные вкрапления.
Самый быстрый из суперкомпьютеров Cray фигурирует под номером 39 и работает с производительностью 1166 гигафлопс (миллиардов операций с плавающей запятой в секунду) - примерно в тысячу раз быстрее системы Cray Y-MP выпуска 1988 г. К сведению организаций: производительность системы Cray N 39, используемой правительством США для необъявленных целей (по-видимому, для моделирования в оборонных исследованиях), куда ниже, чем у систем с ОС Red Hat Linux, которые гораздо дешевле для построения и эксплуатации. Самый быстрый Linux-кластер, функционирующий в Национальной лаборатории Лоуренса Ливермора, обеспечивает быстродействие порядка 6000 гигафлопс.
В Станфорде первоначально задались целью занять одно из первых 70 мест Top 500. Однако по завершении строительства системы архитектор кластерного проекта Стив Джоунс сообщил, что после контрольных тестов самое большее, на что он надеется, это попасть в первые две сотни. (Окончательные цифры еще не подбиты, но, по оценке eWeek, станфордская система станет приблизительно 170-й.) Хотя в кластере можно задействовать недорогие компьютеры, на производительность системы сильно влияет сетевая коммутирующая структура. Из финансовых соображений Джоунсу пришлось использовать сетевую магистраль 100BaseT (Fast Ethernet), а не гораздо более быструю сеть Gigabit Ethernet. "На наш результат, - считает он, - огромное влияние оказала коммутирующая структура. Будучи ограничены в затратах, мы с самого начала пожертвовали скоростью сетевой передачи. При иной коммутирующей сетке мы получили бы более заслуженное место".
К самым быстрым среди высокопроизводительных кластерных межсоединений принадлежат устройства Myrinet, поставляемые фирмой Myricom. Однако такие межсоединения, как правило, дороги: около $1000 за узел (т. е. $300 000 для типичного HPCC), и еще $100 000 стоит коммутатор Myrinet. Для большинства академических организаций это слишком накладно, однако если бы Станфорд взял на вооружение именно Myrinet, он легко бы перепрыгнул на сотню позиций вверх. По словам Джоунса, если ничего не изменится, то осенью они, скорее всего, заменят коммутирующую сетку на Gigabit Ethernet и в ноябре проведут повторные тесты.
Почему же Джоунс и Станфордский университет все-таки решили участвовать в сравнительном тесте, зная, что грядущий переход на новую коммутирующую структуру так резко поднимет их позицию? Как свидетельствует Джоунс, контрольные испытания помогли отладить кластер и повысить его производительность, что уже приносит пользу ученым и исследователям из Станфорда.
В корпоративном бизнесе кластеры сегодня играют не более чем маргинальные роли и могут иметь лишь специфические сферы применения. По мнению Ризы Рухоламини, заведующего разработками ОС и кластеров в продуктовой группе Dell и руководителя кластерной группы этой же компании (Раунд-Рок, шт. Техас), HPCC-системы постепенно выходят из академических стен в бизнес и в настоящее время имеют три главные области коммерческого интереса - разведку нефти, биоинформатику и автомобильную промышленность (для имитационного моделирования аварийных испытаний). "Эти приложения, - говорит Рухоламини, - носят типично технический характер, но применяют их коммерческие организации, делая на них деньги и бизнес".
Рухоламини указывает на ряд проблем, связанных с кластерами в корпоративных приложениях. Например, в кластерах трудно работать с приложениями баз данных (а это ядро корпоративных вычислений) из-за сложностей обработки распределенных запросов. У IBM и Oracle есть СУБД с поддержкой кластеров (соответственно DB2 и Oracle9i RAC), однако их непросто налаживать, сетует Рухоламини. И, вообще говоря, практически невозможно взять существующие приложения и перекомпилировать их в приложения с передачей сообщений, использующие преимущества вычислительных кластеров.
Пожалуй, проще будет прибегнуть к так называемым grid-системам с распределением рабочих нагрузок приложений. Microsoft, скажем, уже работает над объединением технологий grid-систем и кластеров. По словам Грега Ранкича, управляющего выпуском продуктов Windows Server Product Management Group, корпорация немалые усилия концентрирует на распределенных бизнес-решениях - отчасти ввиду пользовательского спроса на консолидацию, но еще и для того, чтобы задействовать свободные циклы процессоров.
Рухоламини согласен, что grid- и HPCC-технологии постепенно сливаются. "Мы рассматриваем grid-вычисления как эволюцию HPCC. В технологическом плане если я сконструирую свой HPCC и распределю его вычислительные узлы по более широкому географическому пространству, то тем самым решу задачи, необходимые для построения grid-системы. А если я ликвидирую задержки в grid-структуре, это устранит немало трудностей", - говорит он.
Однако, по прогнозу Рухоламини, мы увидим приложения, умеющие работать в grid-структурах, лишь года через три.
С директором eWeek Labs Джоном Ташеком можно связаться по адресу: john_taschek@ziffdavis.com.
Сисок Top 500 Supercomputers
Органично объединив разнообразное оборудование и ПО,
можно создать суперкомпьютер, о чем говорят примеры
систем, выбранных из новейшего списка пятисот крупнейших
суперкомпьютеров мира. Исходя из своих оценок производительности,
eWeek считает, что кластер Стэнфордского университета мог
бы занять в нынешнем списке приблизительно 170-е место.